 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-centric fairness: Evaluation and optimization for resource allocation problems
Apr 29, 2025



Data-driven decision support tools play an increasingly central role in decision-making across various domains. In this work, we focus on binary classification models for predicting positive-outcome scores and deciding on resource allocation, e.g., credit scores for granting loans or churn propensity scores for targeting customers with a retention campaign. Such models may exhibit discriminatory behavior toward specific demographic groups through their predicted scores, potentially leading to unfair resource allocation. We focus on demographic parity as a fairness metric to compare the proportions of instances that are selected based on their positive outcome scores across groups. In this work, we propose a decision-centric fairness methodology that induces fairness only within the decision-making region -- the range of relevant decision thresholds on the score that may be used to decide on resource allocation -- as an alternative to a global fairness approach that seeks to enforce parity across the entire score distribution. By restricting the induction of fairness to the decision-making region, the proposed decision-centric approach avoids imposing overly restrictive constraints on the model, which may unnecessarily degrade the quality of the predicted scores. We empirically compare our approach to a global fairness approach on multiple (semi-synthetic) datasets to identify scenarios in which focusing on fairness where it truly matters, i.e., decision-centric fairness, proves beneficial.
Engineering the Law-Machine Learning Translation Problem: Developing Legally Aligned Models
Apr 23, 2025


Organizations developing machine learning-based (ML) technologies face the complex challenge of achieving high predictive performance while respecting the law. This intersection between ML and the law creates new complexities. As ML model behavior is inferred from training data, legal obligations cannot be operationalized in source code directly. Rather, legal obligations require "indirect" operationalization. However, choosing context-appropriate operationalizations presents two compounding challenges: (1) laws often permit multiple valid operationalizations for a given legal obligation-each with varying degrees of legal adequacy; and, (2) each operationalization creates unpredictable trade-offs among the different legal obligations and with predictive performance. Evaluating these trade-offs requires metrics (or heuristics), which are in turn difficult to validate against legal obligations. Current methodologies fail to fully address these interwoven challenges as they either focus on legal compliance for traditional software or on ML model development without adequately considering legal complexities. In response, we introduce a five-stage interdisciplinary framework that integrates legal and ML-technical analysis during ML model development. This framework facilitates designing ML models in a legally aligned way and identifying high-performing models that are legally justifiable. Legal reasoning guides choices for operationalizations and evaluation metrics, while ML experts ensure technical feasibility, performance optimization and an accurate interpretation of metric values. This framework bridges the gap between more conceptual analysis of law and ML models' need for deterministic specifications. We illustrate its application using a case study in the context of anti-money laundering.
Flexible Counterfactual Explanations with Generative Models
Feb 24, 2025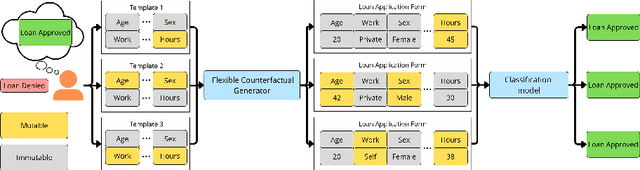
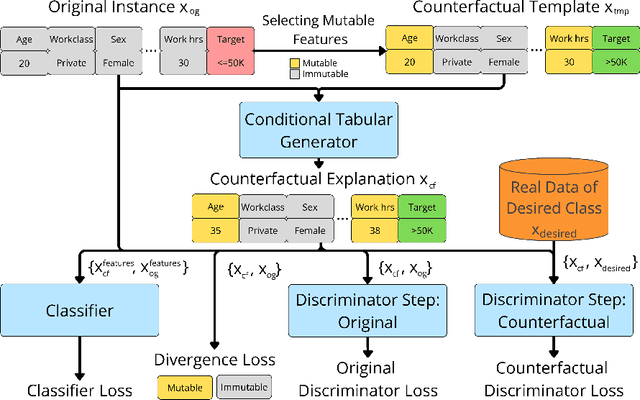
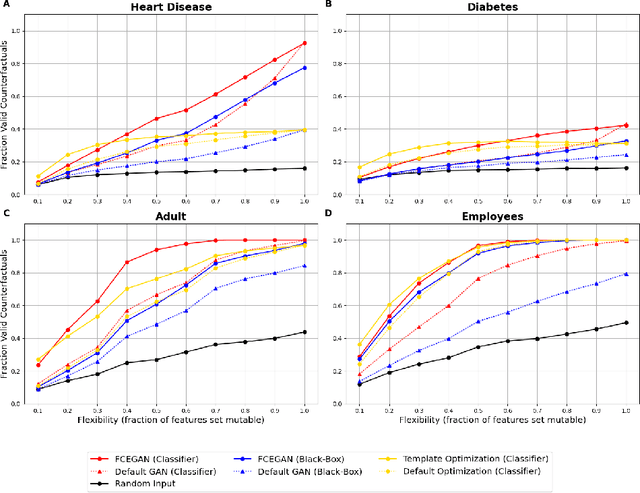
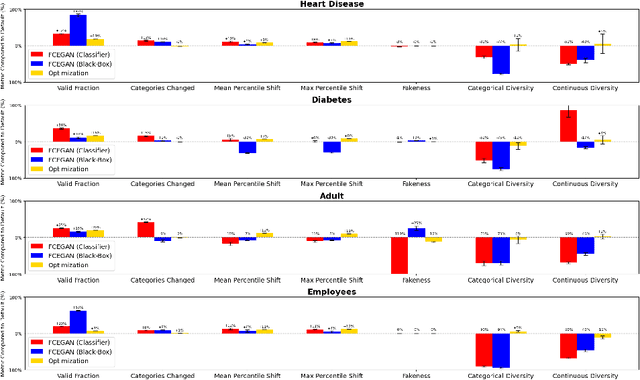
Counterfactual explanations provide actionable insights to achieve desired outcomes by suggesting minimal changes to input features. However, existing methods rely on fixed sets of mutable features, which makes counterfactual explanations inflexible for users with heterogeneous real-world constraints. Here, we introduce Flexible Counterfactual Explanations, a framework incorporating counterfactual templates, which allows users to dynamically specify mutable features at inference time. In our implementation, we use Generative Adversarial Networks (FCEGAN), which align explanations with user-defined constraints without requiring model retraining or additional optimization. Furthermore, FCEGAN is designed for black-box scenarios, leveraging historical prediction datasets to generate explanations without direct access to model internals. Experiments across economic and healthcare datasets demonstrate that FCEGAN significantly improves counterfactual explanations' validity compared to traditional benchmark methods. By integrating user-driven flexibility and black-box compatibility, counterfactual templates support personalized explanations tailored to user constraints.
A Causal Perspective on Loan Pricing: Investigating the Impacts of Selection Bias on Identifying Bid-Response Functions
Sep 07, 2023In lending, where prices are specific to both customers and products, having a well-functioning personalized pricing policy in place is essential to effective business making. Typically, such a policy must be derived from observational data, which introduces several challenges. While the problem of ``endogeneity'' is prominently studied in the established pricing literature, the problem of selection bias (or, more precisely, bid selection bias) is not. We take a step towards understanding the effects of selection bias by posing pricing as a problem of causal inference. Specifically, we consider the reaction of a customer to price a treatment effect. In our experiments, we simulate varying levels of selection bias on a semi-synthetic dataset on mortgage loan applications in Belgium. We investigate the potential of parametric and nonparametric methods for the identification of individual bid-response functions. Our results illustrate how conventional methods such as logistic regression and neural networks suffer adversely from selection bias. In contrast, we implement state-of-the-art methods from causal machine learning and show their capability to overcome selection bias in pricing data.
Sample-Level Weighting for Multi-Task Learning with Auxiliary Tasks
Jun 07, 2023Multi-task learning (MTL) can improve the generalization performance of neural networks by sharing representations with related tasks. Nonetheless, MTL can also degrade performance through harmful interference between tasks. Recent work has pursued task-specific loss weighting as a solution for this interference. However, existing algorithms treat tasks as atomic, lacking the ability to explicitly separate harmful and helpful signals beyond the task level. To this end, we propose SLGrad, a sample-level weighting algorithm for multi-task learning with auxiliary tasks. Through sample-specific task weights, SLGrad reshapes the task distributions during training to eliminate harmful auxiliary signals and augment useful task signals. Substantial generalization performance gains are observed on (semi-) synthetic datasets and common supervised multi-task problems.
HydaLearn: Highly Dynamic Task Weighting for Multi-task Learning with Auxiliary Tasks
Aug 26, 2020



Multi-task learning (MTL) can improve performance on a task by sharing representations with one or more related auxiliary-tasks. Usually, MTL-networks are trained on a composite loss function formed by a constant weighted combination of the separate task losses. In practice, constant loss weights lead to poor results for two reasons: (i) the relevance of the auxiliary tasks can gradually drift throughout the learning process; (ii) for mini-batch based optimisation, the optimal task weights vary significantly from one update to the next depending on mini-batch sample composition. We introduce HydaLearn, an intelligent weighting algorithm that connects main-task gain to the individual task gradients, in order to inform dynamic loss weighting at the mini-batch level, addressing i and ii. Using HydaLearn, we report performance increases on synthetic data, as well as on two supervised learning domains.
Autoencoders for strategic decision support
May 03, 2020



In the majority of executive domains, a notion of normality is involved in most strategic decisions. However, few data-driven tools that support strategic decision-making are available. We introduce and extend the use of autoencoders to provide strategically relevant granular feedback. A first experiment indicates that experts are inconsistent in their decision making, highlighting the need for strategic decision support. Furthermore, using two large industry-provided human resources datasets, the proposed solution is evaluated in terms of ranking accuracy, synergy with human experts, and dimension-level feedback. This three-point scheme is validated using (a) synthetic data, (b) the perspective of data quality, (c) blind expert validation, and (d) transparent expert evaluation. Our study confirms several principal weaknesses of human decision-making and stresses the importance of synergy between a model and humans. Moreover, unsupervised learning and in particular the autoencoder are shown to be valuable tools for strategic decision-making.
Optimising Individual-Treatment-Effect Using Bandits
Oct 16, 2019


Applying causal inference models in areas such as economics, healthcare and marketing receives great interest from the machine learning community. In particular, estimating the individual-treatment-effect (ITE) in settings such as precision medicine and targeted advertising has peaked in application. Optimising this ITE under the strong-ignorability-assumption -- meaning all confounders expressing influence on the outcome of a treatment are registered in the data -- is often referred to as uplift modeling (UM). While these techniques have proven useful in many settings, they suffer vividly in a dynamic environment due to concept drift. Take for example the negative influence on a marketing campaign when a competitor product is released. To counter this, we propose the uplifted contextual multi-armed bandit (U-CMAB), a novel approach to optimise the ITE by drawing upon bandit literature. Experiments on real and simulated data indicate that our proposed approach compares favourably against the state-of-the-art. All our code can be found online at https://github.com/vub-dl/u-cmab.