 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-Loop LLM Grading for Handwritten Mathematics Assessments
Mar 13, 2026Providing timely and individualised feedback on handwritten student work is highly beneficial for learning but difficult to achieve at scale. This challenge has become more pressing as generative AI undermines the reliability of take-home assessments, shifting emphasis toward supervised, in-class evaluation. We present a scalable, end-to-end workflow for LLM-assisted grading of short, pen-and-paper assessments. The workflow spans (1) constructing solution keys, (2) developing detailed rubric-style grading keys used to guide the LLM, and (3) a grading procedure that combines automated scanning and anonymisation, multi-pass LLM scoring, automated consistency checks, and mandatory human verification. We deploy the system in two undergraduate mathematics courses using six low-stakes in-class tests. Empirically, LLM assistance reduces grading time by approximately 23% while achieving agreement comparable to, and in several cases tighter than, fully manual grading. Occasional model errors occur but are effectively contained by the hybrid design. Overall, our results show that carefully embedded human-in-the-loop LLM grading can substantially reduce workload while maintaining fairness and accuracy.
Scalable Classification of Course Information Sheets Using Large Language Models: A Reusable Institutional Method for Academic Quality Assurance
Mar 13, 2026Purpose: Higher education institutions face increasing pressure to audit course designs for generative AI (GenAI) integration. This paper presents an end-to-end method for using large language models (LLMs) to scan course information sheets at scale, identify where assessments may be vulnerable to student use of GenAI tools, validate system performance through iterative refinement, and operationalise results through direct stakeholder communication and effort. Method: We developed a four-phase pipeline: (0) manual pilot sampling, (1) iterative prompt engineering with multi-model comparison, (2) full production scan of 4,684 Bachelor and Master course information sheets (Academic Year 2024-2025) from the Vrije Universiteit Brussel (VUB) with automated report generation and email distribution to teaching teams (91.4% address-matched) using a three-tier risk taxonomy (Clear risk, Potential risk, Low risk), and (3) longitudinal re-scan of 4,675 sheets after the next catalogue release. Results: Five iterations of prompt refinement achieved 87% agreement with expert labels. GPT-4o was selected for production based on superior handling of ambiguous cases involving internships and practical components. The Year 1 scan classified 60.3% of courses as Clear risk, 15.2% as Potential risk, and 24.5% as Low risk. Year 2 comparison revealed substantial shifts in risk distributions, with improvements most pronounced in practice-oriented programmes. Implications: The method enables institutions to rapidly transform heterogeneous catalogue data into structured and actionable intelligence. The approach is transferable to other audit domains (sustainability, accessibility, pedagogical alignment) and provides a template for responsible LLM deployment in higher education governance.
Early Evidence of Vibe-Proving with Consumer LLMs: A Case Study on Spectral Region Characterization with ChatGPT-5.2 (Thinking)
Feb 21, 2026Large Language Models (LLMs) are increasingly used as scientific copilots, but evidence on their role in research-level mathematics remains limited, especially for workflows accessible to individual researchers. We present early evidence for vibe-proving with a consumer subscription LLM through an auditable case study that resolves Conjecture 20 of Ran and Teng (2024) on the exact nonreal spectral region of a 4-cycle row-stochastic nonnegative matrix family. We analyze seven shareable ChatGPT-5.2 (Thinking) threads and four versioned proof drafts, documenting an iterative pipeline of generate, referee, and repair. The model is most useful for high-level proof search, while human experts remain essential for correctness-critical closure. The final theorem provides necessary and sufficient region conditions and explicit boundary attainment constructions. Beyond the mathematical result, we contribute a process-level characterization of where LLM assistance materially helps and where verification bottlenecks persist, with implications for evaluation of AI-assisted research workflows and for designing human-in-the-loop theorem proving systems.
Probing the Trajectories of Reasoning Traces in Large Language Models
Jan 30, 2026Large language models (LLMs) increasingly solve difficult problems by producing "reasoning traces" before emitting a final response. However, it remains unclear how accuracy and decision commitment evolve along a reasoning trajectory, and whether intermediate trace segments provide answer-relevant information beyond generic length or stylistic effects. Here, we propose a protocol to systematically probe the trajectories of reasoning traces in LLMs by 1) generating a model's reasoning trace, 2) truncating it at fixed token-percentiles, and 3) injecting each partial trace back into the model (or a different model) to measure the induced distribution over answer choices via next-token probabilities. We apply this protocol to the open-source Qwen3-4B/-8B/-14B and gpt-oss-20b/-120b models across the multiple-choice GPQA Diamond and MMLU-Pro benchmarks. We find that accuracy and decision commitment consistently increase as the percentage of provided reasoning tokens grows. These gains are primarily driven by relevant content in the model generation rather than context length or generic "reasoning style" effects. Stronger models often backtrack successfully from incorrect partial traces, but immediate answers often remain anchored in the weaker model's incorrect response. More broadly, we show that trajectory probing provides diagnostics for efficient and safer deployment of reasoning models as the measurements can inform practical trace-handling and monitoring policies that improve reliability without assuming intermediate tokens are inherently faithful explanations.
Structurally Human, Semantically Biased: Detecting LLM-Generated References with Embeddings and GNNs
Jan 28, 2026Large language models are increasingly used to curate bibliographies, raising the question: are their reference lists distinguishable from human ones? We build paired citation graphs, ground truth and GPT-4o-generated (from parametric knowledge), for 10,000 focal papers ($\approx$ 275k references) from SciSciNet, and added a field-matched random baseline that preserves out-degree and field distributions while breaking latent structure. We compare (i) structure-only node features (degree/closeness/eigenvector centrality, clustering, edge count) with (ii) 3072-D title/abstract embeddings, using an RF on graph-level aggregates and Graph Neural Networks with node features. Structure alone barely separates GPT from ground truth (RF accuracy $\approx$ 0.60) despite cleanly rejecting the random baseline ($\approx$ 0.89--0.92). By contrast, embeddings sharply increase separability: RF on aggregated embeddings reaches $\approx$ 0.83, and GNNs with embedding node features achieve 93\% test accuracy on GPT vs.\ ground truth. We show the robustness of our findings by replicating the pipeline with Claude Sonnet 4.5 and with multiple embedding models (OpenAI and SPECTER), with RF separability for ground truth vs.\ Claude $\approx 0.77$ and clean rejection of the random baseline. Thus, LLM bibliographies, generated purely from parametric knowledge, closely mimic human citation topology, but leave detectable semantic fingerprints; detection and debiasing should target content signals rather than global graph structure.
Benchmarks Saturate When The Model Gets Smarter Than The Judge
Jan 27, 2026Benchmarks are important tools to track progress in the development of Large Language Models (LLMs), yet inaccuracies in datasets and evaluation methods consistently undermine their effectiveness. Here, we present Omni-MATH-2, a manually revised version of the Omni-MATH dataset comprising a clean, exact-answer subset ($n{=}4181$) and a tagged, non-standard subset ($n{=}247$). Each problem was audited to ensure LaTeX compilability, solvability and verifiability, which involved adding missing figures or information, labeling problems requiring a proof, estimation or image, and removing clutter. This process significantly reduces dataset-induced noise, thereby providing a more precise assessment of model performance. The annotated dataset also allows us to evaluate judge-induced noise by comparing GPT-5 mini with the original Omni-Judge, revealing substantial discrepancies between judges on both the clean and tagged problem subsets. Expert annotations reveal that Omni-Judge is wrong in $96.4\%$ of the judge disagreements, indicating its inability to differentiate between models' abilities, even well before saturation of the benchmark occurs. As problems become more challenging, we find that increasingly competent judges become essential in order to prevent judge errors from masking genuine differences between models. Finally, neither judge identifies the present failure modes for the subset of tagged problems, demonstrating that dataset quality and judge reliability are both critical to develop accurate benchmarks of model performance.
Estimating problem difficulty without ground truth using Large Language Model comparisons
Dec 16, 2025Recent advances in the finetuning of large language models (LLMs) have significantly improved their performance on established benchmarks, emphasizing the need for increasingly difficult, synthetic data. A key step in this data generation pipeline is a method for estimating problem difficulty. Current approaches, such as human calibration or performance-based scoring, fail to generalize to out-of-distribution problems, i.e. problems currently unsolvable by humans and LLMs, because they are not scalable, time-consuming, and ground truth dependent. Therefore, we propose a new method for estimating problem difficulty, LLM compare, that addresses these limitations. An LLM performs pairwise difficulty comparisons, and then Bradley-Terry scores are computed based on the outcomes. To validate our method, we first propose a conceptual framework that positions existing approaches on three orthogonal planes--construction, scale and dependence--identifying which quadrants a measure needs to occupy to score out-of-distribution problems. LLM compare naturally occupies all desirable quadrants as the first measure that is continuous and dynamic, model-agnostic and independent of ground truth information. As a second validation, we show that LLM compare demonstrates strong alignment with human annotations: Pearson $r \geq 0.80$ for $n=1876$. Thirdly, we show that LLM compare is robust to hallucinations, with less than $6\%$ degradation in Pearson correlation for $10\%$ noise injection. Our work represents a significant step towards replacing time-consuming human annotations and synthetic data generation, and will be an important driver for curriculum design, model evaluation, and AI-assisted research ideation.
Decision-centric fairness: Evaluation and optimization for resource allocation problems
Apr 29, 2025



Data-driven decision support tools play an increasingly central role in decision-making across various domains. In this work, we focus on binary classification models for predicting positive-outcome scores and deciding on resource allocation, e.g., credit scores for granting loans or churn propensity scores for targeting customers with a retention campaign. Such models may exhibit discriminatory behavior toward specific demographic groups through their predicted scores, potentially leading to unfair resource allocation. We focus on demographic parity as a fairness metric to compare the proportions of instances that are selected based on their positive outcome scores across groups. In this work, we propose a decision-centric fairness methodology that induces fairness only within the decision-making region -- the range of relevant decision thresholds on the score that may be used to decide on resource allocation -- as an alternative to a global fairness approach that seeks to enforce parity across the entire score distribution. By restricting the induction of fairness to the decision-making region, the proposed decision-centric approach avoids imposing overly restrictive constraints on the model, which may unnecessarily degrade the quality of the predicted scores. We empirically compare our approach to a global fairness approach on multiple (semi-synthetic) datasets to identify scenarios in which focusing on fairness where it truly matters, i.e., decision-centric fairness, proves beneficial.
How Deep Do Large Language Models Internalize Scientific Literature and Citation Practices?
Apr 03, 2025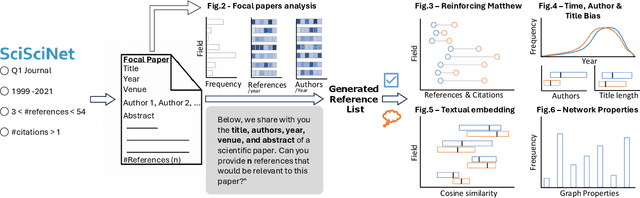
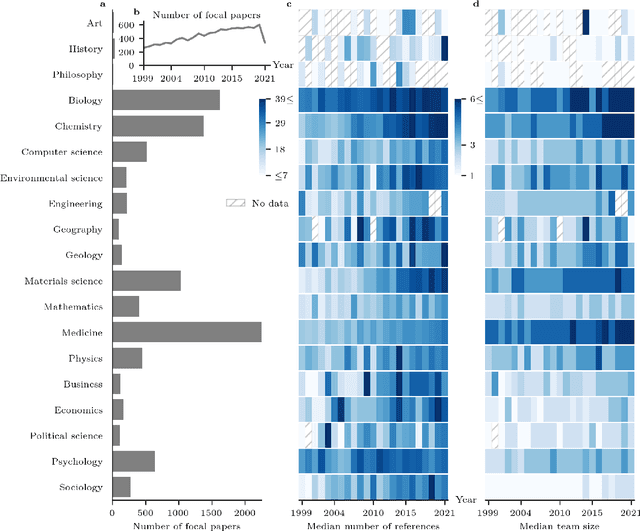
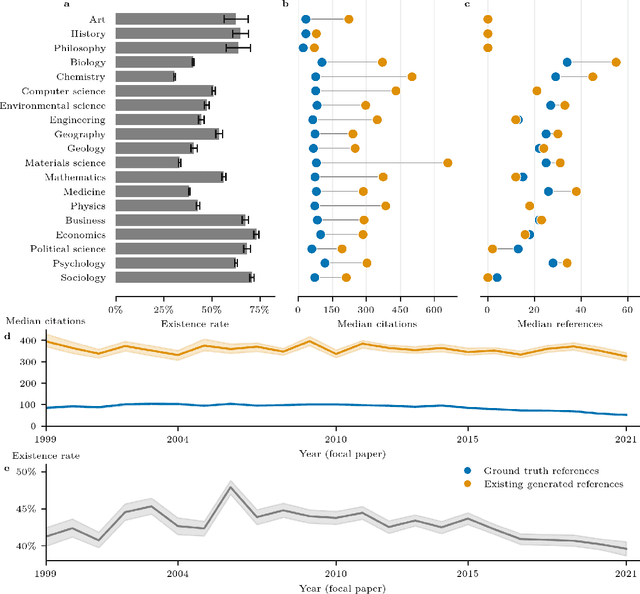
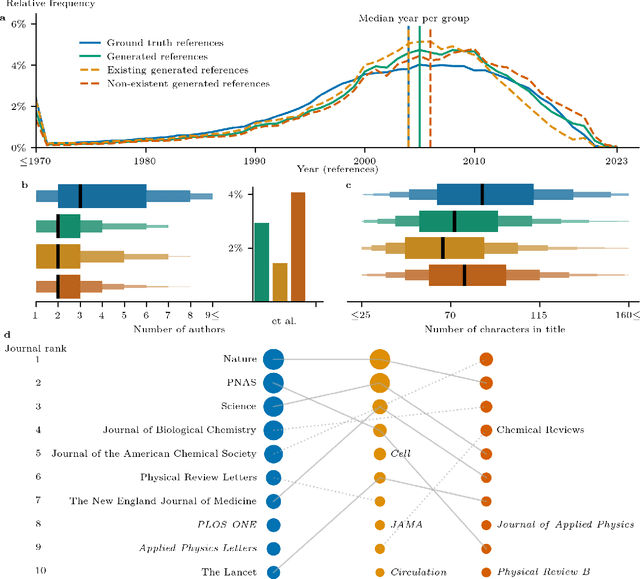
The spread of scientific knowledge depends on how researchers discover and cite previous work. The adoption of large language models (LLMs) in the scientific research process introduces a new layer to these citation practices. However, it remains unclear to what extent LLMs align with human citation practices, how they perform across domains, and may influence citation dynamics. Here, we show that LLMs systematically reinforce the Matthew effect in citations by consistently favoring highly cited papers when generating references. This pattern persists across scientific domains despite significant field-specific variations in existence rates, which refer to the proportion of generated references that match existing records in external bibliometric databases. Analyzing 274,951 references generated by GPT-4o for 10,000 papers, we find that LLM recommendations diverge from traditional citation patterns by preferring more recent references with shorter titles and fewer authors. Emphasizing their content-level relevance, the generated references are semantically aligned with the content of each paper at levels comparable to the ground truth references and display similar network effects while reducing author self-citations. These findings illustrate how LLMs may reshape citation practices and influence the trajectory of scientific discovery by reflecting and amplifying established trends. As LLMs become more integrated into the scientific research process, it is important to understand their role in shaping how scientific communities discover and build upon prior work.
Flexible Counterfactual Explanations with Generative Models
Feb 24, 2025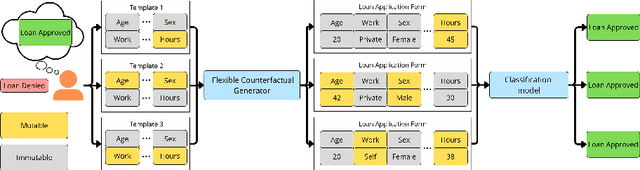
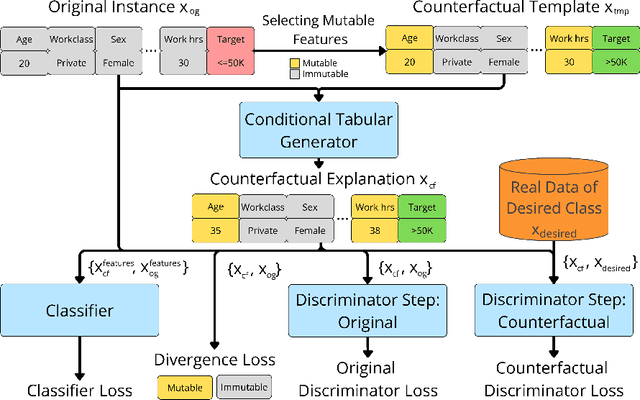
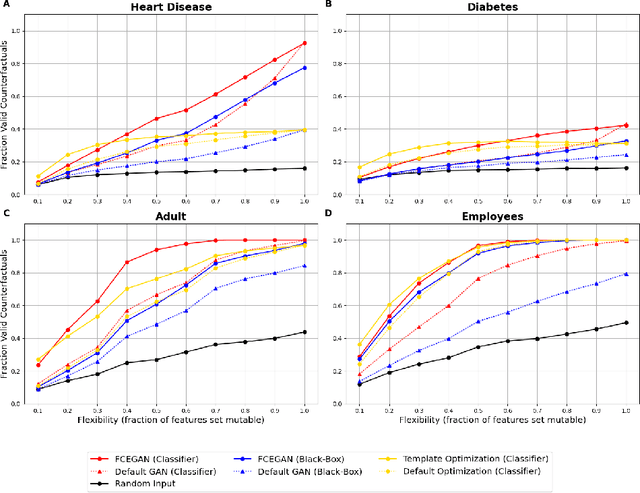
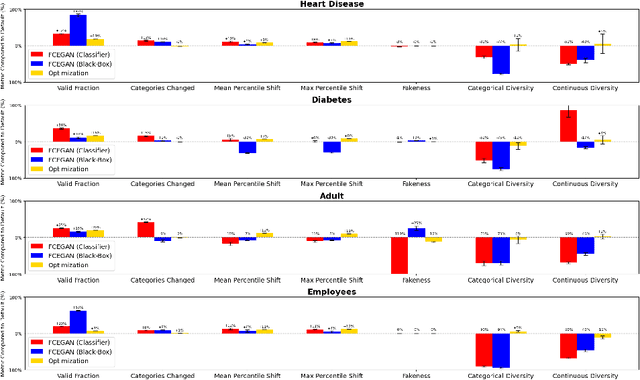
Counterfactual explanations provide actionable insights to achieve desired outcomes by suggesting minimal changes to input features. However, existing methods rely on fixed sets of mutable features, which makes counterfactual explanations inflexible for users with heterogeneous real-world constraints. Here, we introduce Flexible Counterfactual Explanations, a framework incorporating counterfactual templates, which allows users to dynamically specify mutable features at inference time. In our implementation, we use Generative Adversarial Networks (FCEGAN), which align explanations with user-defined constraints without requiring model retraining or additional optimization. Furthermore, FCEGAN is designed for black-box scenarios, leveraging historical prediction datasets to generate explanations without direct access to model internals. Experiments across economic and healthcare datasets demonstrate that FCEGAN significantly improves counterfactual explanations' validity compared to traditional benchmark methods. By integrating user-driven flexibility and black-box compatibility, counterfactual templates support personalized explanations tailored to user constraints.