 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Deep Do Large Language Models Internalize Scientific Literature and Citation Practices?
Apr 03, 2025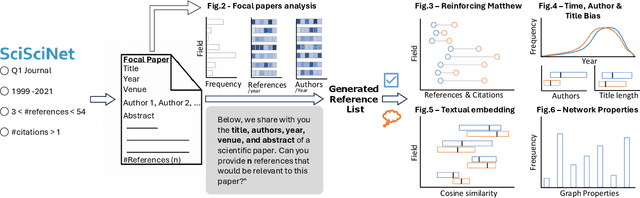
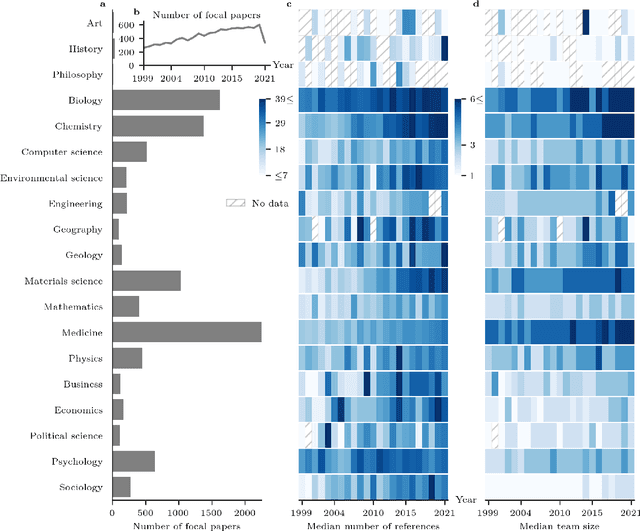
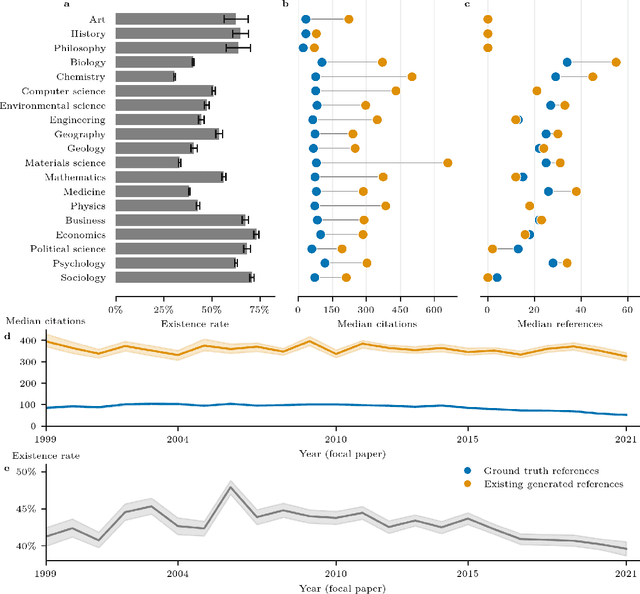
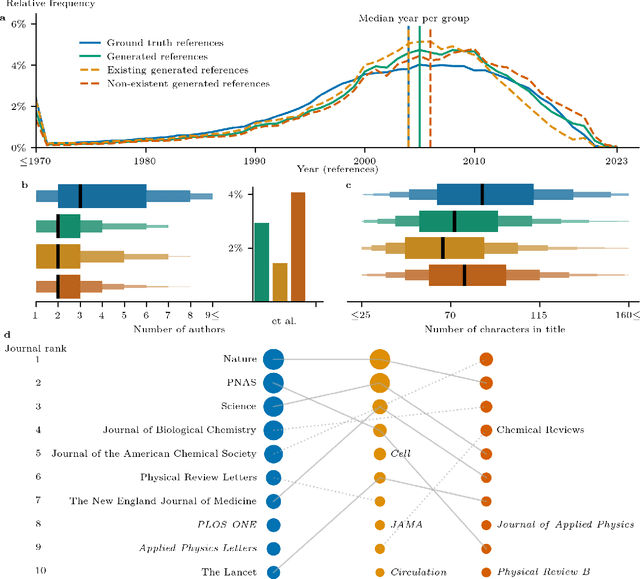
The spread of scientific knowledge depends on how researchers discover and cite previous work. The adoption of large language models (LLMs) in the scientific research process introduces a new layer to these citation practices. However, it remains unclear to what extent LLMs align with human citation practices, how they perform across domains, and may influence citation dynamics. Here, we show that LLMs systematically reinforce the Matthew effect in citations by consistently favoring highly cited papers when generating references. This pattern persists across scientific domains despite significant field-specific variations in existence rates, which refer to the proportion of generated references that match existing records in external bibliometric databases. Analyzing 274,951 references generated by GPT-4o for 10,000 papers, we find that LLM recommendations diverge from traditional citation patterns by preferring more recent references with shorter titles and fewer authors. Emphasizing their content-level relevance, the generated references are semantically aligned with the content of each paper at levels comparable to the ground truth references and display similar network effects while reducing author self-citations. These findings illustrate how LLMs may reshape citation practices and influence the trajectory of scientific discovery by reflecting and amplifying established trends. As LLMs become more integrated into the scientific research process, it is important to understand their role in shaping how scientific communities discover and build upon prior work.
Large Language Models Reflect Human Citation Patterns with a Heightened Citation Bias
May 29, 2024Citation practices are crucial in shaping the structure of scientific knowledge, yet they are often influenced by contemporary norms and biases. The emergence of Large Language Models (LLMs) like GPT-4 introduces a new dynamic to these practices. Interestingly, the characteristics and potential biases of references recommended by LLMs that entirely rely on their parametric knowledge, and not on search or retrieval-augmented generation, remain unexplored. Here, we analyze these characteristics in an experiment using a dataset of 166 papers from AAAI, NeurIPS, ICML, and ICLR, published after GPT-4's knowledge cut-off date, encompassing 3,066 references in total. In our experiment, GPT-4 was tasked with suggesting scholarly references for the anonymized in-text citations within these papers. Our findings reveal a remarkable similarity between human and LLM citation patterns, but with a more pronounced high citation bias in GPT-4, which persists even after controlling for publication year, title length, number of authors, and venue. Additionally, we observe a large consistency between the characteristics of GPT-4's existing and non-existent generated references, indicating the model's internalization of citation patterns. By analyzing citation graphs, we show that the references recommended by GPT-4 are embedded in the relevant citation context, suggesting an even deeper conceptual internalization of the citation networks. While LLMs can aid in citation generation, they may also amplify existing biases and introduce new ones, potentially skewing scientific knowledge dissemination. Our results underscore the need for identifying the model's biases and for developing balanced methods to interact with LLMs in general.
Degrees of riskiness, falsifiability, and truthlikeness. A neo-Popperian account applicable to probabilistic theories
Jul 08, 2021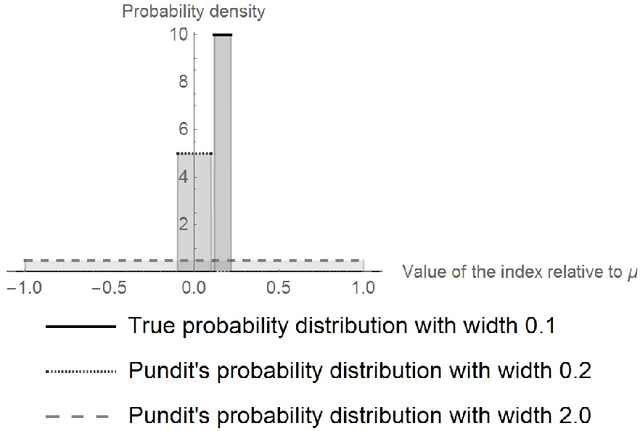
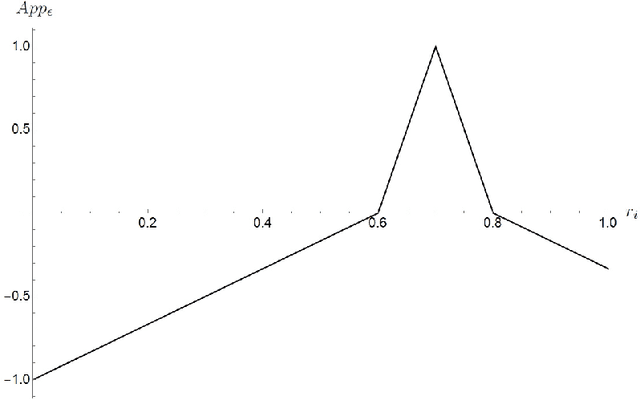
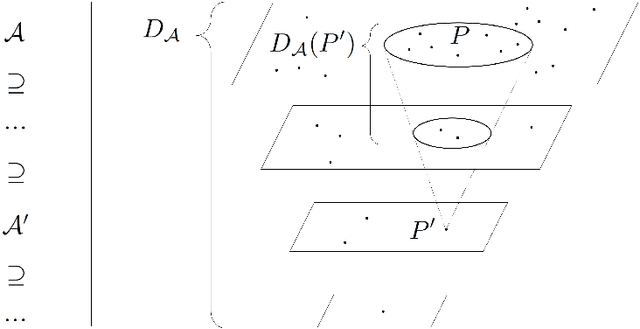
In this paper, we take a fresh look at three Popperian concepts: riskiness, falsifiability, and truthlikeness (or verisimilitude) of scientific hypotheses or theories. First, we make explicit the dimensions that underlie the notion of riskiness. Secondly, we examine if and how degrees of falsifiability can be defined, and how they are related to various dimensions of the concept of riskiness as well as the experimental context. Thirdly, we consider the relation of riskiness to (expected degrees of) truthlikeness. Throughout, we pay special attention to probabilistic theories and we offer a tentative, quantitative account of verisimilitude for probabilistic theories.