 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructurally Human, Semantically Biased: Detecting LLM-Generated References with Embeddings and GNNs
Jan 28, 2026Large language models are increasingly used to curate bibliographies, raising the question: are their reference lists distinguishable from human ones? We build paired citation graphs, ground truth and GPT-4o-generated (from parametric knowledge), for 10,000 focal papers ($\approx$ 275k references) from SciSciNet, and added a field-matched random baseline that preserves out-degree and field distributions while breaking latent structure. We compare (i) structure-only node features (degree/closeness/eigenvector centrality, clustering, edge count) with (ii) 3072-D title/abstract embeddings, using an RF on graph-level aggregates and Graph Neural Networks with node features. Structure alone barely separates GPT from ground truth (RF accuracy $\approx$ 0.60) despite cleanly rejecting the random baseline ($\approx$ 0.89--0.92). By contrast, embeddings sharply increase separability: RF on aggregated embeddings reaches $\approx$ 0.83, and GNNs with embedding node features achieve 93\% test accuracy on GPT vs.\ ground truth. We show the robustness of our findings by replicating the pipeline with Claude Sonnet 4.5 and with multiple embedding models (OpenAI and SPECTER), with RF separability for ground truth vs.\ Claude $\approx 0.77$ and clean rejection of the random baseline. Thus, LLM bibliographies, generated purely from parametric knowledge, closely mimic human citation topology, but leave detectable semantic fingerprints; detection and debiasing should target content signals rather than global graph structure.
How Deep Do Large Language Models Internalize Scientific Literature and Citation Practices?
Apr 03, 2025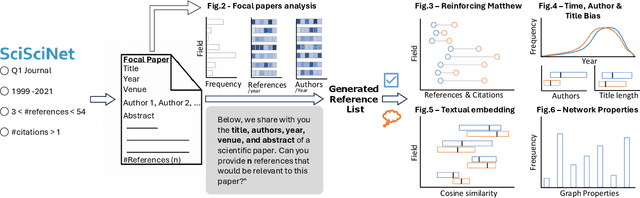
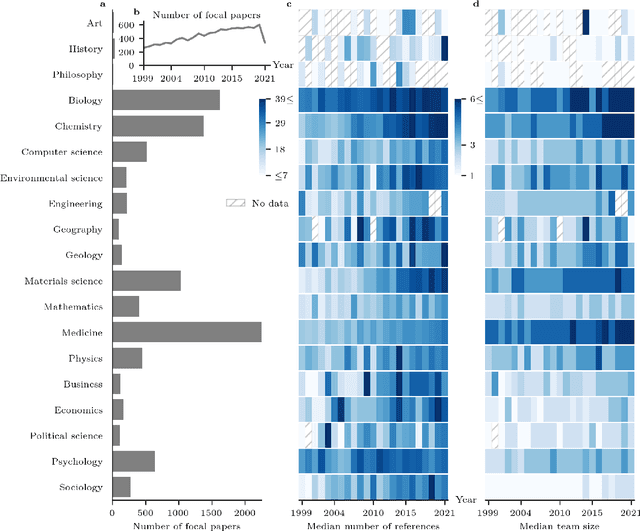
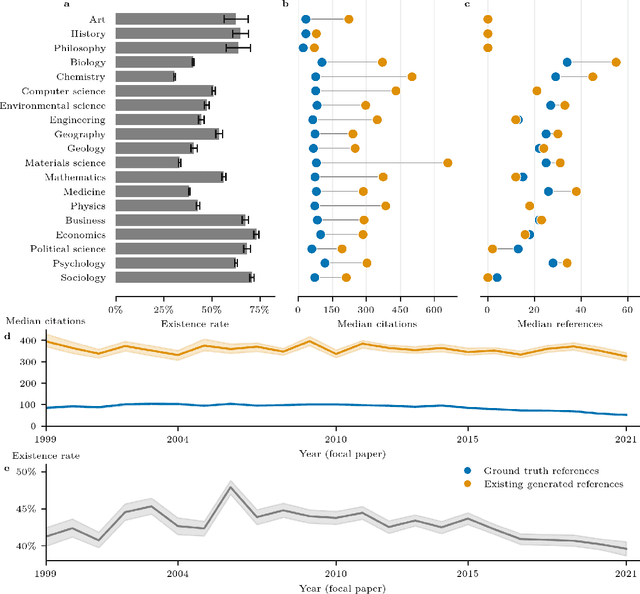
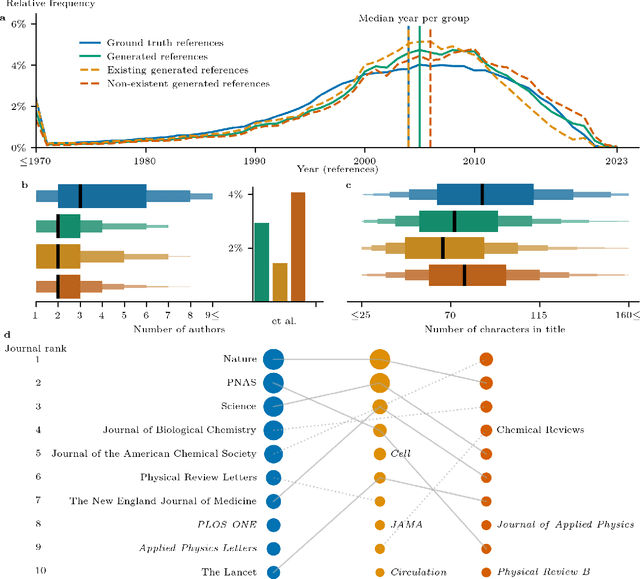
The spread of scientific knowledge depends on how researchers discover and cite previous work. The adoption of large language models (LLMs) in the scientific research process introduces a new layer to these citation practices. However, it remains unclear to what extent LLMs align with human citation practices, how they perform across domains, and may influence citation dynamics. Here, we show that LLMs systematically reinforce the Matthew effect in citations by consistently favoring highly cited papers when generating references. This pattern persists across scientific domains despite significant field-specific variations in existence rates, which refer to the proportion of generated references that match existing records in external bibliometric databases. Analyzing 274,951 references generated by GPT-4o for 10,000 papers, we find that LLM recommendations diverge from traditional citation patterns by preferring more recent references with shorter titles and fewer authors. Emphasizing their content-level relevance, the generated references are semantically aligned with the content of each paper at levels comparable to the ground truth references and display similar network effects while reducing author self-citations. These findings illustrate how LLMs may reshape citation practices and influence the trajectory of scientific discovery by reflecting and amplifying established trends. As LLMs become more integrated into the scientific research process, it is important to understand their role in shaping how scientific communities discover and build upon prior work.
The Effectiveness of Curvature-Based Rewiring and the Role of Hyperparameters in GNNs Revisited
Jul 12, 2024Message passing is the dominant paradigm in Graph Neural Networks (GNNs). The efficiency of message passing, however, can be limited by the topology of the graph. This happens when information is lost during propagation due to being oversquashed when travelling through bottlenecks. To remedy this, recent efforts have focused on graph rewiring techniques, which disconnect the input graph originating from the data and the computational graph, on which message passing is performed. A prominent approach for this is to use discrete graph curvature measures, of which several variants have been proposed, to identify and rewire around bottlenecks, facilitating information propagation. While oversquashing has been demonstrated in synthetic datasets, in this work we reevaluate the performance gains that curvature-based rewiring brings to real-world datasets. We show that in these datasets, edges selected during the rewiring process are not in line with theoretical criteria identifying bottlenecks. This implies they do not necessarily oversquash information during message passing. Subsequently, we demonstrate that SOTA accuracies on these datasets are outliers originating from sweeps of hyperparameters -- both the ones for training and dedicated ones related to the rewiring algorithm -- instead of consistent performance gains. In conclusion, our analysis nuances the effectiveness of curvature-based rewiring in real-world datasets and brings a new perspective on the methods to evaluate GNN accuracy improvements.
Large Language Models Reflect Human Citation Patterns with a Heightened Citation Bias
May 29, 2024Citation practices are crucial in shaping the structure of scientific knowledge, yet they are often influenced by contemporary norms and biases. The emergence of Large Language Models (LLMs) like GPT-4 introduces a new dynamic to these practices. Interestingly, the characteristics and potential biases of references recommended by LLMs that entirely rely on their parametric knowledge, and not on search or retrieval-augmented generation, remain unexplored. Here, we analyze these characteristics in an experiment using a dataset of 166 papers from AAAI, NeurIPS, ICML, and ICLR, published after GPT-4's knowledge cut-off date, encompassing 3,066 references in total. In our experiment, GPT-4 was tasked with suggesting scholarly references for the anonymized in-text citations within these papers. Our findings reveal a remarkable similarity between human and LLM citation patterns, but with a more pronounced high citation bias in GPT-4, which persists even after controlling for publication year, title length, number of authors, and venue. Additionally, we observe a large consistency between the characteristics of GPT-4's existing and non-existent generated references, indicating the model's internalization of citation patterns. By analyzing citation graphs, we show that the references recommended by GPT-4 are embedded in the relevant citation context, suggesting an even deeper conceptual internalization of the citation networks. While LLMs can aid in citation generation, they may also amplify existing biases and introduce new ones, potentially skewing scientific knowledge dissemination. Our results underscore the need for identifying the model's biases and for developing balanced methods to interact with LLMs in general.