 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructurally Human, Semantically Biased: Detecting LLM-Generated References with Embeddings and GNNs
Jan 28, 2026Large language models are increasingly used to curate bibliographies, raising the question: are their reference lists distinguishable from human ones? We build paired citation graphs, ground truth and GPT-4o-generated (from parametric knowledge), for 10,000 focal papers ($\approx$ 275k references) from SciSciNet, and added a field-matched random baseline that preserves out-degree and field distributions while breaking latent structure. We compare (i) structure-only node features (degree/closeness/eigenvector centrality, clustering, edge count) with (ii) 3072-D title/abstract embeddings, using an RF on graph-level aggregates and Graph Neural Networks with node features. Structure alone barely separates GPT from ground truth (RF accuracy $\approx$ 0.60) despite cleanly rejecting the random baseline ($\approx$ 0.89--0.92). By contrast, embeddings sharply increase separability: RF on aggregated embeddings reaches $\approx$ 0.83, and GNNs with embedding node features achieve 93\% test accuracy on GPT vs.\ ground truth. We show the robustness of our findings by replicating the pipeline with Claude Sonnet 4.5 and with multiple embedding models (OpenAI and SPECTER), with RF separability for ground truth vs.\ Claude $\approx 0.77$ and clean rejection of the random baseline. Thus, LLM bibliographies, generated purely from parametric knowledge, closely mimic human citation topology, but leave detectable semantic fingerprints; detection and debiasing should target content signals rather than global graph structure.
How Deep Do Large Language Models Internalize Scientific Literature and Citation Practices?
Apr 03, 2025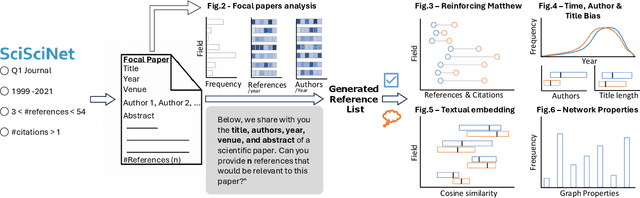
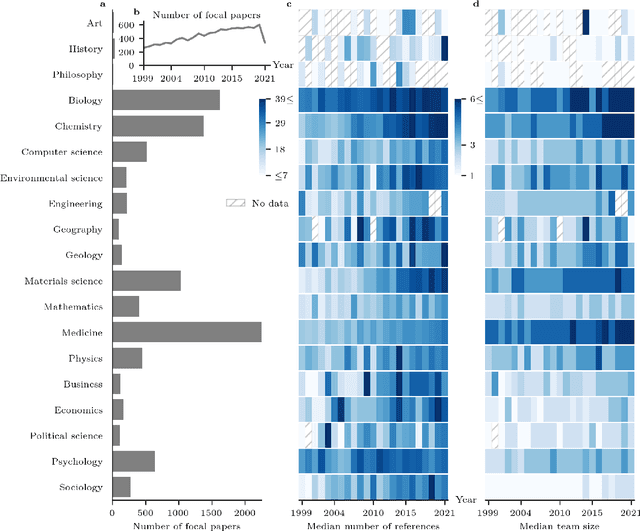
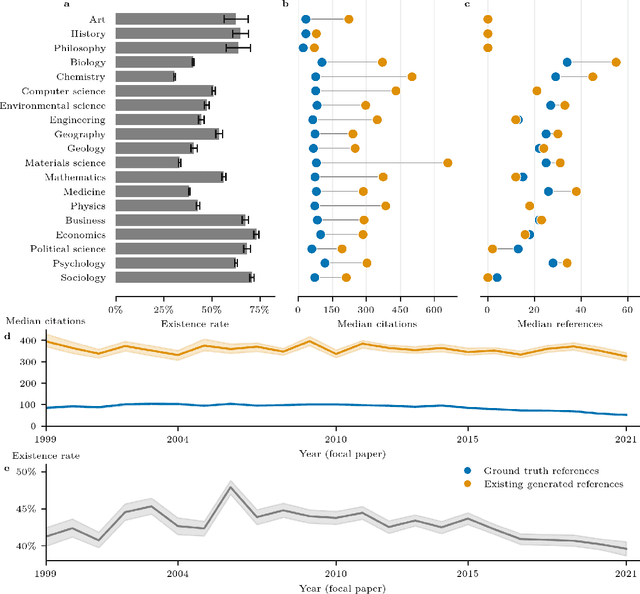
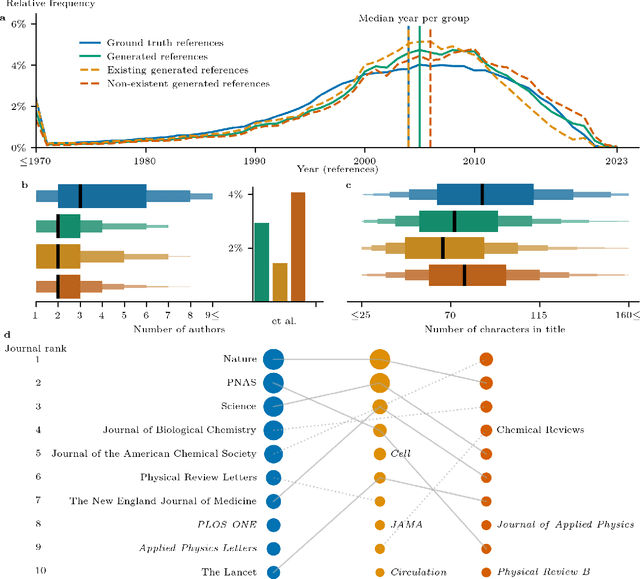
The spread of scientific knowledge depends on how researchers discover and cite previous work. The adoption of large language models (LLMs) in the scientific research process introduces a new layer to these citation practices. However, it remains unclear to what extent LLMs align with human citation practices, how they perform across domains, and may influence citation dynamics. Here, we show that LLMs systematically reinforce the Matthew effect in citations by consistently favoring highly cited papers when generating references. This pattern persists across scientific domains despite significant field-specific variations in existence rates, which refer to the proportion of generated references that match existing records in external bibliometric databases. Analyzing 274,951 references generated by GPT-4o for 10,000 papers, we find that LLM recommendations diverge from traditional citation patterns by preferring more recent references with shorter titles and fewer authors. Emphasizing their content-level relevance, the generated references are semantically aligned with the content of each paper at levels comparable to the ground truth references and display similar network effects while reducing author self-citations. These findings illustrate how LLMs may reshape citation practices and influence the trajectory of scientific discovery by reflecting and amplifying established trends. As LLMs become more integrated into the scientific research process, it is important to understand their role in shaping how scientific communities discover and build upon prior work.