 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUCID-GAN: Conditional Generative Models to Locate Unfairness
Jul 28, 2023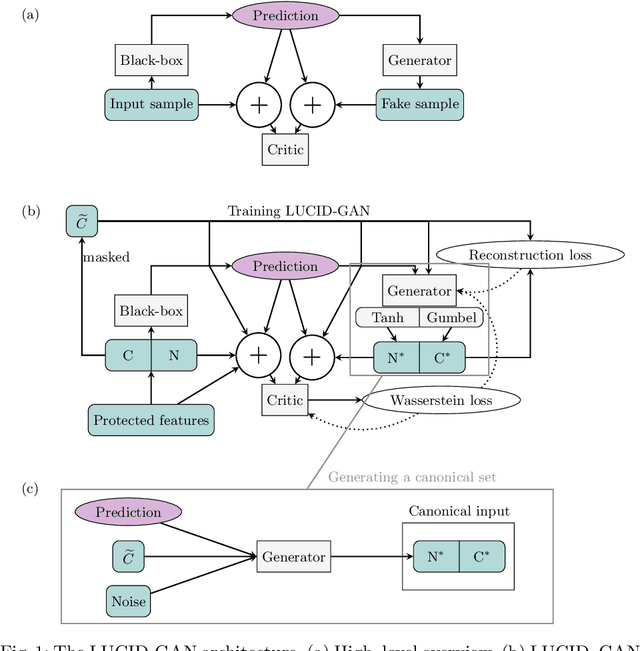
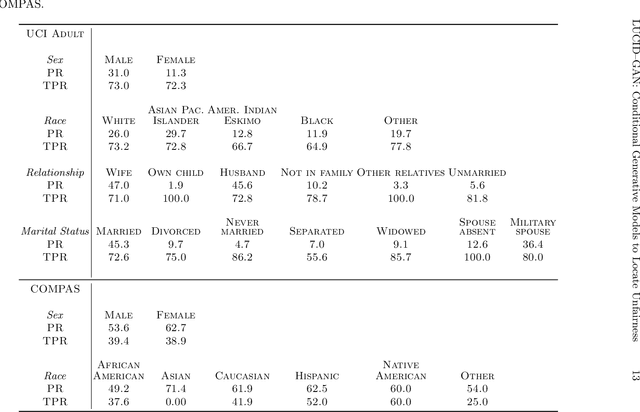
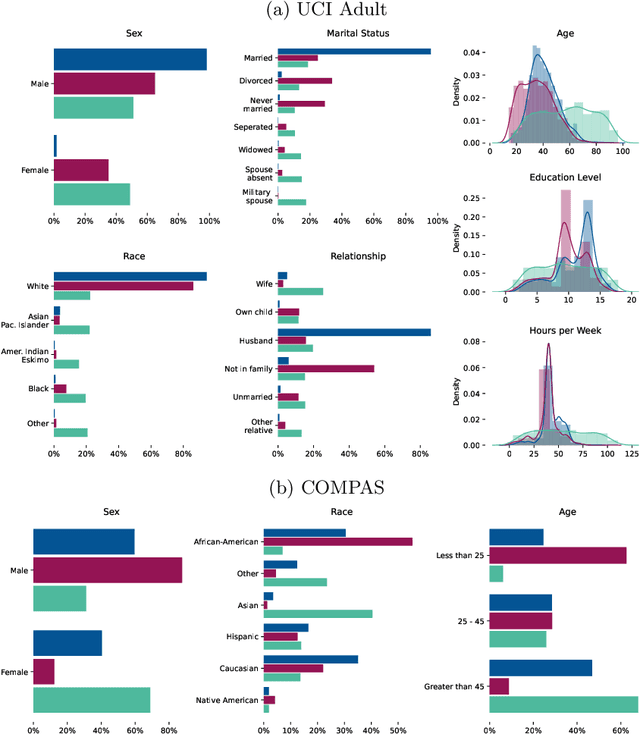
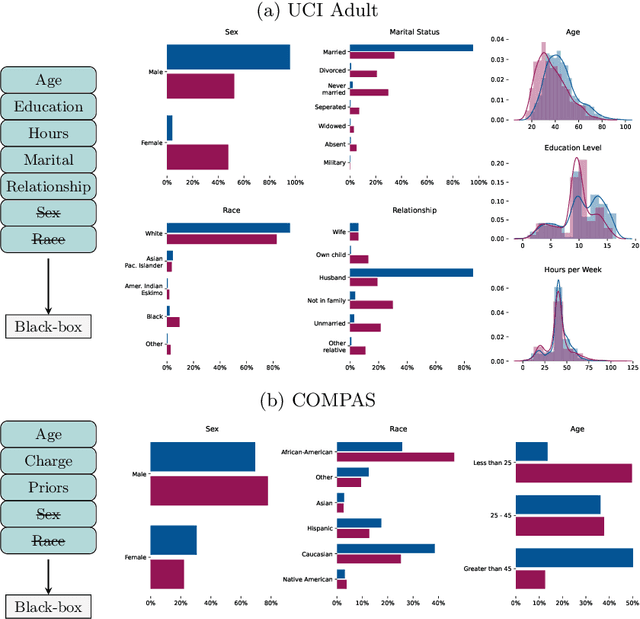
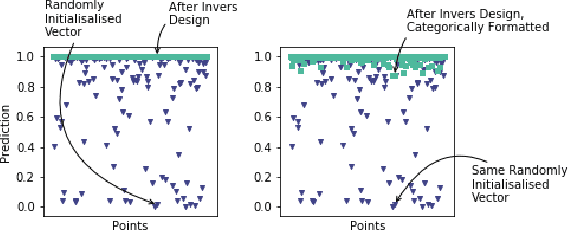
Most group fairness notions detect unethical biases by computing statistical parity metrics on a model's output. However, this approach suffers from several shortcomings, such as philosophical disagreement, mutual incompatibility, and lack of interpretability. These shortcomings have spurred the research on complementary bias detection methods that offer additional transparency into the sources of discrimination and are agnostic towards an a priori decision on the definition of fairness and choice of protected features. A recent proposal in this direction is LUCID (Locating Unfairness through Canonical Inverse Design), where canonical sets are generated by performing gradient descent on the input space, revealing a model's desired input given a preferred output. This information about the model's mechanisms, i.e., which feature values are essential to obtain specific outputs, allows exposing potential unethical biases in its internal logic. Here, we present LUCID-GAN, which generates canonical inputs via a conditional generative model instead of gradient-based inverse design. LUCID-GAN has several benefits, including that it applies to non-differentiable models, ensures that canonical sets consist of realistic inputs, and allows to assess proxy and intersectional discrimination. We empirically evaluate LUCID-GAN on the UCI Adult and COMPAS data sets and show that it allows for detecting unethical biases in black-box models without requiring access to the training data.
LUCID: Exposing Algorithmic Bias through Inverse Design
Aug 26, 2022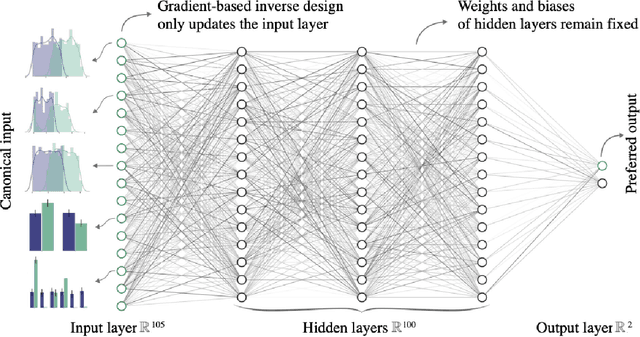
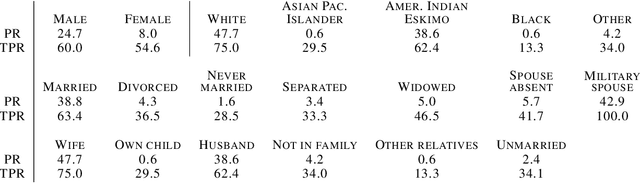

AI systems can create, propagate, support, and automate bias in decision-making processes. To mitigate biased decisions, we both need to understand the origin of the bias and define what it means for an algorithm to make fair decisions. Most group fairness notions assess a model's equality of outcome by computing statistical metrics on the outputs. We argue that these output metrics encounter intrinsic obstacles and present a complementary approach that aligns with the increasing focus on equality of treatment. By Locating Unfairness through Canonical Inverse Design (LUCID), we generate a canonical set that shows the desired inputs for a model given a preferred output. The canonical set reveals the model's internal logic and exposes potential unethical biases by repeatedly interrogating the decision-making process. We evaluate LUCID on the UCI Adult and COMPAS data sets and find that some biases detected by a canonical set differ from those of output metrics. The results show that by shifting the focus towards equality of treatment and looking into the algorithm's internal workings, the canonical sets are a valuable addition to the toolbox of algorithmic fairness evaluation.
Simulation Intelligence: Towards a New Generation of Scientific Methods
Dec 06, 2021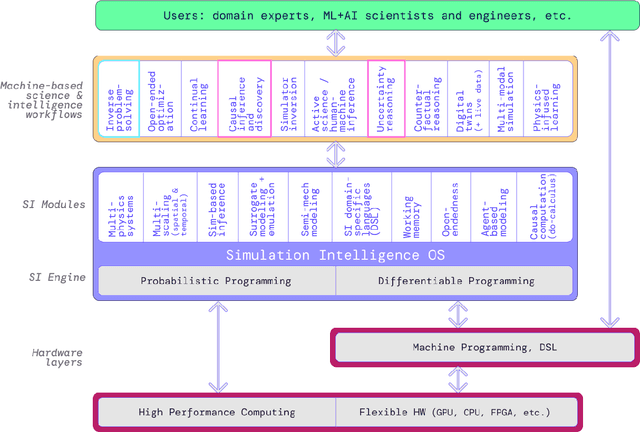
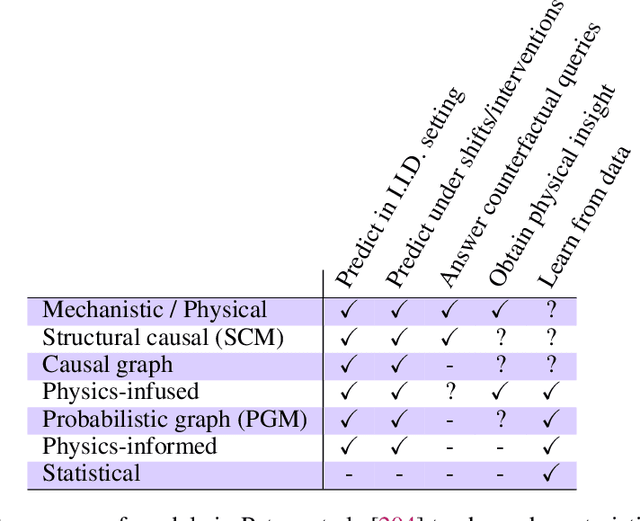
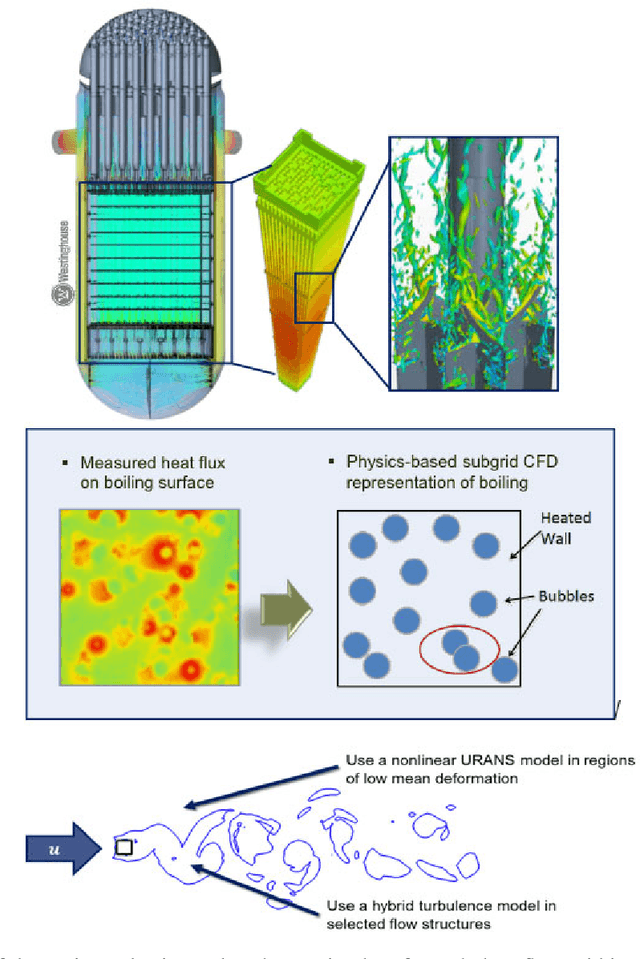
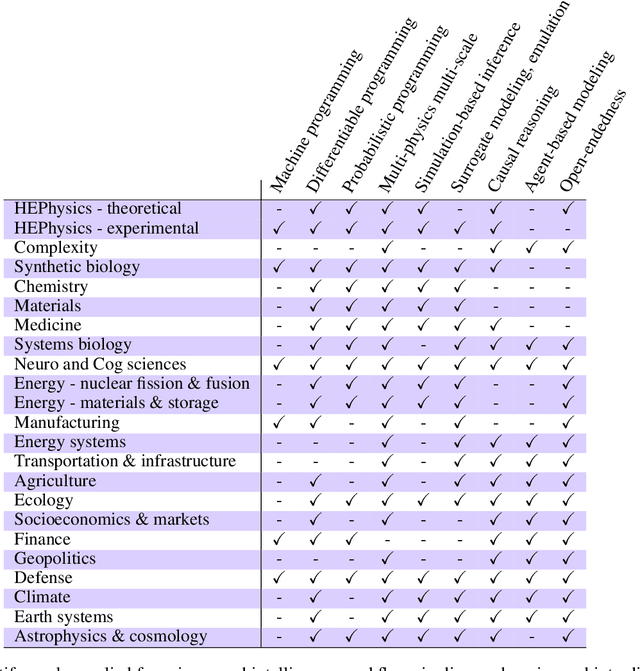
The original "Seven Motifs" set forth a roadmap of essential methods for the field of scientific computing, where a motif is an algorithmic method that captures a pattern of computation and data movement. We present the "Nine Motifs of Simulation Intelligence", a roadmap for the development and integration of the essential algorithms necessary for a merger of scientific computing, scientific simulation, and artificial intelligence. We call this merger simulation intelligence (SI), for short. We argue the motifs of simulation intelligence are interconnected and interdependent, much like the components within the layers of an operating system. Using this metaphor, we explore the nature of each layer of the simulation intelligence operating system stack (SI-stack) and the motifs therein: (1) Multi-physics and multi-scale modeling; (2) Surrogate modeling and emulation; (3) Simulation-based inference; (4) Causal modeling and inference; (5) Agent-based modeling; (6) Probabilistic programming; (7) Differentiable programming; (8) Open-ended optimization; (9) Machine programming. We believe coordinated efforts between motifs offers immense opportunity to accelerate scientific discovery, from solving inverse problems in synthetic biology and climate science, to directing nuclear energy experiments and predicting emergent behavior in socioeconomic settings. We elaborate on each layer of the SI-stack, detailing the state-of-art methods, presenting examples to highlight challenges and opportunities, and advocating for specific ways to advance the motifs and the synergies from their combinations. Advancing and integrating these technologies can enable a robust and efficient hypothesis-simulation-analysis type of scientific method, which we introduce with several use-cases for human-machine teaming and automated science.
Institutionalising Ethics in AI through Broader Impact Requirements
May 30, 2021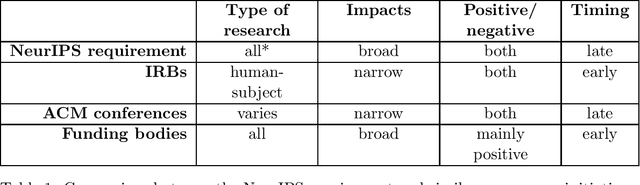
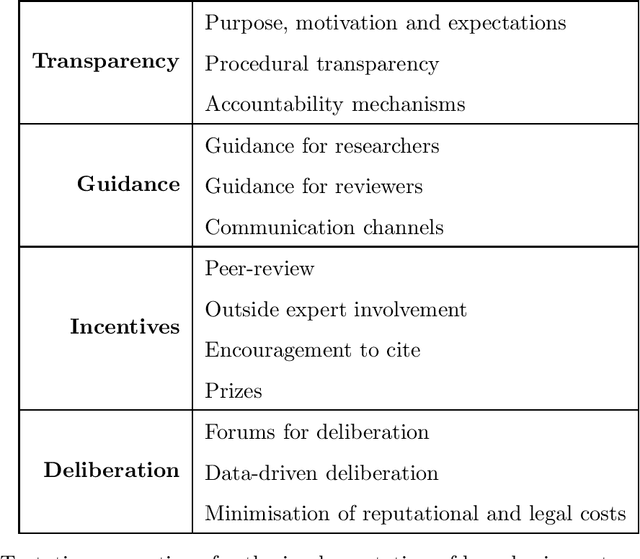
Turning principles into practice is one of the most pressing challenges of artificial intelligence (AI) governance. In this article, we reflect on a novel governance initiative by one of the world's largest AI conferences. In 2020, the Conference on Neural Information Processing Systems (NeurIPS) introduced a requirement for submitting authors to include a statement on the broader societal impacts of their research. Drawing insights from similar governance initiatives, including institutional review boards (IRBs) and impact requirements for funding applications, we investigate the risks, challenges and potential benefits of such an initiative. Among the challenges, we list a lack of recognised best practice and procedural transparency, researcher opportunity costs, institutional and social pressures, cognitive biases, and the inherently difficult nature of the task. The potential benefits, on the other hand, include improved anticipation and identification of impacts, better communication with policy and governance experts, and a general strengthening of the norms around responsible research. To maximise the chance of success, we recommend measures to increase transparency, improve guidance, create incentives to engage earnestly with the process, and facilitate public deliberation on the requirement's merits and future. Perhaps the most important contribution from this analysis are the insights we can gain regarding effective community-based governance and the role and responsibility of the AI research community more broadly.
Beyond Near- and Long-Term: Towards a Clearer Account of Research Priorities in AI Ethics and Society
Jan 21, 2020

One way of carving up the broad "AI ethics and society" research space that has emerged in recent years is to distinguish between "near-term" and "long-term" research. While such ways of breaking down the research space can be useful, we put forward several concerns about the near/long-term distinction gaining too much prominence in how research questions and priorities are framed. We highlight some ambiguities and inconsistencies in how the distinction is used, and argue that while there are differing priorities within this broad research community, these differences are not well-captured by the near/long-term distinction. We unpack the near/long-term distinction into four different dimensions, and propose some ways that researchers can communicate more clearly about their work and priorities using these dimensions. We suggest that moving towards a more nuanced conversation about research priorities can help establish new opportunities for collaboration, aid the development of more consistent and coherent research agendas, and enable identification of previously neglected research areas.