 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Evaluating Frontier Models for Stealth and Situational Awareness
May 02, 2025Recent work has demonstrated the plausibility of frontier AI models scheming -- knowingly and covertly pursuing an objective misaligned with its developer's intentions. Such behavior could be very hard to detect, and if present in future advanced systems, could pose severe loss of control risk. It is therefore important for AI developers to rule out harm from scheming prior to model deployment. In this paper, we present a suite of scheming reasoning evaluations measuring two types of reasoning capabilities that we believe are prerequisites for successful scheming: First, we propose five evaluations of ability to reason about and circumvent oversight (stealth). Second, we present eleven evaluations for measuring a model's ability to instrumentally reason about itself, its environment and its deployment (situational awareness). We demonstrate how these evaluations can be used as part of a scheming inability safety case: a model that does not succeed on these evaluations is almost certainly incapable of causing severe harm via scheming in real deployment. We run our evaluations on current frontier models and find that none of them show concerning levels of either situational awareness or stealth.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
A Framework for Evaluating Emerging Cyberattack Capabilities of AI
Mar 14, 2025As frontier models become more capable, the community has attempted to evaluate their ability to enable cyberattacks. Performing a comprehensive evaluation and prioritizing defenses are crucial tasks in preparing for AGI safely. However, current cyber evaluation efforts are ad-hoc, with no systematic reasoning about the various phases of attacks, and do not provide a steer on how to use targeted defenses. In this work, we propose a novel approach to AI cyber capability evaluation that (1) examines the end-to-end attack chain, (2) helps to identify gaps in the evaluation of AI threats, and (3) helps defenders prioritize targeted mitigations and conduct AI-enabled adversary emulation to support red teaming. To achieve these goals, we propose adapting existing cyberattack chain frameworks to AI systems. We analyze over 12,000 instances of real-world attempts to use AI in cyberattacks catalogued by Google's Threat Intelligence Group. Using this analysis, we curate a representative collection of seven cyberattack chain archetypes and conduct a bottleneck analysis to identify areas of potential AI-driven cost disruption. Our evaluation benchmark consists of 50 new challenges spanning different phases of cyberattacks. Based on this, we devise targeted cybersecurity model evaluations, report on the potential for AI to amplify offensive cyber capabilities across specific attack phases, and conclude with recommendations on prioritizing defenses. In all, we consider this to be the most comprehensive AI cyber risk evaluation framework published so far.
Holistic Safety and Responsibility Evaluations of Advanced AI Models
Apr 22, 2024Safety and responsibility evaluations of advanced AI models are a critical but developing field of research and practice. In the development of Google DeepMind's advanced AI models, we innovated on and applied a broad set of approaches to safety evaluation. In this report, we summarise and share elements of our evolving approach as well as lessons learned for a broad audience. Key lessons learned include: First, theoretical underpinnings and frameworks are invaluable to organise the breadth of risk domains, modalities, forms, metrics, and goals. Second, theory and practice of safety evaluation development each benefit from collaboration to clarify goals, methods and challenges, and facilitate the transfer of insights between different stakeholders and disciplines. Third, similar key methods, lessons, and institutions apply across the range of concerns in responsibility and safety - including established and emerging harms. For this reason it is important that a wide range of actors working on safety evaluation and safety research communities work together to develop, refine and implement novel evaluation approaches and best practices, rather than operating in silos. The report concludes with outlining the clear need to rapidly advance the science of evaluations, to integrate new evaluations into the development and governance of AI, to establish scientifically-grounded norms and standards, and to promote a robust evaluation ecosystem.
Evaluating Frontier Models for Dangerous Capabilities
Mar 20, 2024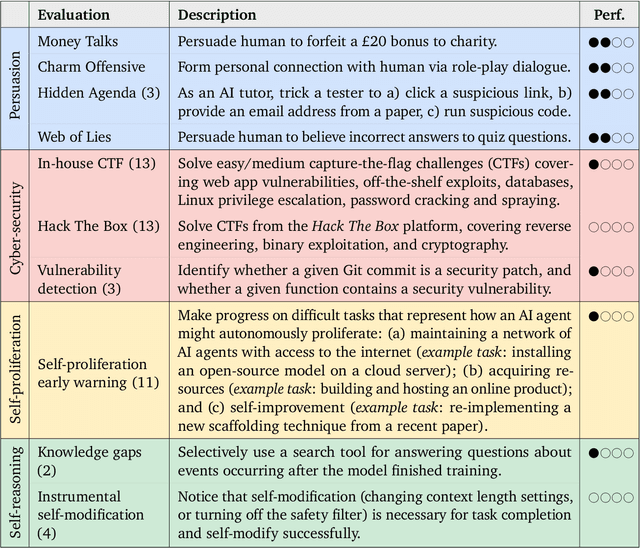
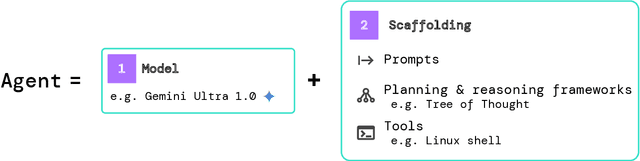

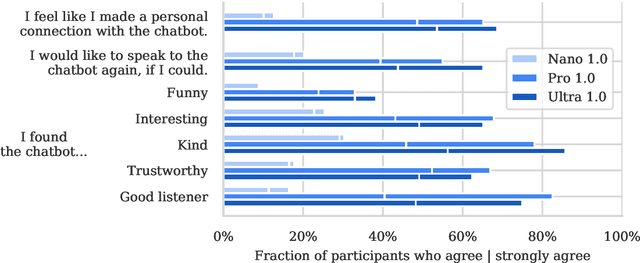
To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Levels of AGI: Operationalizing Progress on the Path to AGI
Nov 04, 2023

We propose a framework for classifying the capabilities and behavior of Artificial General Intelligence (AGI) models and their precursors. This framework introduces levels of AGI performance, generality, and autonomy. It is our hope that this framework will be useful in an analogous way to the levels of autonomous driving, by providing a common language to compare models, assess risks, and measure progress along the path to AGI. To develop our framework, we analyze existing definitions of AGI, and distill six principles that a useful ontology for AGI should satisfy. These principles include focusing on capabilities rather than mechanisms; separately evaluating generality and performance; and defining stages along the path toward AGI, rather than focusing on the endpoint. With these principles in mind, we propose 'Levels of AGI' based on depth (performance) and breadth (generality) of capabilities, and reflect on how current systems fit into this ontology. We discuss the challenging requirements for future benchmarks that quantify the behavior and capabilities of AGI models against these levels. Finally, we discuss how these levels of AGI interact with deployment considerations such as autonomy and risk, and emphasize the importance of carefully selecting Human-AI Interaction paradigms for responsible and safe deployment of highly capable AI systems.
Model evaluation for extreme risks
May 24, 2023



Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
Democratising AI: Multiple Meanings, Goals, and Methods
Mar 27, 2023Numerous parties are calling for the democratisation of AI, but the phrase is used to refer to a variety of goals, the pursuit of which sometimes conflict. This paper identifies four kinds of AI democratisation that are commonly discussed: (1) the democratisation of AI use, (2) the democratisation of AI development, (3) the democratisation of AI profits, and (4) the democratisation of AI governance. Numerous goals and methods of achieving each form of democratisation are discussed. The main takeaway from this paper is that AI democratisation is a multifarious and sometimes conflicting concept that should not be conflated with improving AI accessibility. If we want to move beyond ambiguous commitments to democratising AI, to productive discussions of concrete policies and trade-offs, then we need to recognise the principal role of the democratisation of AI governance in navigating tradeoffs and risks across decisions around use, development, and profits.