 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and the Future of Digital Public Squares
Dec 13, 2024



Two substantial technological advances have reshaped the public square in recent decades: first with the advent of the internet and second with the recent introduction of large language models (LLMs). LLMs offer opportunities for a paradigm shift towards more decentralized, participatory online spaces that can be used to facilitate deliberative dialogues at scale, but also create risks of exacerbating societal schisms. Here, we explore four applications of LLMs to improve digital public squares: collective dialogue systems, bridging systems, community moderation, and proof-of-humanity systems. Building on the input from over 70 civil society experts and technologists, we argue that LLMs both afford promising opportunities to shift the paradigm for conversations at scale and pose distinct risks for digital public squares. We lay out an agenda for future research and investments in AI that will strengthen digital public squares and safeguard against potential misuses of AI.
Chain of Alignment: Integrating Public Will with Expert Intelligence for Language Model Alignment
Nov 15, 2024



We introduce a method to measure the alignment between public will and language model (LM) behavior that can be applied to fine-tuning, online oversight, and pre-release safety checks. Our `chain of alignment' (CoA) approach produces a rule based reward (RBR) by creating model behavior $\textit{rules}$ aligned to normative $\textit{objectives}$ aligned to $\textit{public will}$. This factoring enables a nonexpert public to directly specify their will through the normative objectives, while expert intelligence is used to figure out rules entailing model behavior that best achieves those objectives. We validate our approach by applying it across three different domains of LM prompts related to mental health. We demonstrate a public input process built on collective dialogues and bridging-based ranking that reliably produces normative objectives supported by at least $96\% \pm 2\%$ of the US public. We then show that rules developed by mental health experts to achieve those objectives enable a RBR that evaluates an LM response's alignment with the objectives similarly to human experts (Pearson's $r=0.841$, $AUC=0.964$). By measuring alignment with objectives that have near unanimous public support, these CoA RBRs provide an approximate measure of alignment between LM behavior and public will.
Democratising AI: Multiple Meanings, Goals, and Methods
Mar 27, 2023Numerous parties are calling for the democratisation of AI, but the phrase is used to refer to a variety of goals, the pursuit of which sometimes conflict. This paper identifies four kinds of AI democratisation that are commonly discussed: (1) the democratisation of AI use, (2) the democratisation of AI development, (3) the democratisation of AI profits, and (4) the democratisation of AI governance. Numerous goals and methods of achieving each form of democratisation are discussed. The main takeaway from this paper is that AI democratisation is a multifarious and sometimes conflicting concept that should not be conflated with improving AI accessibility. If we want to move beyond ambiguous commitments to democratising AI, to productive discussions of concrete policies and trade-offs, then we need to recognise the principal role of the democratisation of AI governance in navigating tradeoffs and risks across decisions around use, development, and profits.
'Generative CI' through Collective Response Systems
Feb 01, 2023How can many people (who may disagree) come together to answer a question or make a decision? "Collective response systems" are a type of generative collective intelligence (CI) facilitation process meant to address this challenge. They enable a form of "generative voting", where both the votes, and the choices of what to vote on, are provided by the group. Such systems overcome the traditional limitations of polling, town halls, standard voting, referendums, etc. The generative CI outputs of collective response systems can also be chained together into iterative "collective dialogues", analogously to some kinds of generative AI. Technical advances across domains including recommender systems, language models, and human-computer interaction have led to the development of innovative and scalable collective response systems. For example, Polis has been used around the world to support policy-making at different levels of government, and Remesh has been used by the UN to understand the challenges and needs of ordinary people across war-torn countries. This paper aims to develop a shared language by defining the structure, processes, properties, and principles of such systems. Collective response systems allow non-confrontational exploration of divisive issues, help identify common ground, and elicit insights from those closest to the issues. As a result, they can help overcome gridlock around conflict and governance challenges, increase trust, and develop mandates. Continued progress toward their development and adoption could help revitalize democracies, reimagine corporate governance, transform conflict, and govern powerful AI systems -- both as a complement to deeper deliberative democratic processes and as an option where deeper processes are not applicable or possible.
The Deepfake Detection Dilemma: A Multistakeholder Exploration of Adversarial Dynamics in Synthetic Media
Feb 11, 2021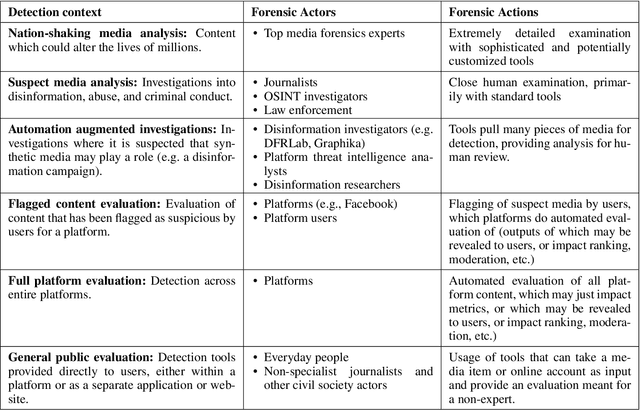


Synthetic media detection technologies label media as either synthetic or non-synthetic and are increasingly used by journalists, web platforms, and the general public to identify misinformation and other forms of problematic content. As both well-resourced organizations and the non-technical general public generate more sophisticated synthetic media, the capacity for purveyors of problematic content to adapt induces a \newterm{detection dilemma}: as detection practices become more accessible, they become more easily circumvented. This paper describes how a multistakeholder cohort from academia, technology platforms, media entities, and civil society organizations active in synthetic media detection and its socio-technical implications evaluates the detection dilemma. Specifically, we offer an assessment of detection contexts and adversary capacities sourced from the broader, global AI and media integrity community concerned with mitigating the spread of harmful synthetic media. A collection of personas illustrates the intersection between unsophisticated and highly-resourced sponsors of misinformation in the context of their technical capacities. This work concludes that there is no "best" approach to navigating the detector dilemma, but derives a set of implications from multistakeholder input to better inform detection process decisions and policies, in practice.
The tension between openness and prudence in AI research
Oct 02, 2019This paper explores the tension between openness and prudence in AI research, evident in two core principles of the Montr\'eal Declaration for Responsible AI. While the AI community has strong norms around open sharing of research, concerns about the potential harms arising from misuse of research are growing, prompting some to consider whether the field of AI needs to reconsider publication norms. We discuss how different beliefs and values can lead to differing perspectives on how the AI community should manage this tension, and explore implications for what responsible publication norms in AI research might look like in practice.
Reducing malicious use of synthetic media research: Considerations and potential release practices for machine learning
Jul 29, 2019The aim of this paper is to facilitate nuanced discussion around research norms and practices to mitigate the harmful impacts of advances in machine learning (ML). We focus particularly on the use of ML to create "synthetic media" (e.g. to generate or manipulate audio, video, images, and text), and the question of what publication and release processes around such research might look like, though many of the considerations discussed will apply to ML research more broadly. We are not arguing for any specific approach on when or how research should be distributed, but instead try to lay out some useful tools, analogies, and options for thinking about these issues. We begin with some background on the idea that ML research might be misused in harmful ways, and why advances in synthetic media, in particular, are raising concerns. We then outline in more detail some of the different paths to harm from ML research, before reviewing research risk mitigation strategies in other fields and identifying components that seem most worth emulating in the ML and synthetic media research communities. Next, we outline some important dimensions of disagreement on these issues which risk polarizing conversations. Finally, we conclude with recommendations, suggesting that the machine learning community might benefit from: working with subject matter experts to increase understanding of the risk landscape and possible mitigation strategies; building a community and norms around understanding the impacts of ML research, e.g. through regular workshops at major conferences; and establishing institutions and systems to support release practices that would otherwise be onerous and error-prone.