 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Management for Mitigating Benchmark Failure Modes: BenchRisk
Oct 24, 2025Large language model (LLM) benchmarks inform LLM use decisions (e.g., "is this LLM safe to deploy for my use case and context?"). However, benchmarks may be rendered unreliable by various failure modes that impact benchmark bias, variance, coverage, or people's capacity to understand benchmark evidence. Using the National Institute of Standards and Technology's risk management process as a foundation, this research iteratively analyzed 26 popular benchmarks, identifying 57 potential failure modes and 196 corresponding mitigation strategies. The mitigations reduce failure likelihood and/or severity, providing a frame for evaluating "benchmark risk," which is scored to provide a metaevaluation benchmark: BenchRisk. Higher scores indicate that benchmark users are less likely to reach an incorrect or unsupported conclusion about an LLM. All 26 scored benchmarks present significant risk within one or more of the five scored dimensions (comprehensiveness, intelligibility, consistency, correctness, and longevity), which points to important open research directions for the field of LLM benchmarking. The BenchRisk workflow allows for comparison between benchmarks; as an open-source tool, it also facilitates the identification and sharing of risks and their mitigations.
Malicious and Unintentional Disclosure Risks in Large Language Models for Code Generation
Mar 27, 2025



This paper explores the risk that a large language model (LLM) trained for code generation on data mined from software repositories will generate content that discloses sensitive information included in its training data. We decompose this risk, known in the literature as ``unintended memorization,'' into two components: unintentional disclosure (where an LLM presents secrets to users without the user seeking them out) and malicious disclosure (where an LLM presents secrets to an attacker equipped with partial knowledge of the training data). We observe that while existing work mostly anticipates malicious disclosure, unintentional disclosure is also a concern. We describe methods to assess unintentional and malicious disclosure risks side-by-side across different releases of training datasets and models. We demonstrate these methods through an independent assessment of the Open Language Model (OLMo) family of models and its Dolma training datasets. Our results show, first, that changes in data source and processing are associated with substantial changes in unintended memorization risk; second, that the same set of operational changes may increase one risk while mitigating another; and, third, that the risk of disclosing sensitive information varies not only by prompt strategies or test datasets but also by the types of sensitive information. These contributions rely on data mining to enable greater privacy and security testing required for the LLM training data supply chain.
To Err is AI : A Case Study Informing LLM Flaw Reporting Practices
Oct 15, 2024



In August of 2024, 495 hackers generated evaluations in an open-ended bug bounty targeting the Open Language Model (OLMo) from The Allen Institute for AI. A vendor panel staffed by representatives of OLMo's safety program adjudicated changes to OLMo's documentation and awarded cash bounties to participants who successfully demonstrated a need for public disclosure clarifying the intent, capacities, and hazards of model deployment. This paper presents a collection of lessons learned, illustrative of flaw reporting best practices intended to reduce the likelihood of incidents and produce safer large language models (LLMs). These include best practices for safety reporting processes, their artifacts, and safety program staffing.
Lessons for Editors of AI Incidents from the AI Incident Database
Sep 24, 2024As artificial intelligence (AI) systems become increasingly deployed across the world, they are also increasingly implicated in AI incidents - harm events to individuals and society. As a result, industry, civil society, and governments worldwide are developing best practices and regulations for monitoring and analyzing AI incidents. The AI Incident Database (AIID) is a project that catalogs AI incidents and supports further research by providing a platform to classify incidents for different operational and research-oriented goals. This study reviews the AIID's dataset of 750+ AI incidents and two independent taxonomies applied to these incidents to identify common challenges to indexing and analyzing AI incidents. We find that certain patterns of AI incidents present structural ambiguities that challenge incident databasing and explore how epistemic uncertainty in AI incident reporting is unavoidable. We therefore report mitigations to make incident processes more robust to uncertainty related to cause, extent of harm, severity, or technical details of implicated systems. With these findings, we discuss how to develop future AI incident reporting practices.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Data-Centric Governance
Feb 14, 2023



Artificial intelligence (AI) governance is the body of standards and practices used to ensure that AI systems are deployed responsibly. Current AI governance approaches consist mainly of manual review and documentation processes. While such reviews are necessary for many systems, they are not sufficient to systematically address all potential harms, as they do not operationalize governance requirements for system engineering, behavior, and outcomes in a way that facilitates rigorous and reproducible evaluation. Modern AI systems are data-centric: they act on data, produce data, and are built through data engineering. The assurance of governance requirements must also be carried out in terms of data. This work explores the systematization of governance requirements via datasets and algorithmic evaluations. When applied throughout the product lifecycle, data-centric governance decreases time to deployment, increases solution quality, decreases deployment risks, and places the system in a continuous state of assured compliance with governance requirements.
Indexing AI Risks with Incidents, Issues, and Variants
Nov 18, 2022Two years after publicly launching the AI Incident Database (AIID) as a collection of harms or near harms produced by AI in the world, a backlog of "issues" that do not meet its incident ingestion criteria have accumulated in its review queue. Despite not passing the database's current criteria for incidents, these issues advance human understanding of where AI presents the potential for harm. Similar to databases in aviation and computer security, the AIID proposes to adopt a two-tiered system for indexing AI incidents (i.e., a harm or near harm event) and issues (i.e., a risk of a harm event). Further, as some machine learning-based systems will sometimes produce a large number of incidents, the notion of an incident "variant" is introduced. These proposed changes mark the transition of the AIID to a new version in response to lessons learned from editing 2,000+ incident reports and additional reports that fall under the new category of "issue."
Participation Interfaces for Human-Centered AI
Nov 15, 2022
Emerging artificial intelligence (AI) applications often balance the preferences and impacts among diverse and contentious stakeholder groups. Accommodating these stakeholder groups during system design, development, and deployment requires tools for the elicitation of disparate system interests and collaboration interfaces supporting negotiation balancing those interests. This paper introduces interactive visual "participation interfaces" for Markov Decision Processes (MDPs) and collaborative ranking problems as examples restoring a human-centered locus of control.
A taxonomic system for failure cause analysis of open source AI incidents
Nov 14, 2022


While certain industrial sectors (e.g., aviation) have a long history of mandatory incident reporting complete with analytical findings, the practice of artificial intelligence (AI) safety benefits from no such mandate and thus analyses must be performed on publicly known ``open source'' AI incidents. Although the exact causes of AI incidents are seldom known by outsiders, this work demonstrates how to apply expert knowledge on the population of incidents in the AI Incident Database (AIID) to infer the potential and likely technical causative factors that contribute to reported failures and harms. We present early work on a taxonomic system that covers a cascade of interrelated incident factors, from system goals (nearly always known) to methods / technologies (knowable in many cases) and technical failure causes (subject to expert analysis) of the implicated systems. We pair this ontology structure with a comprehensive classification workflow that leverages expert knowledge and community feedback, resulting in taxonomic annotations grounded by incident data and human expertise.
The Deepfake Detection Dilemma: A Multistakeholder Exploration of Adversarial Dynamics in Synthetic Media
Feb 11, 2021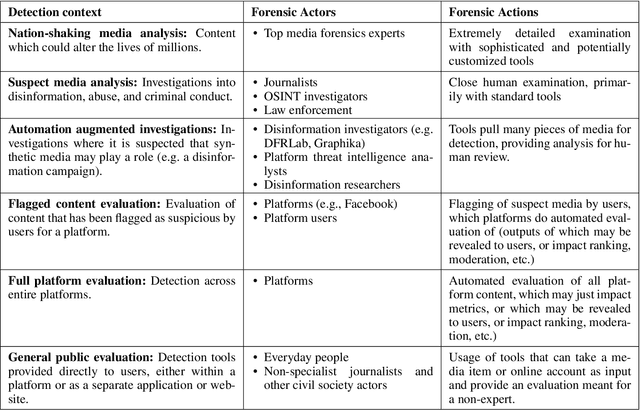


Synthetic media detection technologies label media as either synthetic or non-synthetic and are increasingly used by journalists, web platforms, and the general public to identify misinformation and other forms of problematic content. As both well-resourced organizations and the non-technical general public generate more sophisticated synthetic media, the capacity for purveyors of problematic content to adapt induces a \newterm{detection dilemma}: as detection practices become more accessible, they become more easily circumvented. This paper describes how a multistakeholder cohort from academia, technology platforms, media entities, and civil society organizations active in synthetic media detection and its socio-technical implications evaluates the detection dilemma. Specifically, we offer an assessment of detection contexts and adversary capacities sourced from the broader, global AI and media integrity community concerned with mitigating the spread of harmful synthetic media. A collection of personas illustrates the intersection between unsophisticated and highly-resourced sponsors of misinformation in the context of their technical capacities. This work concludes that there is no "best" approach to navigating the detector dilemma, but derives a set of implications from multistakeholder input to better inform detection process decisions and policies, in practice.