 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons for Editors of AI Incidents from the AI Incident Database
Sep 24, 2024As artificial intelligence (AI) systems become increasingly deployed across the world, they are also increasingly implicated in AI incidents - harm events to individuals and society. As a result, industry, civil society, and governments worldwide are developing best practices and regulations for monitoring and analyzing AI incidents. The AI Incident Database (AIID) is a project that catalogs AI incidents and supports further research by providing a platform to classify incidents for different operational and research-oriented goals. This study reviews the AIID's dataset of 750+ AI incidents and two independent taxonomies applied to these incidents to identify common challenges to indexing and analyzing AI incidents. We find that certain patterns of AI incidents present structural ambiguities that challenge incident databasing and explore how epistemic uncertainty in AI incident reporting is unavoidable. We therefore report mitigations to make incident processes more robust to uncertainty related to cause, extent of harm, severity, or technical details of implicated systems. With these findings, we discuss how to develop future AI incident reporting practices.
A taxonomic system for failure cause analysis of open source AI incidents
Nov 14, 2022


While certain industrial sectors (e.g., aviation) have a long history of mandatory incident reporting complete with analytical findings, the practice of artificial intelligence (AI) safety benefits from no such mandate and thus analyses must be performed on publicly known ``open source'' AI incidents. Although the exact causes of AI incidents are seldom known by outsiders, this work demonstrates how to apply expert knowledge on the population of incidents in the AI Incident Database (AIID) to infer the potential and likely technical causative factors that contribute to reported failures and harms. We present early work on a taxonomic system that covers a cascade of interrelated incident factors, from system goals (nearly always known) to methods / technologies (knowable in many cases) and technical failure causes (subject to expert analysis) of the implicated systems. We pair this ontology structure with a comprehensive classification workflow that leverages expert knowledge and community feedback, resulting in taxonomic annotations grounded by incident data and human expertise.
A Cooperative Reinforcement Learning Environment for Detecting and Penalizing Betrayal
Oct 23, 2022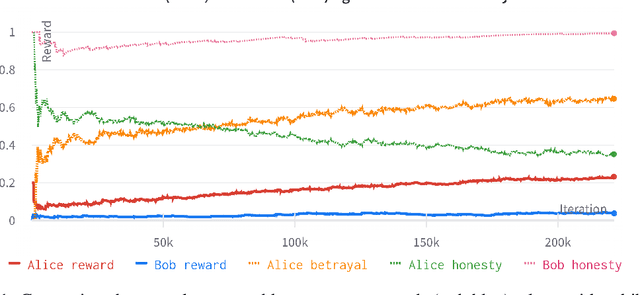



In this paper we present a Reinforcement Learning environment that leverages agent cooperation and communication, aimed at detection, learning and ultimately penalizing betrayal patterns that emerge in the behavior of self-interested agents. We provide a description of game rules, along with interesting cases of betrayal and trade-offs that arise. Preliminary experimental investigations illustrate a) betrayal emergence, b) deceptive agents outperforming honest baselines and b) betrayal detection based on classification of behavioral features, which surpasses probabilistic detection baselines. Finally, we propose approaches for penalizing betrayal, list directions for future work and suggest interesting extensions of the environment towards capturing and exploring increasingly complex patterns of social interactions.
A study of text representations in Hate Speech Detection
Feb 08, 2021

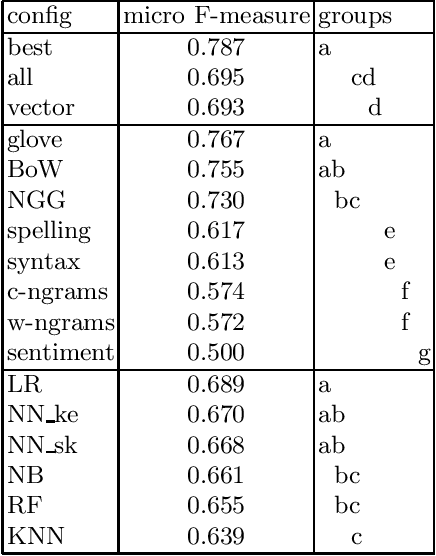
The pervasiveness of the Internet and social media have enabled the rapid and anonymous spread of Hate Speech content on microblogging platforms such as Twitter. Current EU and US legislation against hateful language, in conjunction with the large amount of data produced in these platforms has led to automatic tools being a necessary component of the Hate Speech detection task and pipeline. In this study, we examine the performance of several, diverse text representation techniques paired with multiple classification algorithms, on the automatic Hate Speech detection and abusive language discrimination task. We perform an experimental evaluation on binary and multiclass datasets, paired with significance testing. Our results show that simple hate-keyword frequency features (BoW) work best, followed by pre-trained word embeddings (GLoVe) as well as N-gram graphs (NGGs): a graph-based representation which proved to produce efficient, very low-dimensional but rich features for this task. A combination of these representations paired with Logistic Regression or 3-layer neural network classifiers achieved the best detection performance, in terms of micro and macro F-measure.