 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Machine-Learned Potentials for Coarse-Grained Molecular Simulations: Challenges and Pitfalls
Sep 26, 2022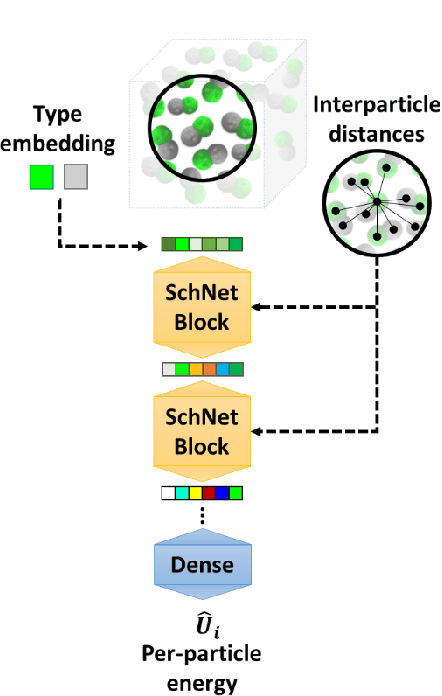
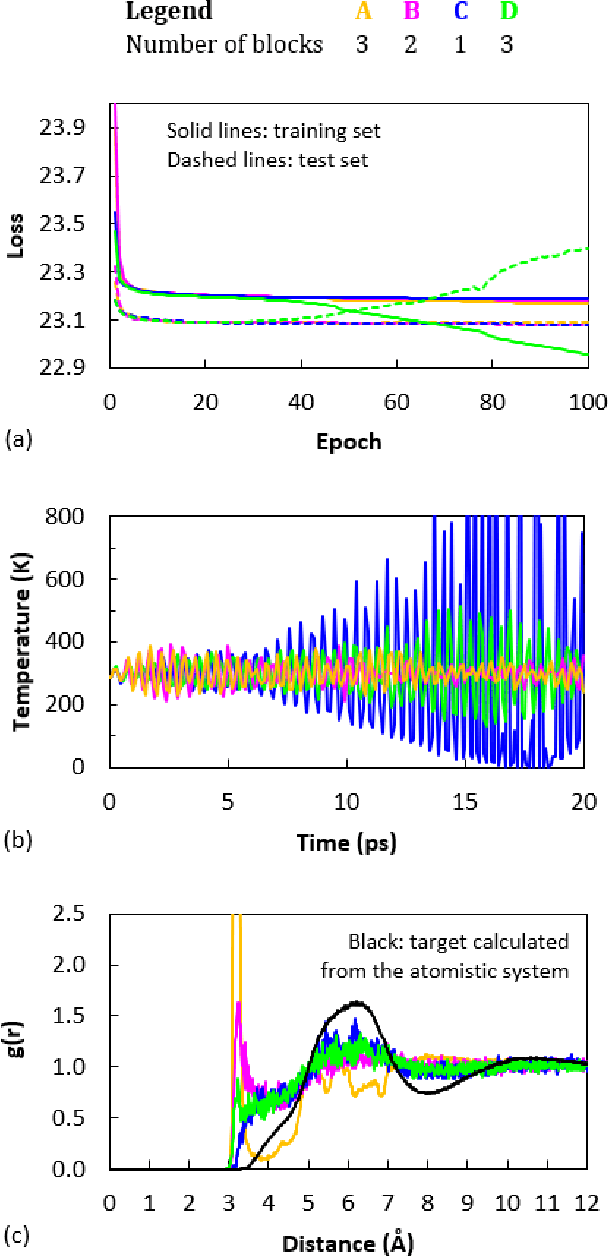
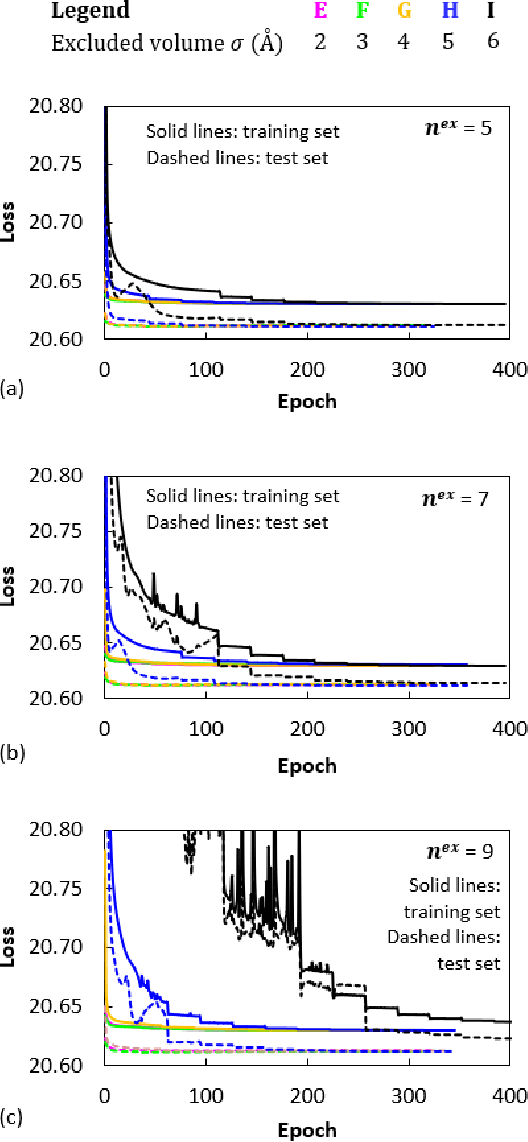
Coarse graining (CG) enables the investigation of molecular properties for larger systems and at longer timescales than the ones attainable at the atomistic resolution. Machine learning techniques have been recently proposed to learn CG particle interactions, i.e. develop CG force fields. Graph representations of molecules and supervised training of a graph convolutional neural network architecture are used to learn the potential of mean force through a force matching scheme. In this work, the force acting on each CG particle is correlated to a learned representation of its local environment that goes under the name of SchNet, constructed via continuous filter convolutions. We explore the application of SchNet models to obtain a CG potential for liquid benzene, investigating the effect of model architecture and hyperparameters on the thermodynamic, dynamical, and structural properties of the simulated CG systems, reporting and discussing challenges encountered and future directions envisioned.
Investigation of Machine Learning-based Coarse-Grained Mapping Schemes for Organic Molecules
Sep 26, 2022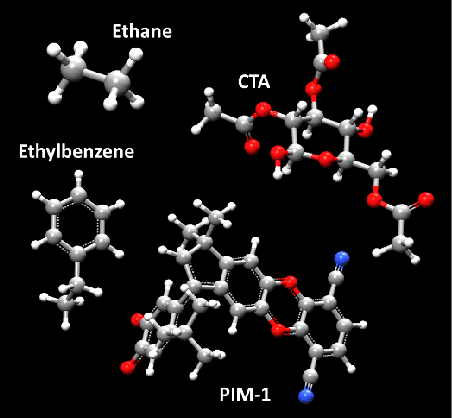
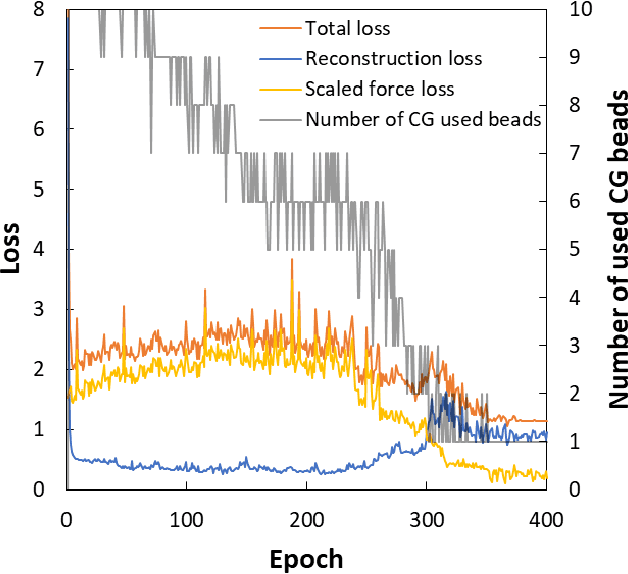
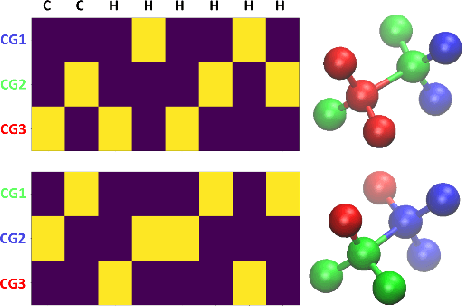
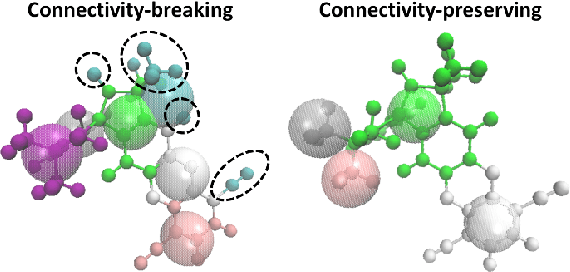
Due to the wide range of timescales that are present in macromolecular systems, hierarchical multiscale strategies are necessary for their computational study. Coarse-graining (CG) allows to establish a link between different system resolutions and provides the backbone for the development of robust multiscale simulations and analyses. The CG mapping process is typically system- and application-specific, and it relies on chemical intuition. In this work, we explored the application of a Machine Learning strategy, based on Variational Autoencoders, for the development of suitable mapping schemes from the atomistic to the coarse-grained space of molecules with increasing chemical complexity. An extensive evaluation of the effect of the model hyperparameters on the training process and on the final output was performed, and an existing method was extended with the definition of different loss functions and the implementation of a selection criterion that ensures physical consistency of the output. The relationship between the input feature choice and the reconstruction accuracy was analyzed, supporting the need to introduce rotational invariance into the system. Strengths and limitations of the approach, both in the mapping and in the backmapping steps, are highlighted and critically discussed.
Tree-based Focused Web Crawling with Reinforcement Learning
Dec 12, 2021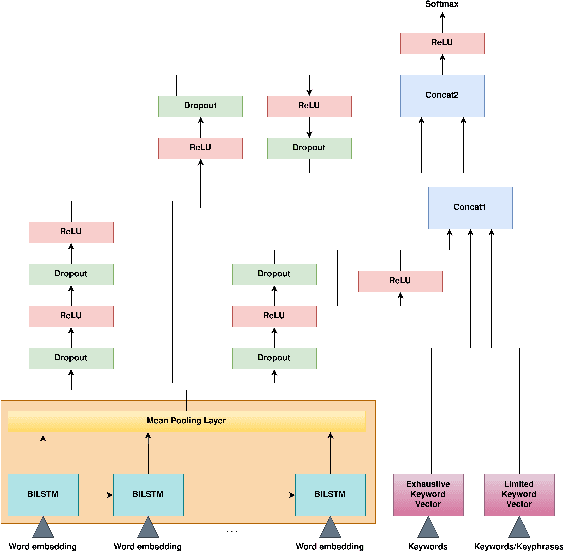

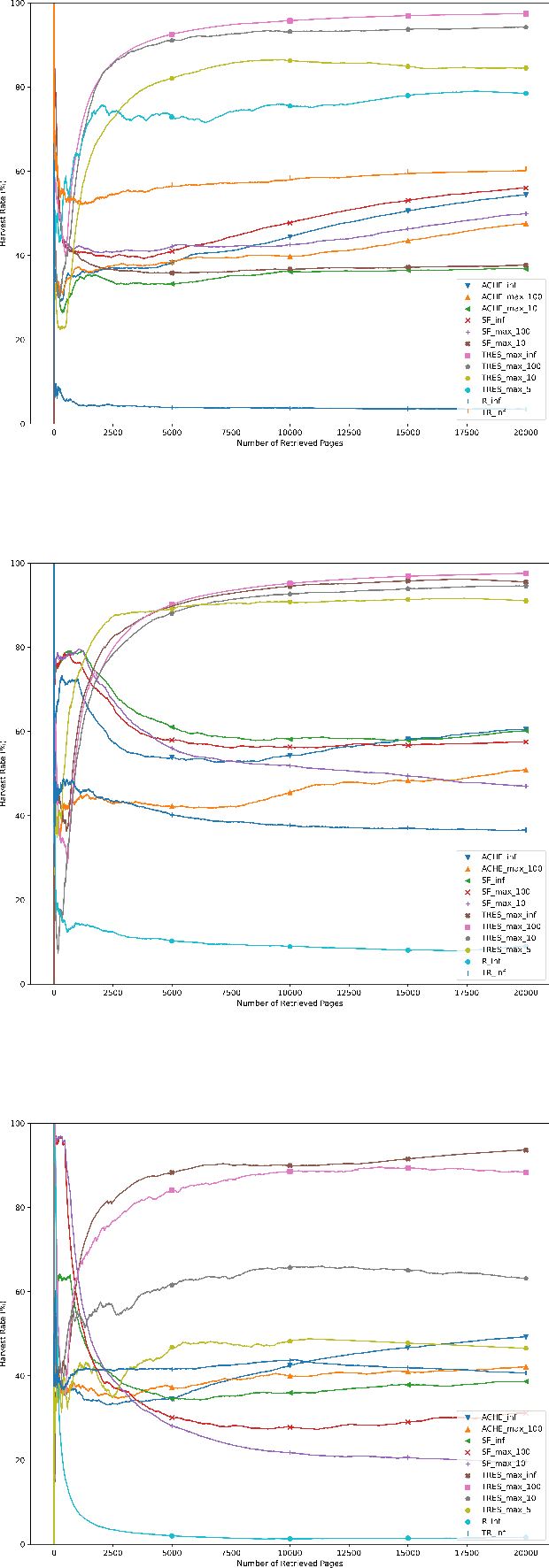
A focused crawler aims at discovering as many web pages relevant to a target topic as possible, while avoiding irrelevant ones; i.e. maximizing the harvest rate. Reinforcement Learning (RL) has been utilized to optimize the crawling process, yet it deals with huge state and action spaces, which can constitute a serious challenge. In this paper, we propose TRES, an end-to-end RL-empowered framework for focused crawling. Unlike other approaches, we properly model a crawling environment as a Markov Decision Process, by representing the state as a subgraph of the Web and actions as its expansion edges. TRES adopts a keyword expansion strategy based on the cosine similarity of keyword embeddings. To learn a reward function, we propose a deep neural network, called KwBiLSTM, leveraging the discovered keywords. To reduce the time complexity of selecting a best action, we propose Tree-Frontier, a two-fold decision tree, which also speeds up training by discretizing the state and action spaces. Experimentally, we show that TRES outperforms state-of-the-art methods in terms of harvest rate by at least 58%, while it has competitive results in the domain maximization. Our implementation code can be found on https://github.com/ddaedalus/TRES.
A study of text representations in Hate Speech Detection
Feb 08, 2021

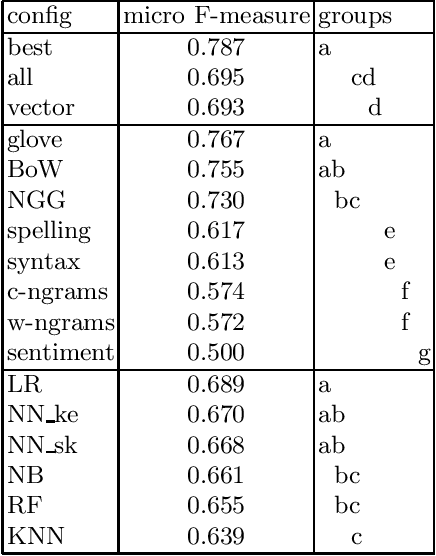
The pervasiveness of the Internet and social media have enabled the rapid and anonymous spread of Hate Speech content on microblogging platforms such as Twitter. Current EU and US legislation against hateful language, in conjunction with the large amount of data produced in these platforms has led to automatic tools being a necessary component of the Hate Speech detection task and pipeline. In this study, we examine the performance of several, diverse text representation techniques paired with multiple classification algorithms, on the automatic Hate Speech detection and abusive language discrimination task. We perform an experimental evaluation on binary and multiclass datasets, paired with significance testing. Our results show that simple hate-keyword frequency features (BoW) work best, followed by pre-trained word embeddings (GLoVe) as well as N-gram graphs (NGGs): a graph-based representation which proved to produce efficient, very low-dimensional but rich features for this task. A combination of these representations paired with Logistic Regression or 3-layer neural network classifiers achieved the best detection performance, in terms of micro and macro F-measure.
MUDOS-NG: Multi-document Summaries Using N-gram Graphs
Dec 09, 2010

This report describes the MUDOS-NG summarization system, which applies a set of language-independent and generic methods for generating extractive summaries. The proposed methods are mostly combinations of simple operators on a generic character n-gram graph representation of texts. This work defines the set of used operators upon n-gram graphs and proposes using these operators within the multi-document summarization process in such subtasks as document analysis, salient sentence selection, query expansion and redundancy control. Furthermore, a novel chunking methodology is used, together with a novel way to assign concepts to sentences for query expansion. The experimental results of the summarization system, performed upon widely used corpora from the Document Understanding and the Text Analysis Conferences, are promising and provide evidence for the potential of the generic methods introduced. This work aims to designate core methods exploiting the n-gram graph representation, providing the basis for more advanced summarization systems.