 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Oversmoothing through Informed Weight Initialization in Graph Neural Networks
Oct 31, 2024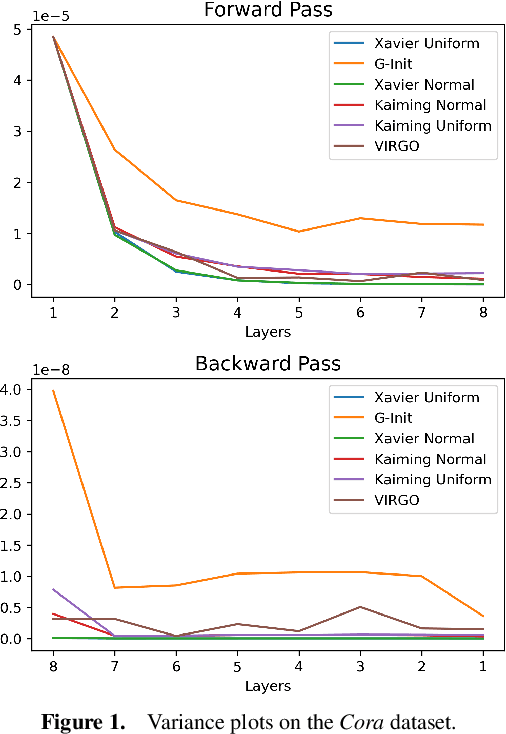
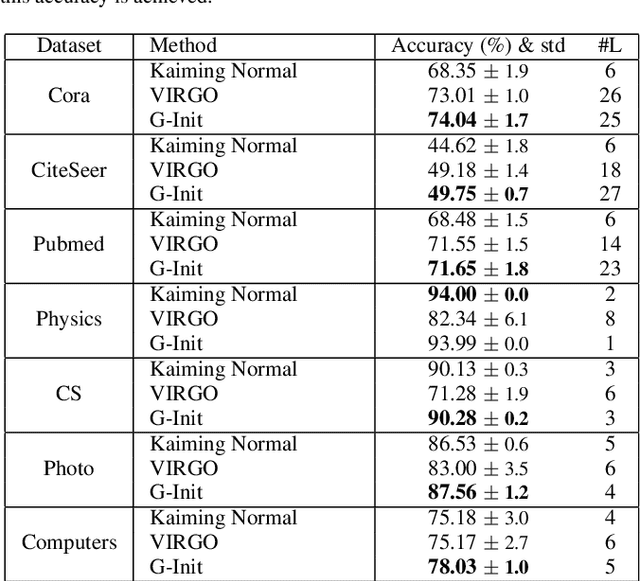
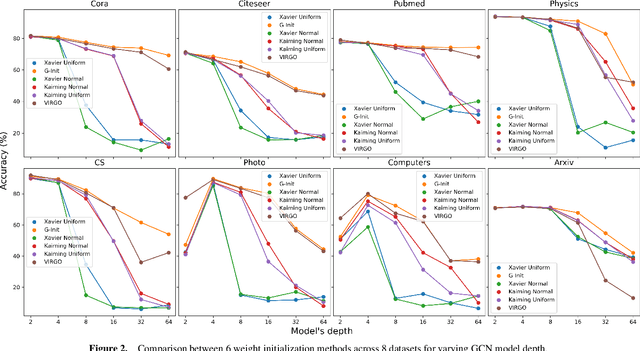

In this work, we generalize the ideas of Kaiming initialization to Graph Neural Networks (GNNs) and propose a new scheme (G-Init) that reduces oversmoothing, leading to very good results in node and graph classification tasks. GNNs are commonly initialized using methods designed for other types of Neural Networks, overlooking the underlying graph topology. We analyze theoretically the variance of signals flowing forward and gradients flowing backward in the class of convolutional GNNs. We then simplify our analysis to the case of the GCN and propose a new initialization method. Our results indicate that the new method (G-Init) reduces oversmoothing in deep GNNs, facilitating their effective use. Experimental validation supports our theoretical findings, demonstrating the advantages of deep networks in scenarios with no feature information for unlabeled nodes (i.e., ``cold start'' scenario).
Partially Trained Graph Convolutional Networks Resist Oversmoothing
Oct 17, 2024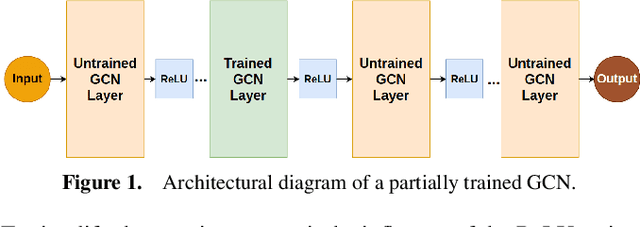
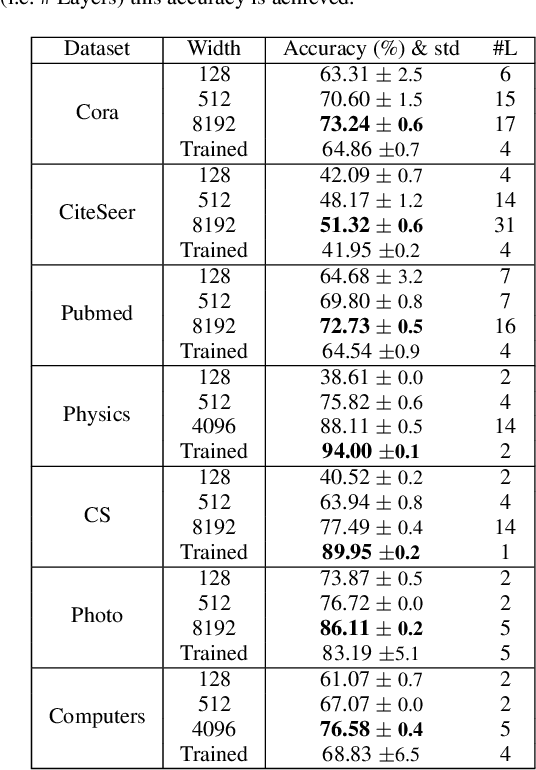


In this work we investigate an observation made by Kipf \& Welling, who suggested that untrained GCNs can generate meaningful node embeddings. In particular, we investigate the effect of training only a single layer of a GCN, while keeping the rest of the layers frozen. We propose a basis on which the effect of the untrained layers and their contribution to the generation of embeddings can be predicted. Moreover, we show that network width influences the dissimilarity of node embeddings produced after the initial node features pass through the untrained part of the model. Additionally, we establish a connection between partially trained GCNs and oversmoothing, showing that they are capable of reducing it. We verify our theoretical results experimentally and show the benefits of using deep networks that resist oversmoothing, in a ``cold start'' scenario, where there is a lack of feature information for unlabeled nodes.
Tree-based Focused Web Crawling with Reinforcement Learning
Dec 12, 2021

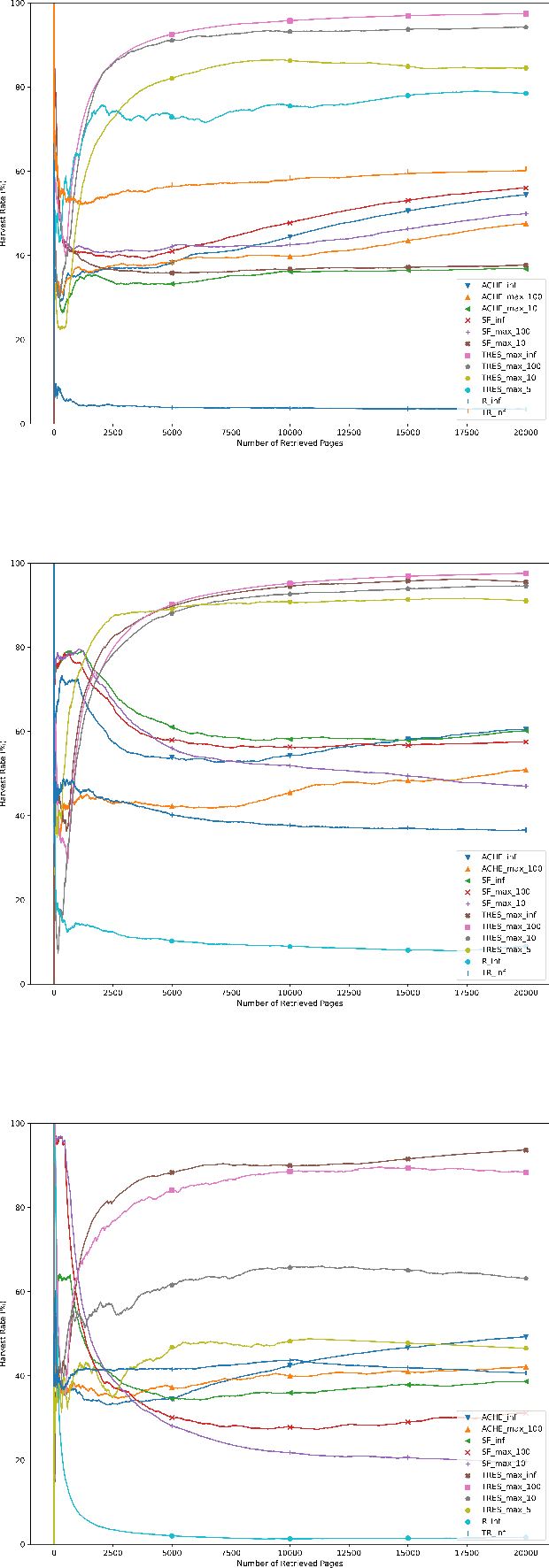
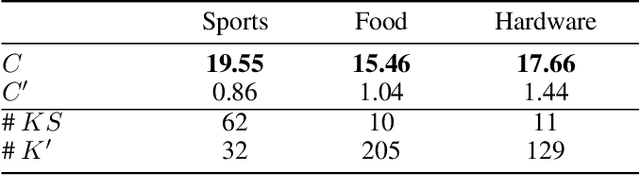
A focused crawler aims at discovering as many web pages relevant to a target topic as possible, while avoiding irrelevant ones; i.e. maximizing the harvest rate. Reinforcement Learning (RL) has been utilized to optimize the crawling process, yet it deals with huge state and action spaces, which can constitute a serious challenge. In this paper, we propose TRES, an end-to-end RL-empowered framework for focused crawling. Unlike other approaches, we properly model a crawling environment as a Markov Decision Process, by representing the state as a subgraph of the Web and actions as its expansion edges. TRES adopts a keyword expansion strategy based on the cosine similarity of keyword embeddings. To learn a reward function, we propose a deep neural network, called KwBiLSTM, leveraging the discovered keywords. To reduce the time complexity of selecting a best action, we propose Tree-Frontier, a two-fold decision tree, which also speeds up training by discretizing the state and action spaces. Experimentally, we show that TRES outperforms state-of-the-art methods in terms of harvest rate by at least 58%, while it has competitive results in the domain maximization. Our implementation code can be found on https://github.com/ddaedalus/TRES.