 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Err is AI : A Case Study Informing LLM Flaw Reporting Practices
Oct 15, 2024



In August of 2024, 495 hackers generated evaluations in an open-ended bug bounty targeting the Open Language Model (OLMo) from The Allen Institute for AI. A vendor panel staffed by representatives of OLMo's safety program adjudicated changes to OLMo's documentation and awarded cash bounties to participants who successfully demonstrated a need for public disclosure clarifying the intent, capacities, and hazards of model deployment. This paper presents a collection of lessons learned, illustrative of flaw reporting best practices intended to reduce the likelihood of incidents and produce safer large language models (LLMs). These include best practices for safety reporting processes, their artifacts, and safety program staffing.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024
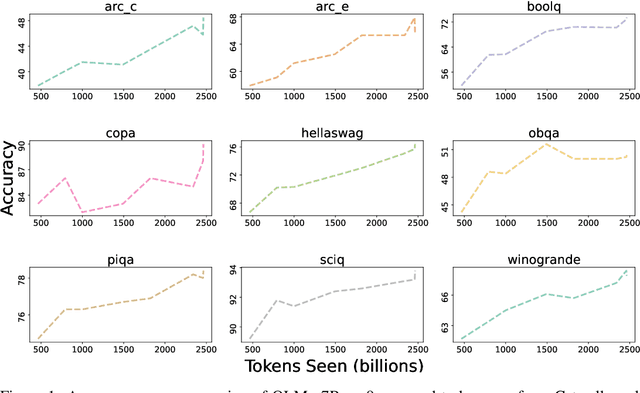
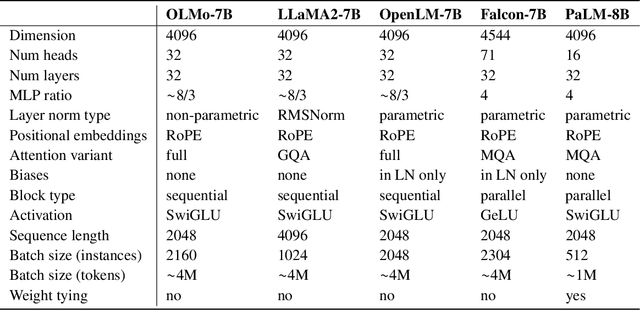
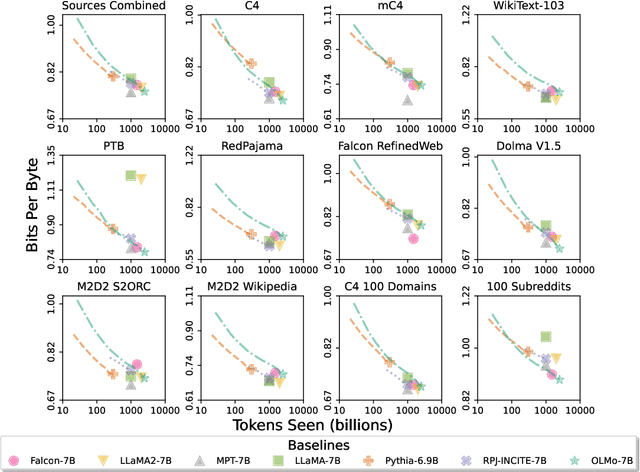
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Laplacian ICP for Progressive Registration of 3D Human Head Meshes
Feb 04, 2023
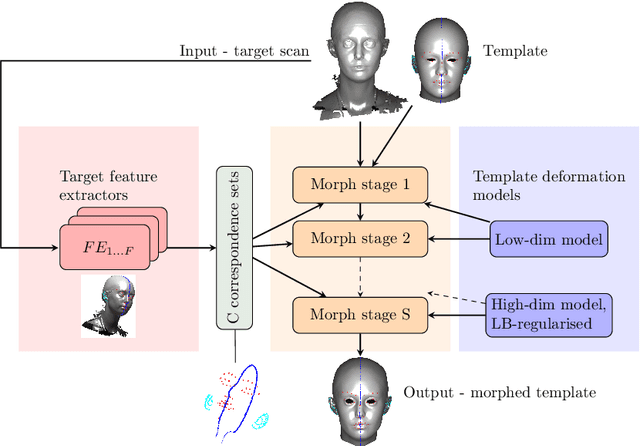

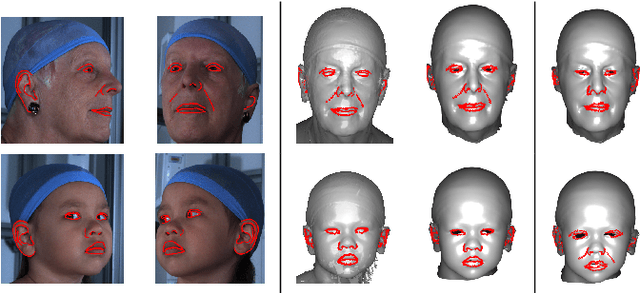
We present a progressive 3D registration framework that is a highly-efficient variant of classical non-rigid Iterative Closest Points (N-ICP). Since it uses the Laplace-Beltrami operator for deformation regularisation, we view the overall process as Laplacian ICP (L-ICP). This exploits a `small deformation per iteration' assumption and is progressively coarse-to-fine, employing an increasingly flexible deformation model, an increasing number of correspondence sets, and increasingly sophisticated correspondence estimation. Correspondence matching is only permitted within predefined vertex subsets derived from domain-specific feature extractors. Additionally, we present a new benchmark and a pair of evaluation metrics for 3D non-rigid registration, based on annotation transfer. We use this to evaluate our framework on a publicly-available dataset of 3D human head scans (Headspace). The method is robust and only requires a small fraction of the computation time compared to the most popular classical approach, yet has comparable registration performance.
* 7 pages, 6 figures