 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeachingCoach: A Fine-Tuned Scaffolding Chatbot for Instructional Guidance to Instructors
Mar 18, 2026Higher education instructors often lack timely and pedagogically grounded support, as scalable instructional guidance remains limited and existing tools rely on generic chatbot advice or non-scalable teaching center human-human consultations. We present TeachingCoach, a pedagogically grounded chatbot designed to support instructor professional development through real-time, conversational guidance. TeachingCoach is built on a data-centric pipeline that extracts pedagogical rules from educational resources and uses synthetic dialogue generation to fine-tune a specialized language model that guides instructors through problem identification, diagnosis, and strategy development. Expert evaluations show TeachingCoach produces clearer, more reflective, and more responsive guidance than a GPT-4o mini baseline, while a user study with higher education instructors highlights trade-offs between conversational depth and interaction efficiency. Together, these results demonstrate that pedagogically grounded, synthetic data driven chatbots can improve instructional support and offer a scalable design approach for future instructional chatbot systems.
Automated Benchmark Generation from Domain Guidelines Informed by Bloom's Taxonomy
Jan 28, 2026Open-ended question answering (QA) evaluates a model's ability to perform contextualized reasoning beyond factual recall. This challenge is especially acute in practice-based domains, where knowledge is procedural and grounded in professional judgment, while most existing LLM benchmarks depend on pre-existing human exam datasets that are often unavailable in such settings. We introduce a framework for automated benchmark generation from expert-authored guidelines informed by Bloom's Taxonomy. It converts expert practices into implicit violation-based scenarios and expands them into auto-graded multiple-choice questions (MCQs) and multi-turn dialogues across four cognitive levels, enabling deterministic, reproducible, and scalable evaluation. Applied to three applied domains: teaching, dietetics, and caregiving, we find differences between model and human-like reasoning: LLMs sometimes perform relatively better on higher-order reasoning (Analyze) but fail more frequently on lower-level items (Remember). We produce large-scale, psychometrically informed benchmarks that surface these non-intuitive model behaviors and enable evaluation of contextualized reasoning in real-world settings.
Recipe2Vec: Multi-modal Recipe Representation Learning with Graph Neural Networks
May 24, 2022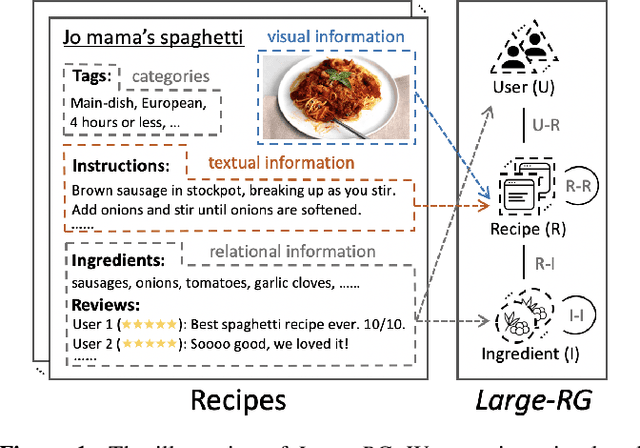
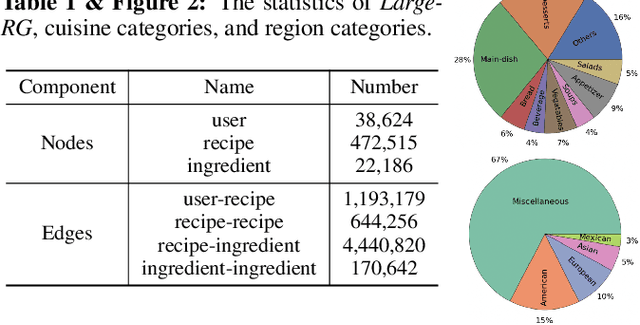
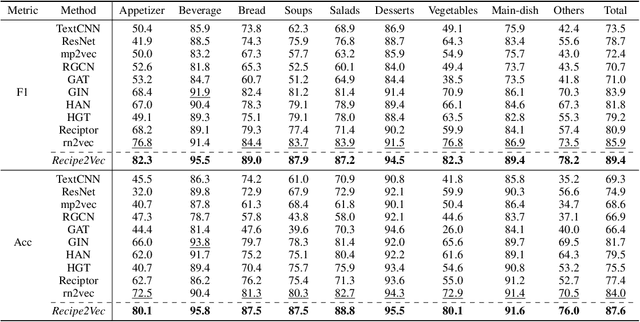
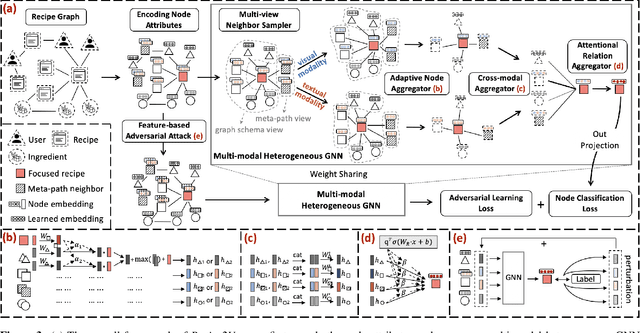
Learning effective recipe representations is essential in food studies. Unlike what has been developed for image-based recipe retrieval or learning structural text embeddings, the combined effect of multi-modal information (i.e., recipe images, text, and relation data) receives less attention. In this paper, we formalize the problem of multi-modal recipe representation learning to integrate the visual, textual, and relational information into recipe embeddings. In particular, we first present Large-RG, a new recipe graph data with over half a million nodes, making it the largest recipe graph to date. We then propose Recipe2Vec, a novel graph neural network based recipe embedding model to capture multi-modal information. Additionally, we introduce an adversarial attack strategy to ensure stable learning and improve performance. Finally, we design a joint objective function of node classification and adversarial learning to optimize the model. Extensive experiments demonstrate that Recipe2Vec outperforms state-of-the-art baselines on two classic food study tasks, i.e., cuisine category classification and region prediction. Dataset and codes are available at https://github.com/meettyj/Recipe2Vec.
RecipeRec: A Heterogeneous Graph Learning Model for Recipe Recommendation
May 24, 2022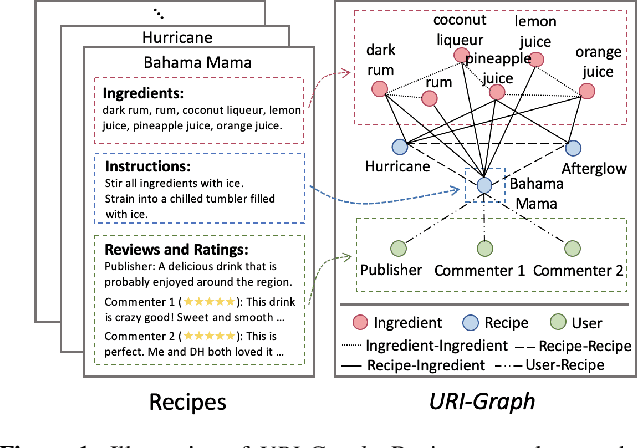
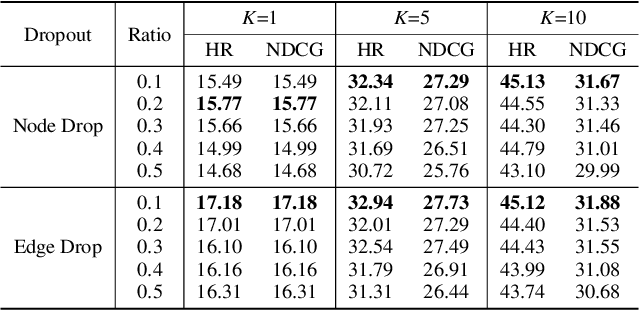
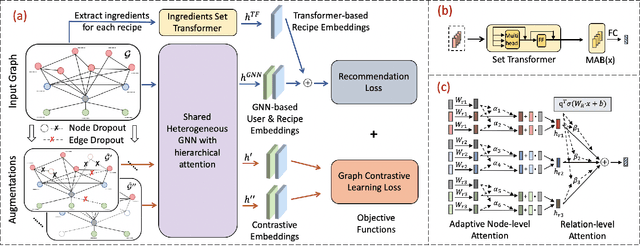
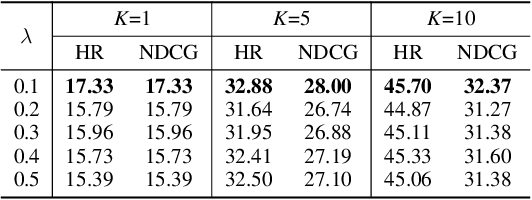
Recipe recommendation systems play an essential role in helping people decide what to eat. Existing recipe recommendation systems typically focused on content-based or collaborative filtering approaches, ignoring the higher-order collaborative signal such as relational structure information among users, recipes and food items. In this paper, we formalize the problem of recipe recommendation with graphs to incorporate the collaborative signal into recipe recommendation through graph modeling. In particular, we first present URI-Graph, a new and large-scale user-recipe-ingredient graph. We then propose RecipeRec, a novel heterogeneous graph learning model for recipe recommendation. The proposed model can capture recipe content and collaborative signal through a heterogeneous graph neural network with hierarchical attention and an ingredient set transformer. We also introduce a graph contrastive augmentation strategy to extract informative graph knowledge in a self-supervised manner. Finally, we design a joint objective function of recommendation and contrastive learning to optimize the model. Extensive experiments demonstrate that RecipeRec outperforms state-of-the-art methods for recipe recommendation. Dataset and codes are available at https://github.com/meettyj/RecipeRec.
Factoring Exogenous State for Model-Free Monte Carlo
Nov 03, 2017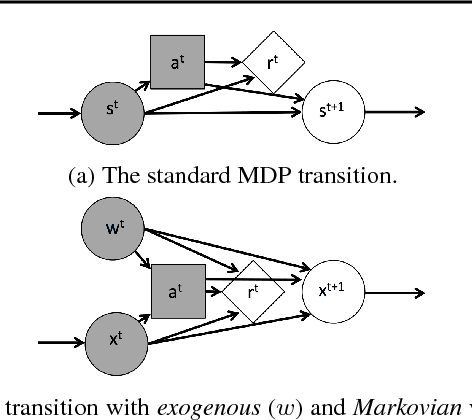
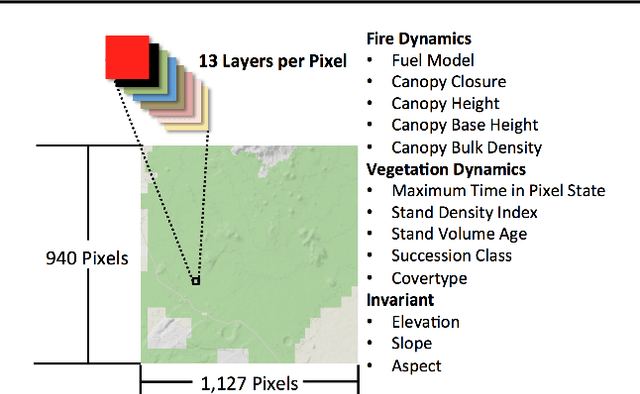
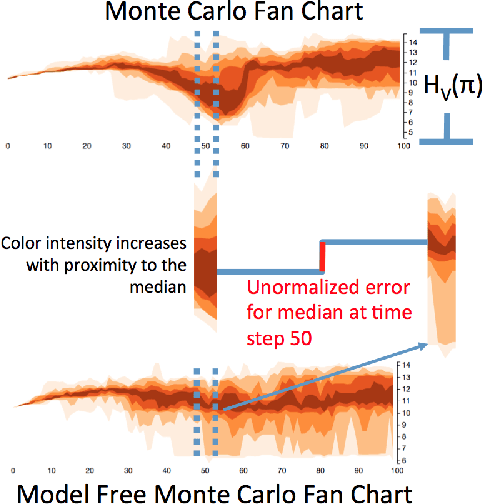

Policy analysts wish to visualize a range of policies for large simulator-defined Markov Decision Processes (MDPs). One visualization approach is to invoke the simulator to generate on-policy trajectories and then visualize those trajectories. When the simulator is expensive, this is not practical, and some method is required for generating trajectories for new policies without invoking the simulator. The method of Model-Free Monte Carlo (MFMC) can do this by stitching together state transitions for a new policy based on previously-sampled trajectories from other policies. This "off-policy Monte Carlo simulation" method works well when the state space has low dimension but fails as the dimension grows. This paper describes a method for factoring out some of the state and action variables so that MFMC can work in high-dimensional MDPs. The new method, MFMCi, is evaluated on a very challenging wildfire management MDP.
Fast Optimization of Wildfire Suppression Policies with SMAC
Mar 28, 2017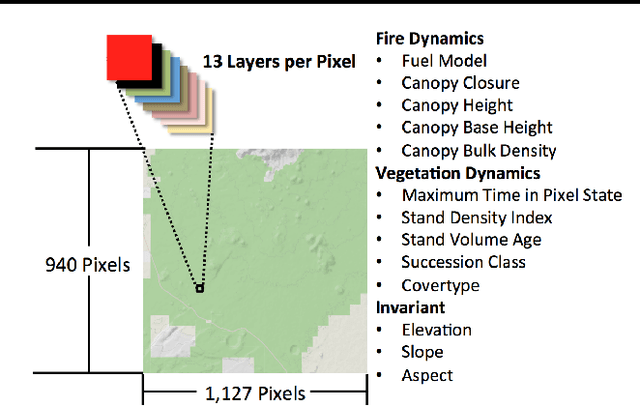
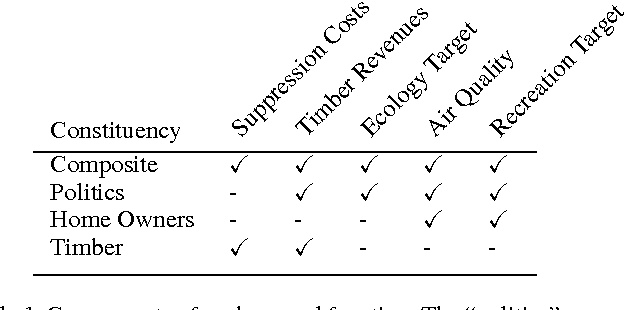
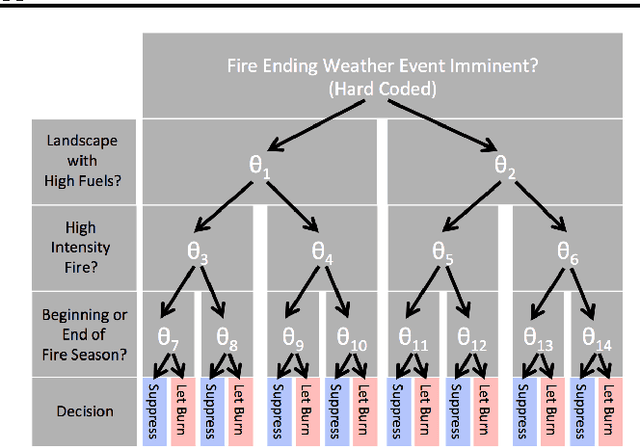
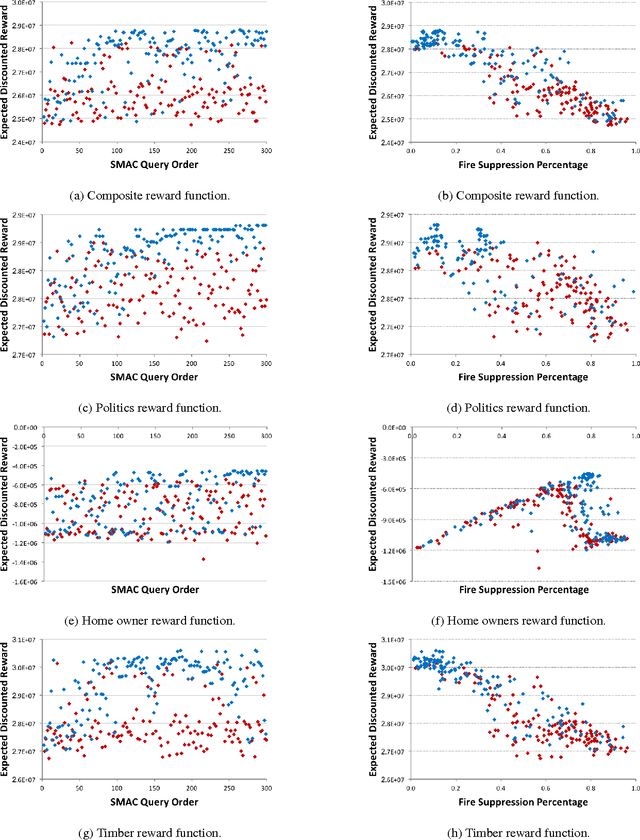
Managers of US National Forests must decide what policy to apply for dealing with lightning-caused wildfires. Conflicts among stakeholders (e.g., timber companies, home owners, and wildlife biologists) have often led to spirited political debates and even violent eco-terrorism. One way to transform these conflicts into multi-stakeholder negotiations is to provide a high-fidelity simulation environment in which stakeholders can explore the space of alternative policies and understand the tradeoffs therein. Such an environment needs to support fast optimization of MDP policies so that users can adjust reward functions and analyze the resulting optimal policies. This paper assesses the suitability of SMAC---a black-box empirical function optimization algorithm---for rapid optimization of MDP policies. The paper describes five reward function components and four stakeholder constituencies. It then introduces a parameterized class of policies that can be easily understood by the stakeholders. SMAC is applied to find the optimal policy in this class for the reward functions of each of the stakeholder constituencies. The results confirm that SMAC is able to rapidly find good policies that make sense from the domain perspective. Because the full-fidelity forest fire simulator is far too expensive to support interactive optimization, SMAC is applied to a surrogate model constructed from a modest number of runs of the full-fidelity simulator. To check the quality of the SMAC-optimized policies, the policies are evaluated on the full-fidelity simulator. The results confirm that the surrogate values estimates are valid. This is the first successful optimization of wildfire management policies using a full-fidelity simulation. The same methodology should be applicable to other contentious natural resource management problems where high-fidelity simulation is extremely expensive.