 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre we making much progress? Revisiting chemical reaction yield prediction from an imbalanced regression perspective
Feb 06, 2024



The yield of a chemical reaction quantifies the percentage of the target product formed in relation to the reactants consumed during the chemical reaction. Accurate yield prediction can guide chemists toward selecting high-yield reactions during synthesis planning, offering valuable insights before dedicating time and resources to wet lab experiments. While recent advancements in yield prediction have led to overall performance improvement across the entire yield range, an open challenge remains in enhancing predictions for high-yield reactions, which are of greater concern to chemists. In this paper, we argue that the performance gap in high-yield predictions results from the imbalanced distribution of real-world data skewed towards low-yield reactions, often due to unreacted starting materials and inherent ambiguities in the reaction processes. Despite this data imbalance, existing yield prediction methods continue to treat different yield ranges equally, assuming a balanced training distribution. Through extensive experiments on three real-world yield prediction datasets, we emphasize the urgent need to reframe reaction yield prediction as an imbalanced regression problem. Finally, we demonstrate that incorporating simple cost-sensitive re-weighting methods can significantly enhance the performance of yield prediction models on underrepresented high-yield regions.
HetGPT: Harnessing the Power of Prompt Tuning in Pre-Trained Heterogeneous Graph Neural Networks
Oct 23, 2023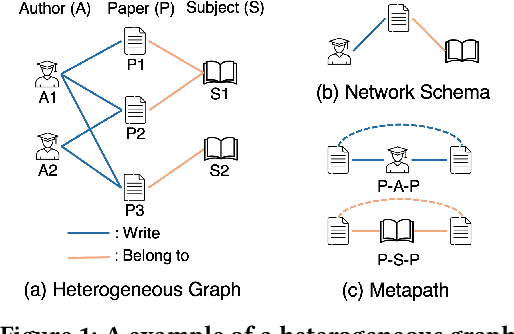
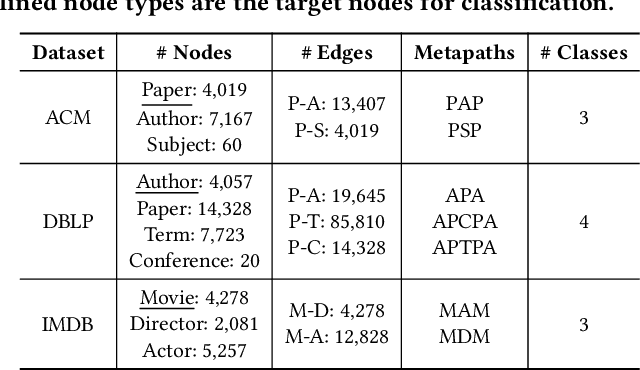
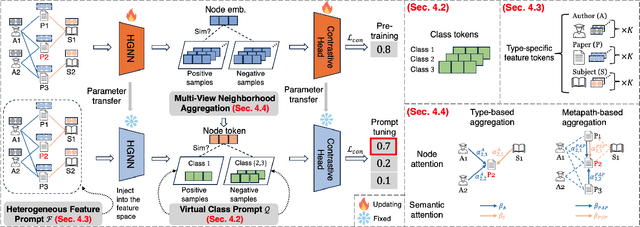
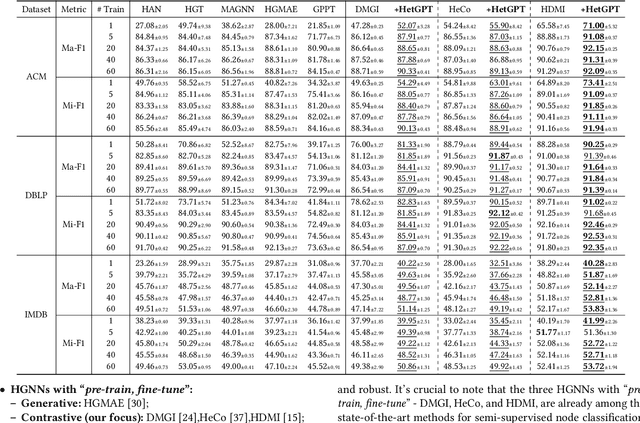
Graphs have emerged as a natural choice to represent and analyze the intricate patterns and rich information of the Web, enabling applications such as online page classification and social recommendation. The prevailing "pre-train, fine-tune" paradigm has been widely adopted in graph machine learning tasks, particularly in scenarios with limited labeled nodes. However, this approach often exhibits a misalignment between the training objectives of pretext tasks and those of downstream tasks. This gap can result in the "negative transfer" problem, wherein the knowledge gained from pre-training adversely affects performance in the downstream tasks. The surge in prompt-based learning within Natural Language Processing (NLP) suggests the potential of adapting a "pre-train, prompt" paradigm to graphs as an alternative. However, existing graph prompting techniques are tailored to homogeneous graphs, neglecting the inherent heterogeneity of Web graphs. To bridge this gap, we propose HetGPT, a general post-training prompting framework to improve the predictive performance of pre-trained heterogeneous graph neural networks (HGNNs). The key is the design of a novel prompting function that integrates a virtual class prompt and a heterogeneous feature prompt, with the aim to reformulate downstream tasks to mirror pretext tasks. Moreover, HetGPT introduces a multi-view neighborhood aggregation mechanism, capturing the complex neighborhood structure in heterogeneous graphs. Extensive experiments on three benchmark datasets demonstrate HetGPT's capability to enhance the performance of state-of-the-art HGNNs on semi-supervised node classification.
Class-Imbalanced Learning on Graphs: A Survey
Apr 09, 2023The rapid advancement in data-driven research has increased the demand for effective graph data analysis. However, real-world data often exhibits class imbalance, leading to poor performance of machine learning models. To overcome this challenge, class-imbalanced learning on graphs (CILG) has emerged as a promising solution that combines the strengths of graph representation learning and class-imbalanced learning. In recent years, significant progress has been made in CILG. Anticipating that such a trend will continue, this survey aims to offer a comprehensive understanding of the current state-of-the-art in CILG and provide insights for future research directions. Concerning the former, we introduce the first taxonomy of existing work and its connection to existing imbalanced learning literature. Concerning the latter, we critically analyze recent work in CILG and discuss urgent lines of inquiry within the topic. Moreover, we provide a continuously maintained reading list of papers and code at https://github.com/yihongma/CILG-Papers.
RESAM: Requirements Elicitation and Specification for Deep-Learning Anomaly Models with Applications to UAV Flight Controllers
Jul 18, 2022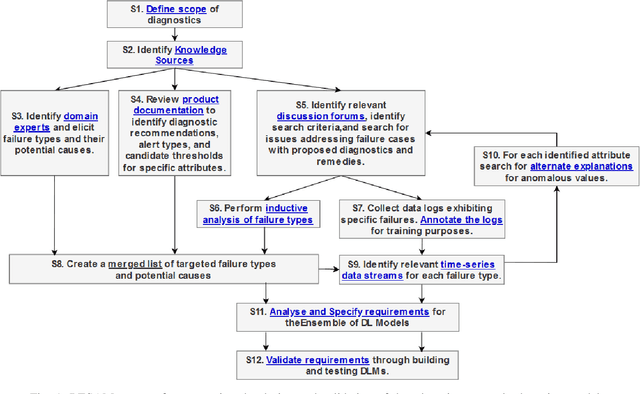



CyberPhysical systems (CPS) must be closely monitored to identify and potentially mitigate emergent problems that arise during their routine operations. However, the multivariate time-series data which they typically produce can be complex to understand and analyze. While formal product documentation often provides example data plots with diagnostic suggestions, the sheer diversity of attributes, critical thresholds, and data interactions can be overwhelming to non-experts who subsequently seek help from discussion forums to interpret their data logs. Deep learning models, such as Long Short-term memory (LSTM) networks can be used to automate these tasks and to provide clear explanations of diverse anomalies detected in real-time multivariate data-streams. In this paper we present RESAM, a requirements process that integrates knowledge from domain experts, discussion forums, and formal product documentation, to discover and specify requirements and design definitions in the form of time-series attributes that contribute to the construction of effective deep learning anomaly detectors. We present a case-study based on a flight control system for small Uncrewed Aerial Systems and demonstrate that its use guides the construction of effective anomaly detection models whilst also providing underlying support for explainability. RESAM is relevant to domains in which open or closed online forums provide discussion support for log analysis.
Recipe2Vec: Multi-modal Recipe Representation Learning with Graph Neural Networks
May 24, 2022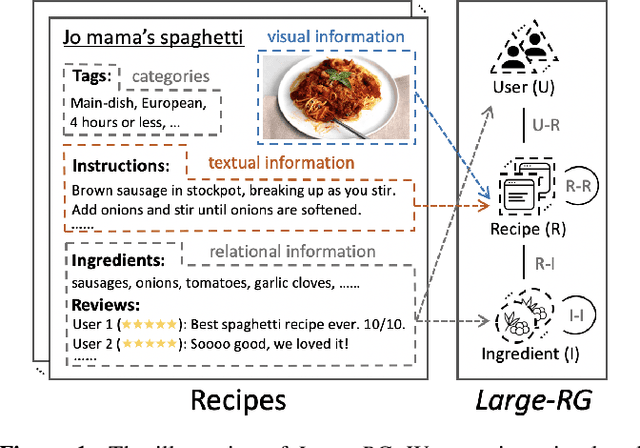
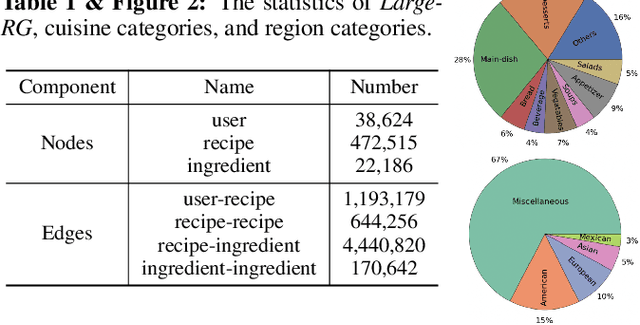
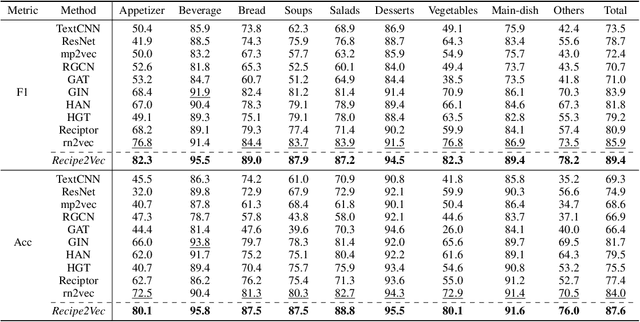
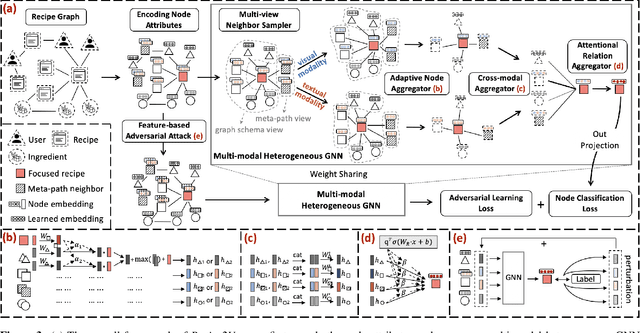
Learning effective recipe representations is essential in food studies. Unlike what has been developed for image-based recipe retrieval or learning structural text embeddings, the combined effect of multi-modal information (i.e., recipe images, text, and relation data) receives less attention. In this paper, we formalize the problem of multi-modal recipe representation learning to integrate the visual, textual, and relational information into recipe embeddings. In particular, we first present Large-RG, a new recipe graph data with over half a million nodes, making it the largest recipe graph to date. We then propose Recipe2Vec, a novel graph neural network based recipe embedding model to capture multi-modal information. Additionally, we introduce an adversarial attack strategy to ensure stable learning and improve performance. Finally, we design a joint objective function of node classification and adversarial learning to optimize the model. Extensive experiments demonstrate that Recipe2Vec outperforms state-of-the-art baselines on two classic food study tasks, i.e., cuisine category classification and region prediction. Dataset and codes are available at https://github.com/meettyj/Recipe2Vec.
Learning Attribute-Structure Co-Evolutions in Dynamic Graphs
Jul 25, 2020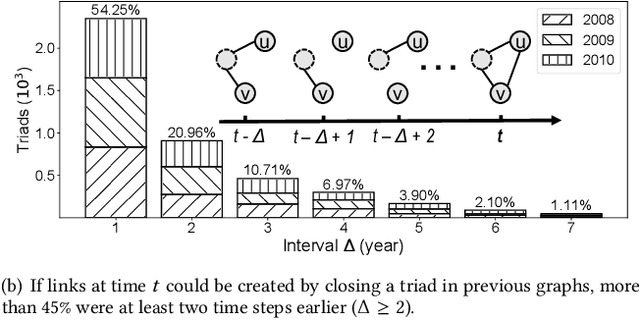
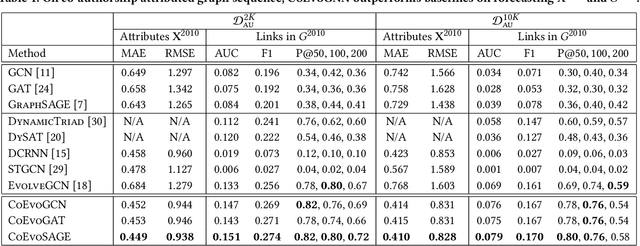
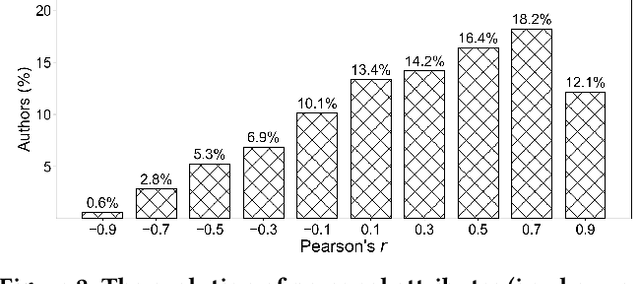
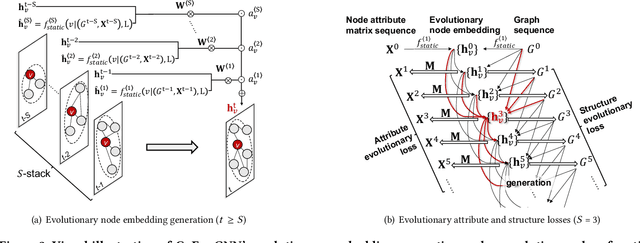
Most graph neural network models learn embeddings of nodes in static attributed graphs for predictive analysis. Recent attempts have been made to learn temporal proximity of the nodes. We find that real dynamic attributed graphs exhibit complex co-evolution of node attributes and graph structure. Learning node embeddings for forecasting change of node attributes and birth and death of links over time remains an open problem. In this work, we present a novel framework called CoEvoGNN for modeling dynamic attributed graph sequence. It preserves the impact of earlier graphs on the current graph by embedding generation through the sequence. It has a temporal self-attention mechanism to model long-range dependencies in the evolution. Moreover, CoEvoGNN optimizes model parameters jointly on two dynamic tasks, attribute inference and link prediction over time. So the model can capture the co-evolutionary patterns of attribute change and link formation. This framework can adapt to any graph neural algorithms so we implemented and investigated three methods based on it: CoEvoGCN, CoEvoGAT, and CoEvoSAGE. Experiments demonstrate the framework (and its methods) outperform strong baselines on predicting an entire unseen graph snapshot of personal attributes and interpersonal links in dynamic social graphs and financial graphs.