 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Task Planning via Graph-Informed Action Generation with Large Lanaguage Model
Jan 29, 2026While Large Language Models (LLMs) have demonstrated strong zero-shot reasoning capabilities, their deployment as embodied agents still faces fundamental challenges in long-horizon planning. Unlike open-ended text generation, embodied agents must decompose high-level intent into actionable sub-goals while strictly adhering to the logic of a dynamic, observed environment. Standard LLM planners frequently fail to maintain strategy coherence over extended horizons due to context window limitation or hallucinate transitions that violate constraints. We propose GiG, a novel planning framework that structures embodied agents' memory using a Graph-in-Graph architecture. Our approach employs a Graph Neural Network (GNN) to encode environmental states into embeddings, organizing these embeddings into action-connected execution trace graphs within an experience memory bank. By clustering these graph embeddings, the framework enables retrieval of structure-aware priors, allowing agents to ground current decisions in relevant past structural patterns. Furthermore, we introduce a novel bounded lookahead module that leverages symbolic transition logic to enhance the agents' planning capabilities through the grounded action projection. We evaluate our framework on three embodied planning benchmarks-Robotouille Synchronous, Robotouille Asynchronous, and ALFWorld. Our method outperforms state-of-the-art baselines, achieving Pass@1 performance gains of up to 22% on Robotouille Synchronous, 37% on Asynchronous, and 15% on ALFWorld with comparable or lower computational cost.
Graph-DPEP: Decomposed Plug and Ensemble Play for Few-Shot Document Relation Extraction with Graph-of-Thoughts Reasoning
Nov 05, 2024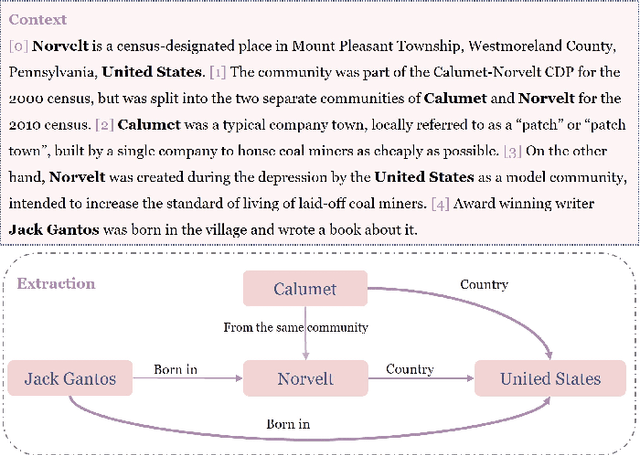

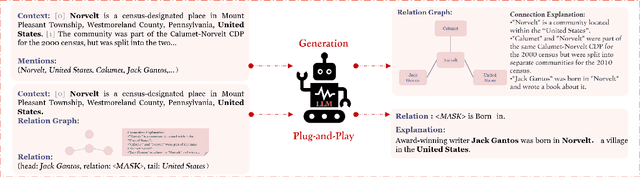
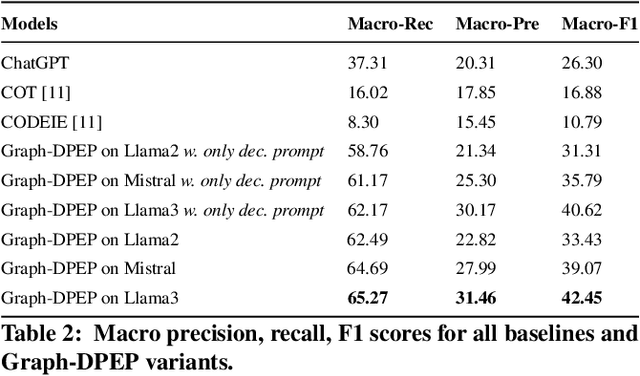
Large language models (LLMs) pre-trained on massive corpora have demonstrated impressive few-shot learning capability on many NLP tasks. Recasting an NLP task into a text-to-text generation task is a common practice so that generative LLMs can be prompted to resolve it. However, performing document-level relation extraction (DocRE) tasks with generative LLM models is still challenging due to the structured output format of DocRE, which complicates the conversion to plain text. Limited information available in few-shot samples and prompt instructions induce further difficulties and challenges in relation extraction for mentioned entities in a document. In this paper, we represent the structured output as a graph-style triplet rather than natural language expressions and leverage generative LLMs for the DocRE task. Our approach, the Graph-DPEP framework is grounded in the reasoning behind triplet explanation thoughts presented in natural language. In this framework, we first introduce a ``decomposed-plug" method for performing the generation from LLMs over prompts with type-space decomposition to alleviate the burden of distinguishing all relation types. Second, we employ a verifier for calibrating the generation and identifying overlooked query entity pairs. Third, we develop "ensemble-play", reapplying generation on the entire type list by leveraging the reasoning thoughts embedded in a sub-graph associated with the missing query pair to address the missingness issue. Through extensive comparisons with existing prompt techniques and alternative Language Models (LLMs), our framework demonstrates superior performance on publicly available benchmarks in experiments.
Enhancing Long Context Performance in LLMs Through Inner Loop Query Mechanism
Oct 11, 2024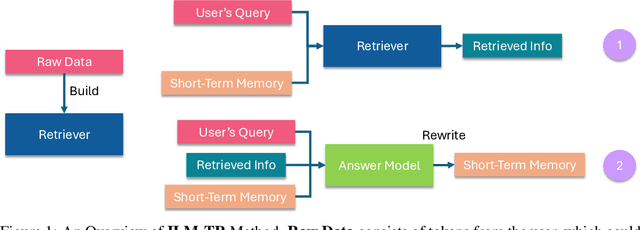
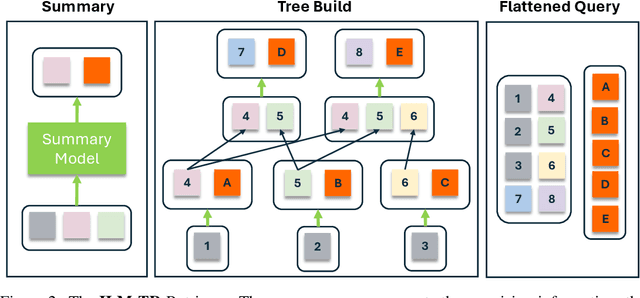
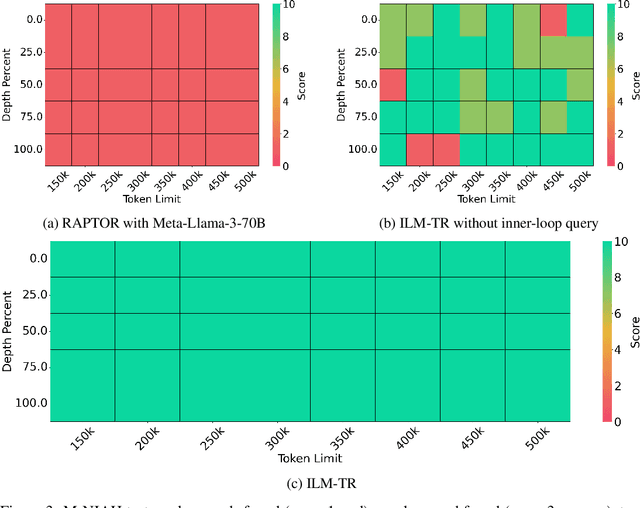
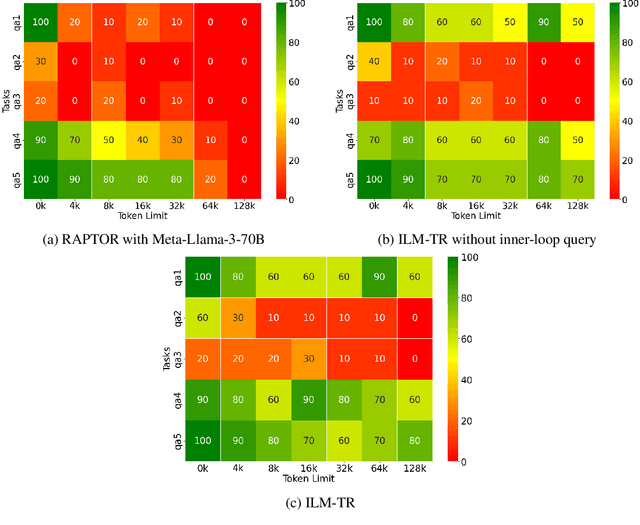
Transformers have a quadratic scaling of computational complexity with input size, which limits the input context window size of large language models (LLMs) in both training and inference. Meanwhile, retrieval-augmented generation (RAG) besed models can better handle longer contexts by using a retrieval system to filter out unnecessary information. However, most RAG methods only perform retrieval based on the initial query, which may not work well with complex questions that require deeper reasoning. We introduce a novel approach, Inner Loop Memory Augmented Tree Retrieval (ILM-TR), involving inner-loop queries, based not only on the query question itself but also on intermediate findings. At inference time, our model retrieves information from the RAG system, integrating data from lengthy documents at various levels of abstraction. Based on the information retrieved, the LLM generates texts stored in an area named Short-Term Memory (STM) which is then used to formulate the next query. This retrieval process is repeated until the text in STM converged. Our experiments demonstrate that retrieval with STM offers improvements over traditional retrieval-augmented LLMs, particularly in long context tests such as Multi-Needle In A Haystack (M-NIAH) and BABILong.
Fusion of regional and sparse attention in Vision Transformers
Jun 13, 2024Modern vision transformers leverage visually inspired local interaction between pixels through attention computed within window or grid regions, in contrast to the global attention employed in the original ViT. Regional attention restricts pixel interactions within specific regions, while sparse attention disperses them across sparse grids. These differing approaches pose a challenge between maintaining hierarchical relationships vs. capturing a global context. In this study, drawing inspiration from atrous convolution, we propose Atrous Attention, a blend of regional and sparse attention that dynamically integrates both local and global information while preserving hierarchical structures. Based on this, we introduce a versatile, hybrid vision transformer backbone called ACC-ViT, tailored for standard vision tasks. Our compact model achieves approximately 84% accuracy on ImageNet-1K with fewer than 28.5 million parameters, outperforming the state-of-the-art MaxViT by 0.42% while requiring 8.4% fewer parameters.
Modally Reduced Representation Learning of Multi-Lead ECG Signals through Simultaneous Alignment and Reconstruction
May 24, 2024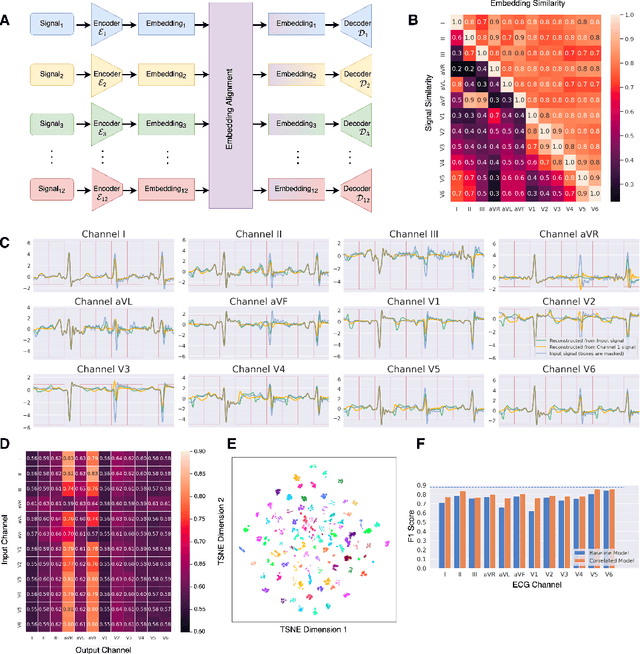
Electrocardiogram (ECG) signals, profiling the electrical activities of the heart, are used for a plethora of diagnostic applications. However, ECG systems require multiple leads or channels of signals to capture the complete view of the cardiac system, which limits their application in smartwatches and wearables. In this work, we propose a modally reduced representation learning method for ECG signals that is capable of generating channel-agnostic, unified representations for ECG signals. Through joint optimization of reconstruction and alignment, we ensure that the embeddings of the different channels contain an amalgamation of the overall information across channels while also retaining their specific information. On an independent test dataset, we generated highly correlated channel embeddings from different ECG channels, leading to a moderate approximation of the 12-lead signals from a single-channel embedding. Our generated embeddings can work as competent features for ECG signals for downstream tasks.
* Accepted as a Workshop Paper at TS4H@ICLR2024
ACC-ViT : Atrous Convolution's Comeback in Vision Transformers
Mar 07, 2024Transformers have elevated to the state-of-the-art vision architectures through innovations in attention mechanism inspired from visual perception. At present two classes of attentions prevail in vision transformers, regional and sparse attention. The former bounds the pixel interactions within a region; the latter spreads them across sparse grids. The opposing natures of them have resulted in a dilemma between either preserving hierarchical relation or attaining a global context. In this work, taking inspiration from atrous convolution, we introduce Atrous Attention, a fusion of regional and sparse attention, which can adaptively consolidate both local and global information, while maintaining hierarchical relations. As a further tribute to atrous convolution, we redesign the ubiquitous inverted residual convolution blocks with atrous convolution. Finally, we propose a generalized, hybrid vision transformer backbone, named ACC-ViT, following conventional practices for standard vision tasks. Our tiny version model achieves $\sim 84 \%$ accuracy on ImageNet-1K, with less than $28.5$ million parameters, which is $0.42\%$ improvement over state-of-the-art MaxViT while having $8.4\%$ less parameters. In addition, we have investigated the efficacy of ACC-ViT backbone under different evaluation settings, such as finetuning, linear probing, and zero-shot learning on tasks involving medical image analysis, object detection, and language-image contrastive learning. ACC-ViT is therefore a strong vision backbone, which is also competitive in mobile-scale versions, ideal for niche applications with small datasets.
HetGPT: Harnessing the Power of Prompt Tuning in Pre-Trained Heterogeneous Graph Neural Networks
Oct 23, 2023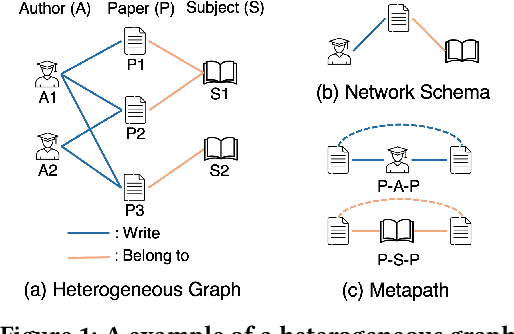
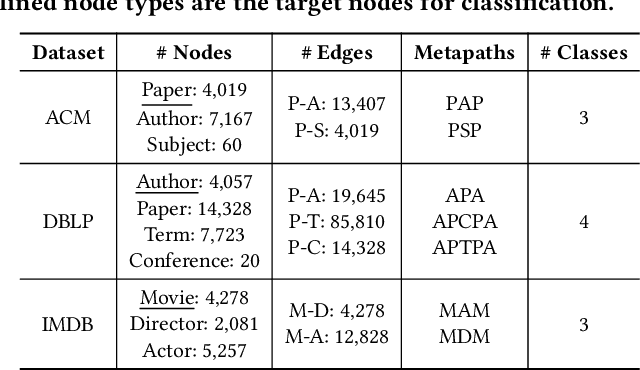
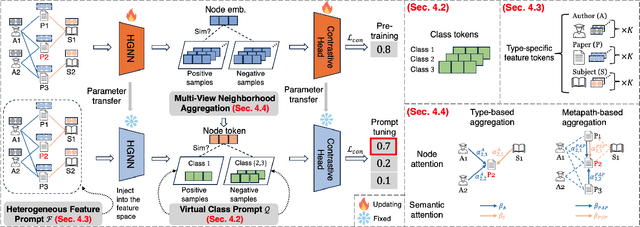
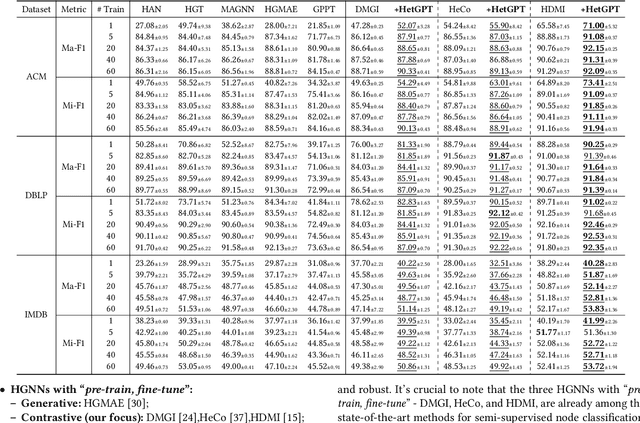
Graphs have emerged as a natural choice to represent and analyze the intricate patterns and rich information of the Web, enabling applications such as online page classification and social recommendation. The prevailing "pre-train, fine-tune" paradigm has been widely adopted in graph machine learning tasks, particularly in scenarios with limited labeled nodes. However, this approach often exhibits a misalignment between the training objectives of pretext tasks and those of downstream tasks. This gap can result in the "negative transfer" problem, wherein the knowledge gained from pre-training adversely affects performance in the downstream tasks. The surge in prompt-based learning within Natural Language Processing (NLP) suggests the potential of adapting a "pre-train, prompt" paradigm to graphs as an alternative. However, existing graph prompting techniques are tailored to homogeneous graphs, neglecting the inherent heterogeneity of Web graphs. To bridge this gap, we propose HetGPT, a general post-training prompting framework to improve the predictive performance of pre-trained heterogeneous graph neural networks (HGNNs). The key is the design of a novel prompting function that integrates a virtual class prompt and a heterogeneous feature prompt, with the aim to reformulate downstream tasks to mirror pretext tasks. Moreover, HetGPT introduces a multi-view neighborhood aggregation mechanism, capturing the complex neighborhood structure in heterogeneous graphs. Extensive experiments on three benchmark datasets demonstrate HetGPT's capability to enhance the performance of state-of-the-art HGNNs on semi-supervised node classification.
Envisioning a Next Generation Extended Reality Conferencing System with Efficient Photorealistic Human Rendering
Jun 28, 2023Meeting online is becoming the new normal. Creating an immersive experience for online meetings is a necessity towards more diverse and seamless environments. Efficient photorealistic rendering of human 3D dynamics is the core of immersive meetings. Current popular applications achieve real-time conferencing but fall short in delivering photorealistic human dynamics, either due to limited 2D space or the use of avatars that lack realistic interactions between participants. Recent advances in neural rendering, such as the Neural Radiance Field (NeRF), offer the potential for greater realism in metaverse meetings. However, the slow rendering speed of NeRF poses challenges for real-time conferencing. We envision a pipeline for a future extended reality metaverse conferencing system that leverages monocular video acquisition and free-viewpoint synthesis to enhance data and hardware efficiency. Towards an immersive conferencing experience, we explore an accelerated NeRF-based free-viewpoint synthesis algorithm for rendering photorealistic human dynamics more efficiently. We show that our algorithm achieves comparable rendering quality while performing training and inference 44.5% and 213% faster than state-of-the-art methods, respectively. Our exploration provides a design basis for constructing metaverse conferencing systems that can handle complex application scenarios, including dynamic scene relighting with customized themes and multi-user conferencing that harmonizes real-world people into an extended world.