 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjectTest: A Project-level LLM Unit Test Generation Benchmark and Impact of Error Fixing Mechanisms
Feb 11, 2025



Unit test generation has become a promising and important use case of LLMs. However, existing evaluation benchmarks for assessing LLM unit test generation capabilities focus on function- or class-level code rather than more practical and challenging project-level codebases. To address such limitation, we propose ProjectTest, a project-level benchmark for unit test generation covering Python, Java, and JavaScript. ProjectTest features 20 moderate-sized and high-quality projects per language. We evaluate nine frontier LLMs on ProjectTest and the results show that all frontier LLMs tested exhibit moderate performance on ProjectTest on Python and Java, highlighting the difficulty of ProjectTest. We also conduct a thorough error analysis, which shows that even frontier LLMs, such as Claude-3.5-Sonnet, have significant simple errors, including compilation and cascade errors. Motivated by this observation, we further evaluate all frontier LLMs under manual error-fixing and self-error-fixing scenarios to assess their potential when equipped with error-fixing mechanisms.
ProjectTest: A Project-level Unit Test Generation Benchmark and Impact of Error Fixing Mechanisms
Feb 10, 2025Unit test generation has become a promising and important use case of LLMs. However, existing evaluation benchmarks for assessing LLM unit test generation capabilities focus on function- or class-level code rather than more practical and challenging project-level codebases. To address such limitation, we propose ProjectTest, a project-level benchmark for unit test generation covering Python, Java, and JavaScript. ProjectTest features 20 moderate-sized and high-quality projects per language. We evaluate nine frontier LLMs on ProjectTest and the results show that all frontier LLMs tested exhibit moderate performance on ProjectTest on Python and Java, highlighting the difficulty of ProjectTest. We also conduct a thorough error analysis, which shows that even frontier LLMs, such as Claude-3.5-Sonnet, have significant simple errors, including compilation and cascade errors. Motivated by this observation, we further evaluate all frontier LLMs under manual error-fixing and self-error-fixing scenarios to assess their potential when equipped with error-fixing mechanisms.
Graph-DPEP: Decomposed Plug and Ensemble Play for Few-Shot Document Relation Extraction with Graph-of-Thoughts Reasoning
Nov 05, 2024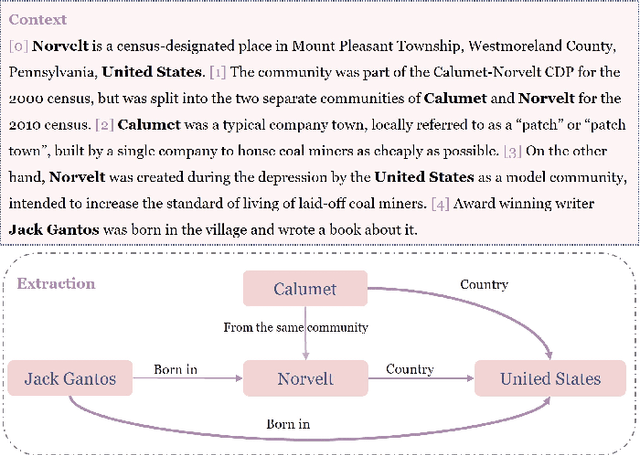

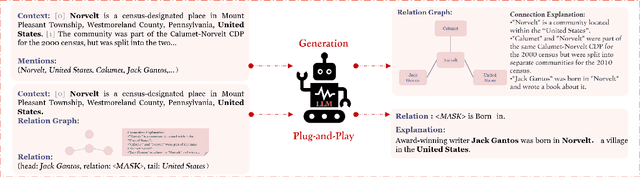
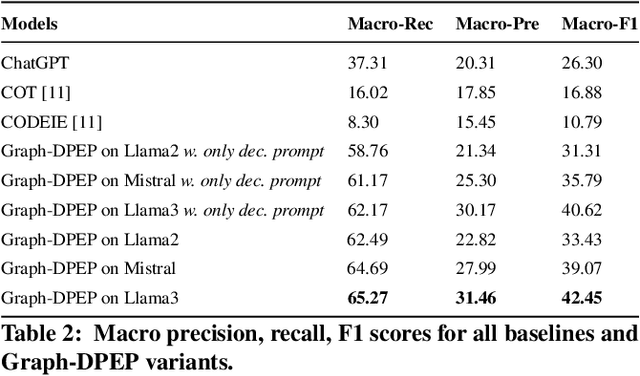
Large language models (LLMs) pre-trained on massive corpora have demonstrated impressive few-shot learning capability on many NLP tasks. Recasting an NLP task into a text-to-text generation task is a common practice so that generative LLMs can be prompted to resolve it. However, performing document-level relation extraction (DocRE) tasks with generative LLM models is still challenging due to the structured output format of DocRE, which complicates the conversion to plain text. Limited information available in few-shot samples and prompt instructions induce further difficulties and challenges in relation extraction for mentioned entities in a document. In this paper, we represent the structured output as a graph-style triplet rather than natural language expressions and leverage generative LLMs for the DocRE task. Our approach, the Graph-DPEP framework is grounded in the reasoning behind triplet explanation thoughts presented in natural language. In this framework, we first introduce a ``decomposed-plug" method for performing the generation from LLMs over prompts with type-space decomposition to alleviate the burden of distinguishing all relation types. Second, we employ a verifier for calibrating the generation and identifying overlooked query entity pairs. Third, we develop "ensemble-play", reapplying generation on the entire type list by leveraging the reasoning thoughts embedded in a sub-graph associated with the missing query pair to address the missingness issue. Through extensive comparisons with existing prompt techniques and alternative Language Models (LLMs), our framework demonstrates superior performance on publicly available benchmarks in experiments.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024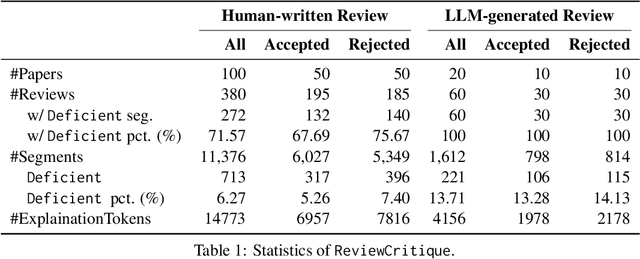
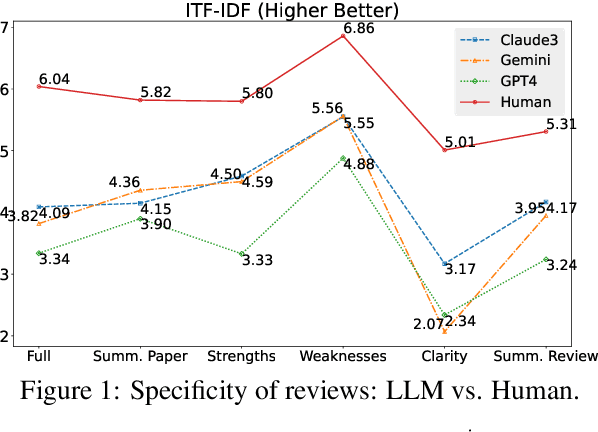

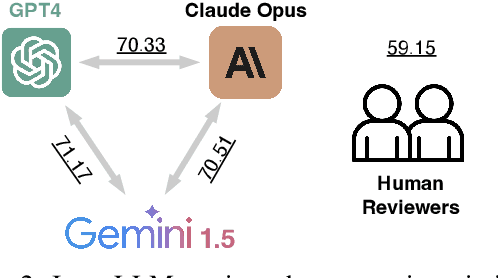
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
kNN-ICL: Compositional Task-Oriented Parsing Generalization with Nearest Neighbor In-Context Learning
Dec 17, 2023



Task-Oriented Parsing (TOP) enables conversational assistants to interpret user commands expressed in natural language, transforming them into structured outputs that combine elements of both natural language and intent/slot tags. Recently, Large Language Models (LLMs) have achieved impressive performance in synthesizing computer programs based on a natural language prompt, mitigating the gap between natural language and structured programs. Our paper focuses on harnessing the capabilities of LLMs for semantic parsing tasks, addressing the following three key research questions: 1) How can LLMs be effectively utilized for semantic parsing tasks? 2) What defines an effective prompt? and 3) How can LLM overcome the length constraint and streamline prompt design by including all examples as prompts? We introduce k Nearest Neighbor In-Context Learning(kNN-ICL), which simplifies prompt engineering by allowing it to be built on top of any design strategy while providing access to all demo examples. Extensive experiments show that: 1)Simple ICL without kNN search can achieve a comparable performance with strong supervised models on the TOP tasks, and 2) kNN-ICL significantly improves the comprehension of complex requests by seamlessly integrating ICL with a nearest-neighbor approach. Notably, this enhancement is achieved without the need for additional data or specialized prompts.
Aspect-based Meeting Transcript Summarization: A Two-Stage Approach with Weak Supervision on Sentence Classification
Nov 07, 2023



Aspect-based meeting transcript summarization aims to produce multiple summaries, each focusing on one aspect of content in a meeting transcript. It is challenging as sentences related to different aspects can mingle together, and those relevant to a specific aspect can be scattered throughout the long transcript of a meeting. The traditional summarization methods produce one summary mixing information of all aspects, which cannot deal with the above challenges of aspect-based meeting transcript summarization. In this paper, we propose a two-stage method for aspect-based meeting transcript summarization. To select the input content related to specific aspects, we train a sentence classifier on a dataset constructed from the AMI corpus with pseudo-labeling. Then we merge the sentences selected for a specific aspect as the input for the summarizer to produce the aspect-based summary. Experimental results on the AMI corpus outperform many strong baselines, which verifies the effectiveness of our proposed method.
JPAVE: A Generation and Classification-based Model for Joint Product Attribute Prediction and Value Extraction
Nov 07, 2023



Product attribute value extraction is an important task in e-Commerce which can help several downstream applications such as product search and recommendation. Most previous models handle this task using sequence labeling or question answering method which rely on the sequential position information of values in the product text and are vulnerable to data discrepancy between training and testing. This limits their generalization ability to real-world scenario in which each product can have multiple descriptions across various shopping platforms with different composition of text and style. They also have limited zero-shot ability to new values. In this paper, we propose a multi-task learning model with value generation/classification and attribute prediction called JPAVE to predict values without the necessity of position information of values in the text. Furthermore, the copy mechanism in value generator and the value attention module in value classifier help our model address the data discrepancy issue by only focusing on the relevant part of input text and ignoring other information which causes the discrepancy issue such as sentence structure in the text. Besides, two variants of our model are designed for open-world and closed-world scenarios. In addition, copy mechanism introduced in the first variant based on value generation can improve its zero-shot ability for identifying unseen values. Experimental results on a public dataset demonstrate the superiority of our model compared with strong baselines and its generalization ability of predicting new values.
AE-smnsMLC: Multi-Label Classification with Semantic Matching and Negative Label Sampling for Product Attribute Value Extraction
Oct 11, 2023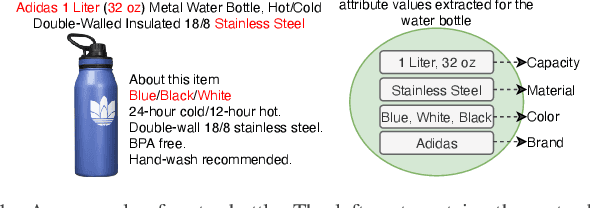



Product attribute value extraction plays an important role for many real-world applications in e-Commerce such as product search and recommendation. Previous methods treat it as a sequence labeling task that needs more annotation for position of values in the product text. This limits their application to real-world scenario in which only attribute values are weakly-annotated for each product without their position. Moreover, these methods only use product text (i.e., product title and description) and do not consider the semantic connection between the multiple attribute values of a given product and its text, which can help attribute value extraction. In this paper, we reformulate this task as a multi-label classification task that can be applied for real-world scenario in which only annotation of attribute values is available to train models (i.e., annotation of positional information of attribute values is not available). We propose a classification model with semantic matching and negative label sampling for attribute value extraction. Semantic matching aims to capture semantic interactions between attribute values of a given product and its text. Negative label sampling aims to enhance the model's ability of distinguishing similar values belonging to the same attribute. Experimental results on three subsets of a large real-world e-Commerce dataset demonstrate the effectiveness and superiority of our proposed model.
Localize, Retrieve and Fuse: A Generalized Framework for Free-Form Question Answering over Tables
Sep 21, 2023Question answering on tabular data (a.k.a TableQA), which aims at generating answers to questions grounded on a provided table, has gained significant attention recently. Prior work primarily produces concise factual responses through information extraction from individual or limited table cells, lacking the ability to reason across diverse table cells. Yet, the realm of free-form TableQA, which demands intricate strategies for selecting relevant table cells and the sophisticated integration and inference of discrete data fragments, remains mostly unexplored. To this end, this paper proposes a generalized three-stage approach: Table-to- Graph conversion and cell localizing, external knowledge retrieval, and the fusion of table and text (called TAG-QA), to address the challenge of inferring long free-form answers in generative TableQA. In particular, TAG-QA (1) locates relevant table cells using a graph neural network to gather intersecting cells between relevant rows and columns, (2) leverages external knowledge from Wikipedia, and (3) generates answers by integrating both tabular data and natural linguistic information. Experiments showcase the superior capabilities of TAG-QA in generating sentences that are both faithful and coherent, particularly when compared to several state-of-the-art baselines. Notably, TAG-QA surpasses the robust pipeline-based baseline TAPAS by 17% and 14% in terms of BLEU-4 and PARENT F-score, respectively. Furthermore, TAG-QA outperforms the end-to-end model T5 by 16% and 12% on BLEU-4 and PARENT F-score, respectively.
Named Entity Recognition via Machine Reading Comprehension: A Multi-Task Learning Approach
Sep 20, 2023



Named Entity Recognition (NER) aims to extract and classify entity mentions in the text into pre-defined types (e.g., organization or person name). Recently, many works have been proposed to shape the NER as a machine reading comprehension problem (also termed MRC-based NER), in which entity recognition is achieved by answering the formulated questions related to pre-defined entity types through MRC, based on the contexts. However, these works ignore the label dependencies among entity types, which are critical for precisely recognizing named entities. In this paper, we propose to incorporate the label dependencies among entity types into a multi-task learning framework for better MRC-based NER. We decompose MRC-based NER into multiple tasks and use a self-attention module to capture label dependencies. Comprehensive experiments on both nested NER and flat NER datasets are conducted to validate the effectiveness of the proposed Multi-NER. Experimental results show that Multi-NER can achieve better performance on all datasets.