 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterviewSim: A Scalable Framework for Interview-Grounded Personality Simulation
Feb 23, 2026Simulating real personalities with large language models requires grounding generation in authentic personal data. Existing evaluation approaches rely on demographic surveys, personality questionnaires, or short AI-led interviews as proxies, but lack direct assessment against what individuals actually said. We address this gap with an interview-grounded evaluation framework for personality simulation at a large scale. We extract over 671,000 question-answer pairs from 23,000 verified interview transcripts across 1,000 public personalities, each with an average of 11.5 hours of interview content. We propose a multi-dimensional evaluation framework with four complementary metrics measuring content similarity, factual consistency, personality alignment, and factual knowledge retention. Through systematic comparison, we demonstrate that methods grounded in real interview data substantially outperform those relying solely on biographical profiles or the model's parametric knowledge. We further reveal a trade-off in how interview data is best utilized: retrieval-augmented methods excel at capturing personality style and response quality, while chronological-based methods better preserve factual consistency and knowledge retention. Our evaluation framework enables principled method selection based on application requirements, and our empirical findings provide actionable insights for advancing personality simulation research.
The Need for a Socially-Grounded Persona Framework for User Simulation
Jan 12, 2026Synthetic personas are widely used to condition large language models (LLMs) for social simulation, yet most personas are still constructed from coarse sociodemographic attributes or summaries. We revisit persona creation by introducing SCOPE, a socially grounded framework for persona construction and evaluation, built from a 141-item, two-hour sociopsychological protocol collected from 124 U.S.-based participants. Across seven models, we find that demographic-only personas are a structural bottleneck: demographics explain only ~1.5% of variance in human response similarity. Adding sociopsychological facets improves behavioral prediction and reduces over-accentuation, and non-demographic personas based on values and identity achieve strong alignment with substantially lower bias. These trends generalize to SimBench (441 aligned questions), where SCOPE personas outperform default prompting and NVIDIA Nemotron personas, and SCOPE augmentation improves Nemotron-based personas. Our results indicate that persona quality depends on sociopsychological structure rather than demographic templates or summaries.
MMPersuade: A Dataset and Evaluation Framework for Multimodal Persuasion
Oct 26, 2025As Large Vision-Language Models (LVLMs) are increasingly deployed in domains such as shopping, health, and news, they are exposed to pervasive persuasive content. A critical question is how these models function as persuadees-how and why they can be influenced by persuasive multimodal inputs. Understanding both their susceptibility to persuasion and the effectiveness of different persuasive strategies is crucial, as overly persuadable models may adopt misleading beliefs, override user preferences, or generate unethical or unsafe outputs when exposed to manipulative messages. We introduce MMPersuade, a unified framework for systematically studying multimodal persuasion dynamics in LVLMs. MMPersuade contributes (i) a comprehensive multimodal dataset that pairs images and videos with established persuasion principles across commercial, subjective and behavioral, and adversarial contexts, and (ii) an evaluation framework that quantifies both persuasion effectiveness and model susceptibility via third-party agreement scoring and self-estimated token probabilities on conversation histories. Our study of six leading LVLMs as persuadees yields three key insights: (i) multimodal inputs substantially increase persuasion effectiveness-and model susceptibility-compared to text alone, especially in misinformation scenarios; (ii) stated prior preferences decrease susceptibility, yet multimodal information maintains its persuasive advantage; and (iii) different strategies vary in effectiveness across contexts, with reciprocity being most potent in commercial and subjective contexts, and credibility and logic prevailing in adversarial contexts. By jointly analyzing persuasion effectiveness and susceptibility, MMPersuade provides a principled foundation for developing models that are robust, preference-consistent, and ethically aligned when engaging with persuasive multimodal content.
A Tale of Two Identities: An Ethical Audit of Human and AI-Crafted Personas
May 07, 2025As LLMs (large language models) are increasingly used to generate synthetic personas particularly in data-limited domains such as health, privacy, and HCI, it becomes necessary to understand how these narratives represent identity, especially that of minority communities. In this paper, we audit synthetic personas generated by 3 LLMs (GPT4o, Gemini 1.5 Pro, Deepseek 2.5) through the lens of representational harm, focusing specifically on racial identity. Using a mixed methods approach combining close reading, lexical analysis, and a parameterized creativity framework, we compare 1512 LLM generated personas to human-authored responses. Our findings reveal that LLMs disproportionately foreground racial markers, overproduce culturally coded language, and construct personas that are syntactically elaborate yet narratively reductive. These patterns result in a range of sociotechnical harms, including stereotyping, exoticism, erasure, and benevolent bias, that are often obfuscated by superficially positive narrations. We formalize this phenomenon as algorithmic othering, where minoritized identities are rendered hypervisible but less authentic. Based on these findings, we offer design recommendations for narrative-aware evaluation metrics and community-centered validation protocols for synthetic identity generation.
Can Third-parties Read Our Emotions?
Apr 25, 2025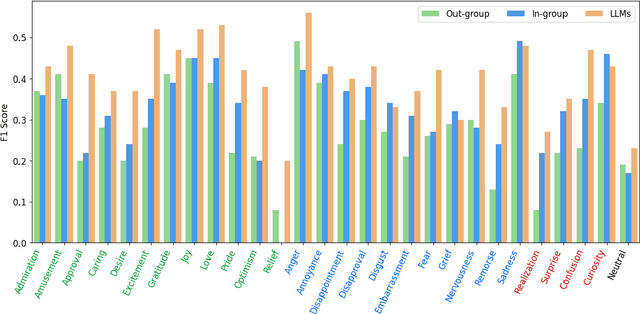
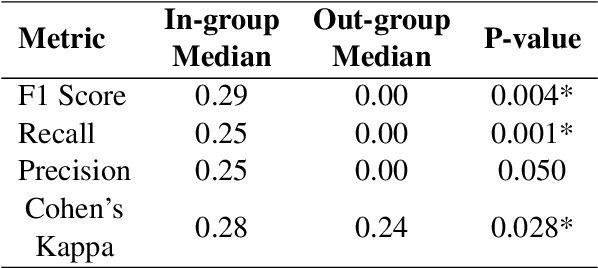
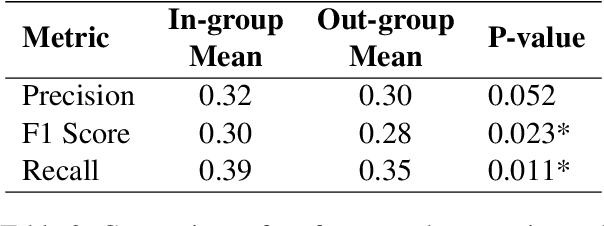
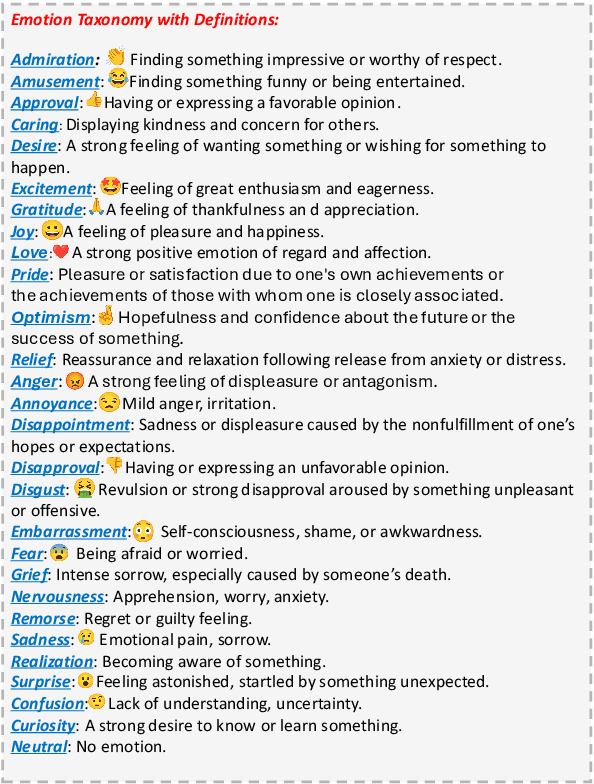
Natural Language Processing tasks that aim to infer an author's private states, e.g., emotions and opinions, from their written text, typically rely on datasets annotated by third-party annotators. However, the assumption that third-party annotators can accurately capture authors' private states remains largely unexamined. In this study, we present human subjects experiments on emotion recognition tasks that directly compare third-party annotations with first-party (author-provided) emotion labels. Our findings reveal significant limitations in third-party annotations-whether provided by human annotators or large language models (LLMs)-in faithfully representing authors' private states. However, LLMs outperform human annotators nearly across the board. We further explore methods to improve third-party annotation quality. We find that demographic similarity between first-party authors and third-party human annotators enhances annotation performance. While incorporating first-party demographic information into prompts leads to a marginal but statistically significant improvement in LLMs' performance. We introduce a framework for evaluating the limitations of third-party annotations and call for refined annotation practices to accurately represent and model authors' private states.
Hey GPT, Can You be More Racist? Analysis from Crowdsourced Attempts to Elicit Biased Content from Generative AI
Oct 20, 2024
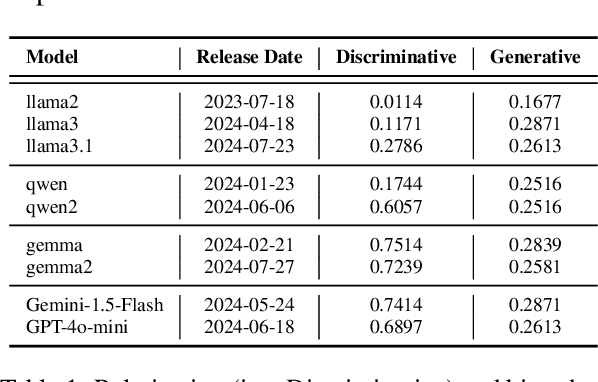

The widespread adoption of large language models (LLMs) and generative AI (GenAI) tools across diverse applications has amplified the importance of addressing societal biases inherent within these technologies. While the NLP community has extensively studied LLM bias, research investigating how non-expert users perceive and interact with biases from these systems remains limited. As these technologies become increasingly prevalent, understanding this question is crucial to inform model developers in their efforts to mitigate bias. To address this gap, this work presents the findings from a university-level competition, which challenged participants to design prompts for eliciting biased outputs from GenAI tools. We quantitatively and qualitatively analyze the competition submissions and identify a diverse set of biases in GenAI and strategies employed by participants to induce bias in GenAI. Our finding provides unique insights into how non-expert users perceive and interact with biases from GenAI tools.
Do Generative AI Models Output Harm while Representing Non-Western Cultures: Evidence from A Community-Centered Approach
Jul 24, 2024
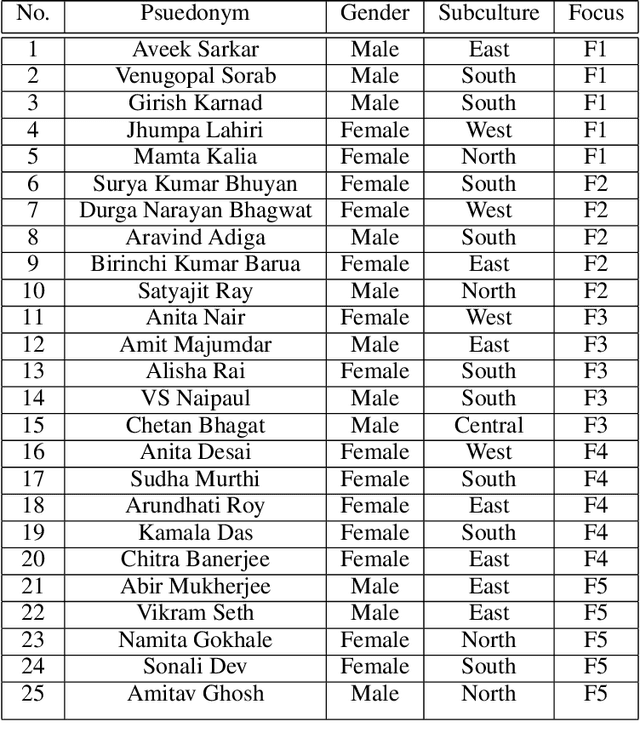


Our research investigates the impact of Generative Artificial Intelligence (GAI) models, specifically text-to-image generators (T2Is), on the representation of non-Western cultures, with a focus on Indian contexts. Despite the transformative potential of T2Is in content creation, concerns have arisen regarding biases that may lead to misrepresentations and marginalizations. Through a community-centered approach and grounded theory analysis of 5 focus groups from diverse Indian subcultures, we explore how T2I outputs to English prompts depict Indian culture and its subcultures, uncovering novel representational harms such as exoticism and cultural misappropriation. These findings highlight the urgent need for inclusive and culturally sensitive T2I systems. We propose design guidelines informed by a sociotechnical perspective, aiming to address these issues and contribute to the development of more equitable and representative GAI technologies globally. Our work also underscores the necessity of adopting a community-centered approach to comprehend the sociotechnical dynamics of these models, complementing existing work in this space while identifying and addressing the potential negative repercussions and harms that may arise when these models are deployed on a global scale.
Race and Privacy in Broadcast Police Communications
Jul 01, 2024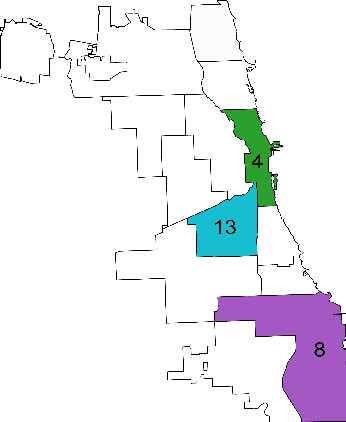
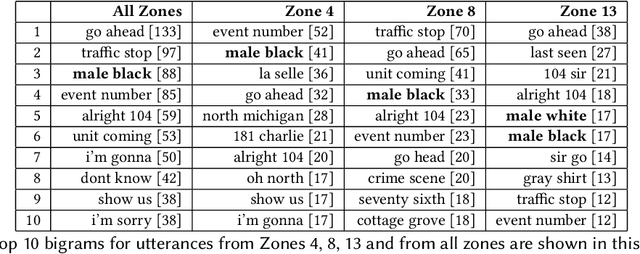
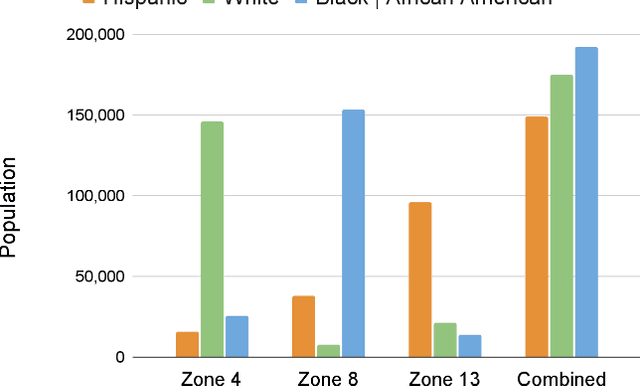
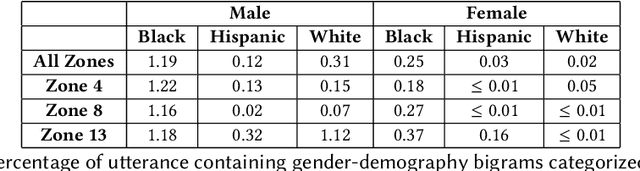
Radios are essential for the operations of modern police departments, and they function as both a collaborative communication technology and a sociotechnical system. However, little prior research has examined their usage or their connections to individual privacy and the role of race in policing, two growing topics of concern in the US. As a case study, we examine the Chicago Police Department's (CPD's) use of broadcast police communications (BPC) to coordinate the activity of law enforcement officers (LEOs) in the city. From a recently assembled archive of 80,775 hours of BPC associated with CPD operations, we analyze text transcripts of radio transmissions broadcast 9:00 AM to 5:00 PM on August 10th, 2018 in one majority Black, one majority white, and one majority Hispanic area of the city (24 hours of audio) to explore three research questions: (1) Do BPC reflect reported racial disparities in policing? (2) How and when is gender, race/ethnicity, and age mentioned in BPC? (3) To what extent do BPC include sensitive information, and who is put at most risk by this practice? (4) To what extent can large language models (LLMs) heighten this risk? We explore the vocabulary and speech acts used by police in BPC, comparing mentions of personal characteristics to local demographics, the personal information shared over BPC, and the privacy concerns that it poses. Analysis indicates (a) policing professionals in the city of Chicago exhibit disproportionate attention to Black members of the public regardless of context, (b) sociodemographic characteristics like gender, race/ethnicity, and age are primarily mentioned in BPC about event information, and (c) disproportionate attention introduces disproportionate privacy risks for Black members of the public.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024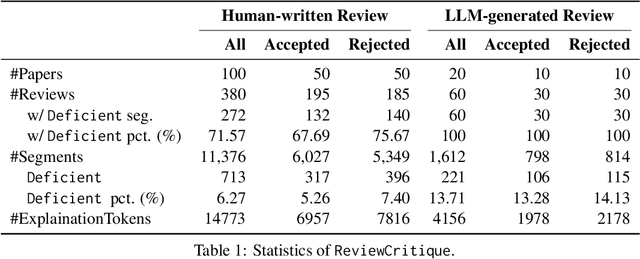
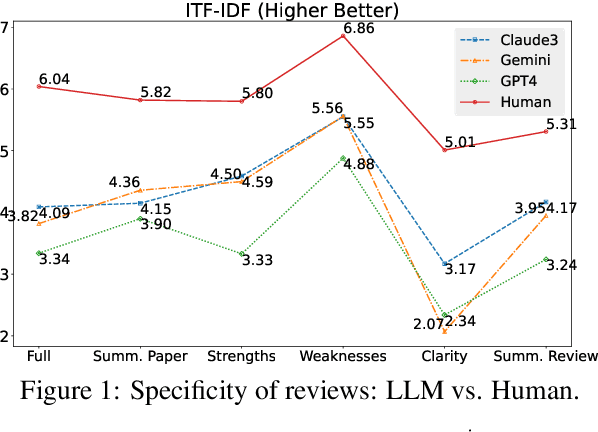

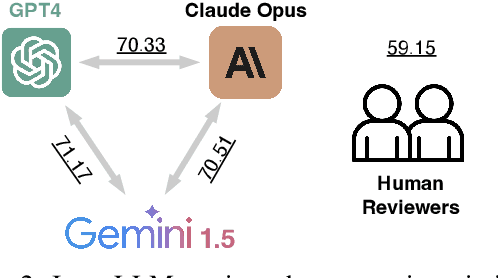
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
The Unappreciated Role of Intent in Algorithmic Moderation of Social Media Content
May 17, 2024
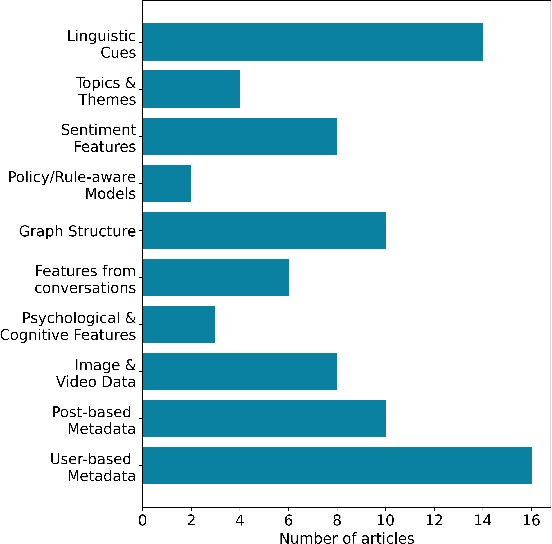
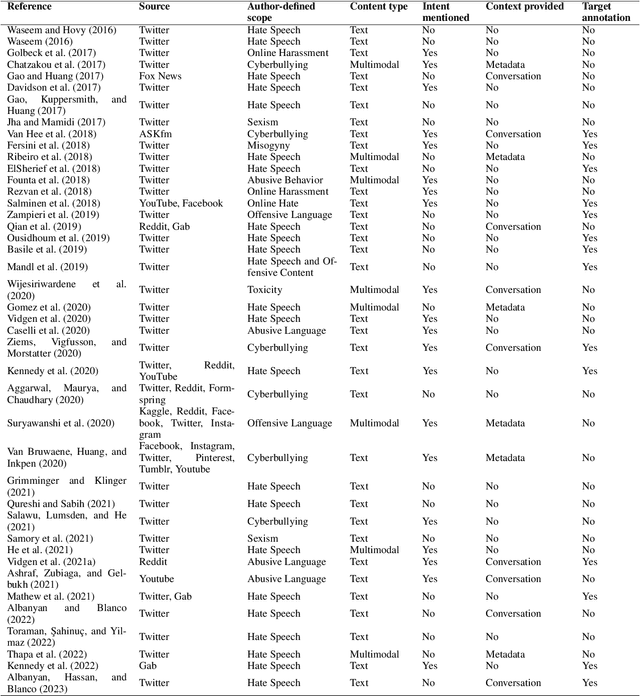
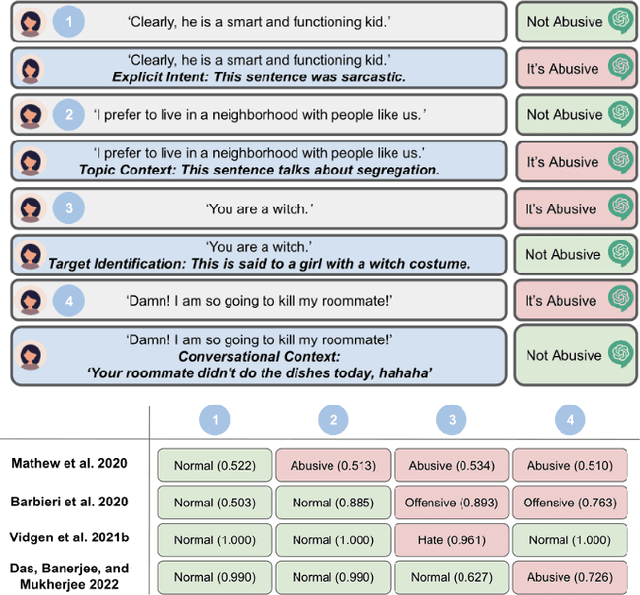
As social media has become a predominant mode of communication globally, the rise of abusive content threatens to undermine civil discourse. Recognizing the critical nature of this issue, a significant body of research has been dedicated to developing language models that can detect various types of online abuse, e.g., hate speech, cyberbullying. However, there exists a notable disconnect between platform policies, which often consider the author's intention as a criterion for content moderation, and the current capabilities of detection models, which typically lack efforts to capture intent. This paper examines the role of intent in content moderation systems. We review state of the art detection models and benchmark training datasets for online abuse to assess their awareness and ability to capture intent. We propose strategic changes to the design and development of automated detection and moderation systems to improve alignment with ethical and policy conceptualizations of abuse.