 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reopening of Pandora's Box: Analyzing the Role of LLMs in the Evolving Battle Against AI-Generated Fake News
Oct 25, 2024



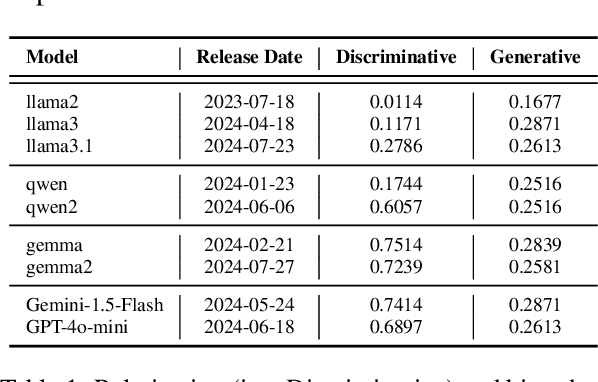
With the rise of AI-generated content spewed at scale from large language models (LLMs), genuine concerns about the spread of fake news have intensified. The perceived ability of LLMs to produce convincing fake news at scale poses new challenges for both human and automated fake news detection systems. To address this gap, this work presents the findings from a university-level competition which aimed to explore how LLMs can be used by humans to create fake news, and to assess the ability of human annotators and AI models to detect it. A total of 110 participants used LLMs to create 252 unique fake news stories, and 84 annotators participated in the detection tasks. Our findings indicate that LLMs are ~68% more effective at detecting real news than humans. However, for fake news detection, the performance of LLMs and humans remains comparable (~60% accuracy). Additionally, we examine the impact of visual elements (e.g., pictures) in news on the accuracy of detecting fake news stories. Finally, we also examine various strategies used by fake news creators to enhance the credibility of their AI-generated content. This work highlights the increasing complexity of detecting AI-generated fake news, particularly in collaborative human-AI settings.
Hey GPT, Can You be More Racist? Analysis from Crowdsourced Attempts to Elicit Biased Content from Generative AI
Oct 20, 2024

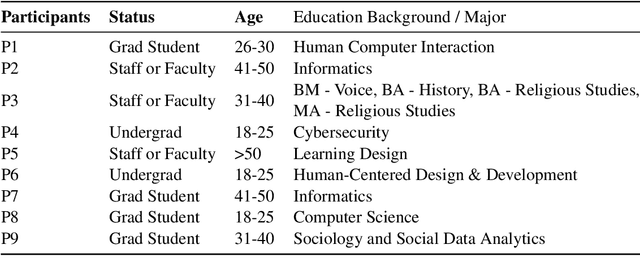
The widespread adoption of large language models (LLMs) and generative AI (GenAI) tools across diverse applications has amplified the importance of addressing societal biases inherent within these technologies. While the NLP community has extensively studied LLM bias, research investigating how non-expert users perceive and interact with biases from these systems remains limited. As these technologies become increasingly prevalent, understanding this question is crucial to inform model developers in their efforts to mitigate bias. To address this gap, this work presents the findings from a university-level competition, which challenged participants to design prompts for eliciting biased outputs from GenAI tools. We quantitatively and qualitatively analyze the competition submissions and identify a diverse set of biases in GenAI and strategies employed by participants to induce bias in GenAI. Our finding provides unique insights into how non-expert users perceive and interact with biases from GenAI tools.
Designing for Responsible Trust in AI Systems: A Communication Perspective
Apr 29, 2022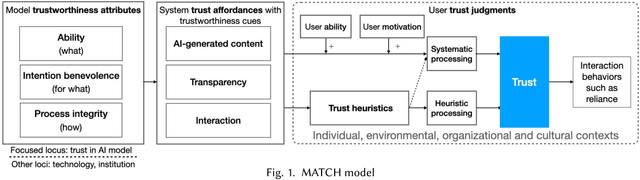
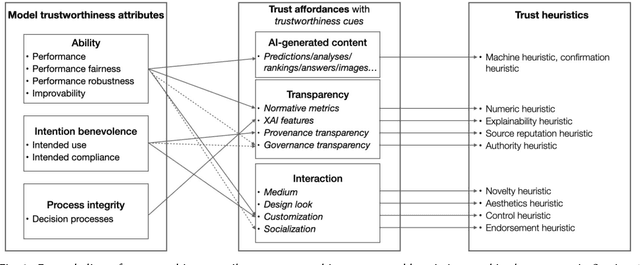
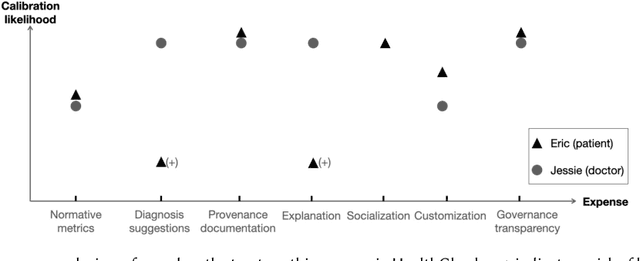
Current literature and public discourse on "trust in AI" are often focused on the principles underlying trustworthy AI, with insufficient attention paid to how people develop trust. Given that AI systems differ in their level of trustworthiness, two open questions come to the fore: how should AI trustworthiness be responsibly communicated to ensure appropriate and equitable trust judgments by different users, and how can we protect users from deceptive attempts to earn their trust? We draw from communication theories and literature on trust in technologies to develop a conceptual model called MATCH, which describes how trustworthiness is communicated in AI systems through trustworthiness cues and how those cues are processed by people to make trust judgments. Besides AI-generated content, we highlight transparency and interaction as AI systems' affordances that present a wide range of trustworthiness cues to users. By bringing to light the variety of users' cognitive processes to make trust judgments and their potential limitations, we urge technology creators to make conscious decisions in choosing reliable trustworthiness cues for target users and, as an industry, to regulate this space and prevent malicious use. Towards these goals, we define the concepts of warranted trustworthiness cues and expensive trustworthiness cues, and propose a checklist of requirements to help technology creators identify appropriate cues to use. We present a hypothetical use case to illustrate how practitioners can use MATCH to design AI systems responsibly, and discuss future directions for research and industry efforts aimed at promoting responsible trust in AI.