 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Experience-Centered AI: A Framework for Integrating Lived Experience in Design and Development
Aug 09, 2025Lived experiences fundamentally shape how individuals interact with AI systems, influencing perceptions of safety, trust, and usability. While prior research has focused on developing techniques to emulate human preferences, and proposed taxonomies to categorize risks (such as psychological harms and algorithmic biases), these efforts have provided limited systematic understanding of lived human experiences or actionable strategies for embedding them meaningfully into the AI development lifecycle. This work proposes a framework for meaningfully integrating lived experience into the design and evaluation of AI systems. We synthesize interdisciplinary literature across lived experience philosophy, human-centered design, and human-AI interaction, arguing that centering lived experience can lead to models that more accurately reflect the retrospective, emotional, and contextual dimensions of human cognition. Drawing from a wide body of work across psychology, education, healthcare, and social policy, we present a targeted taxonomy of lived experiences with specific applicability to AI systems. To ground our framework, we examine three application domains (i) education, (ii) healthcare, and (iii) cultural alignment, illustrating how lived experience informs user goals, system expectations, and ethical considerations in each context. We further incorporate insights from AI system operators and human-AI partnerships to highlight challenges in responsibility allocation, mental model calibration, and long-term system adaptation. We conclude with actionable recommendations for developing experience-centered AI systems that are not only technically robust but also empathetic, context-aware, and aligned with human realities. This work offers a foundation for future research that bridges technical development with the lived experiences of those impacted by AI systems.
Do Generative AI Models Output Harm while Representing Non-Western Cultures: Evidence from A Community-Centered Approach
Jul 24, 2024
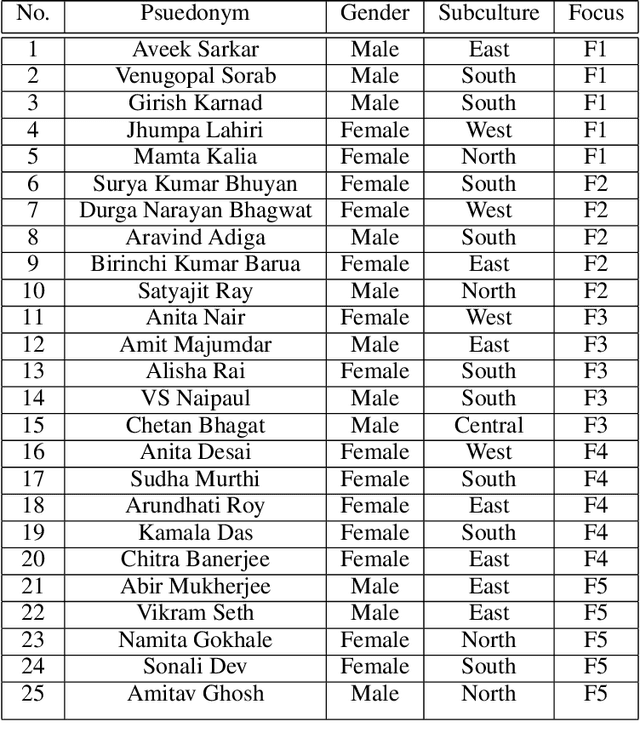


Our research investigates the impact of Generative Artificial Intelligence (GAI) models, specifically text-to-image generators (T2Is), on the representation of non-Western cultures, with a focus on Indian contexts. Despite the transformative potential of T2Is in content creation, concerns have arisen regarding biases that may lead to misrepresentations and marginalizations. Through a community-centered approach and grounded theory analysis of 5 focus groups from diverse Indian subcultures, we explore how T2I outputs to English prompts depict Indian culture and its subcultures, uncovering novel representational harms such as exoticism and cultural misappropriation. These findings highlight the urgent need for inclusive and culturally sensitive T2I systems. We propose design guidelines informed by a sociotechnical perspective, aiming to address these issues and contribute to the development of more equitable and representative GAI technologies globally. Our work also underscores the necessity of adopting a community-centered approach to comprehend the sociotechnical dynamics of these models, complementing existing work in this space while identifying and addressing the potential negative repercussions and harms that may arise when these models are deployed on a global scale.
Blind Spots and Biases: Exploring the Role of Annotator Cognitive Biases in NLP
Apr 29, 2024With the rapid proliferation of artificial intelligence, there is growing concern over its potential to exacerbate existing biases and societal disparities and introduce novel ones. This issue has prompted widespread attention from academia, policymakers, industry, and civil society. While evidence suggests that integrating human perspectives can mitigate bias-related issues in AI systems, it also introduces challenges associated with cognitive biases inherent in human decision-making. Our research focuses on reviewing existing methodologies and ongoing investigations aimed at understanding annotation attributes that contribute to bias.
From Melting Pots to Misrepresentations: Exploring Harms in Generative AI
Mar 16, 2024

With the widespread adoption of advanced generative models such as Gemini and GPT, there has been a notable increase in the incorporation of such models into sociotechnical systems, categorized under AI-as-a-Service (AIaaS). Despite their versatility across diverse sectors, concerns persist regarding discriminatory tendencies within these models, particularly favoring selected `majority' demographics across various sociodemographic dimensions. Despite widespread calls for diversification of media representations, marginalized racial and ethnic groups continue to face persistent distortion, stereotyping, and neglect within the AIaaS context. In this work, we provide a critical summary of the state of research in the context of social harms to lead the conversation to focus on their implications. We also present open-ended research questions, guided by our discussion, to help define future research pathways.
The Sentiment Problem: A Critical Survey towards Deconstructing Sentiment Analysis
Oct 18, 2023



We conduct an inquiry into the sociotechnical aspects of sentiment analysis (SA) by critically examining 189 peer-reviewed papers on their applications, models, and datasets. Our investigation stems from the recognition that SA has become an integral component of diverse sociotechnical systems, exerting influence on both social and technical users. By delving into sociological and technological literature on sentiment, we unveil distinct conceptualizations of this term in domains such as finance, government, and medicine. Our study exposes a lack of explicit definitions and frameworks for characterizing sentiment, resulting in potential challenges and biases. To tackle this issue, we propose an ethics sheet encompassing critical inquiries to guide practitioners in ensuring equitable utilization of SA. Our findings underscore the significance of adopting an interdisciplinary approach to defining sentiment in SA and offer a pragmatic solution for its implementation.
Unmasking Nationality Bias: A Study of Human Perception of Nationalities in AI-Generated Articles
Aug 08, 2023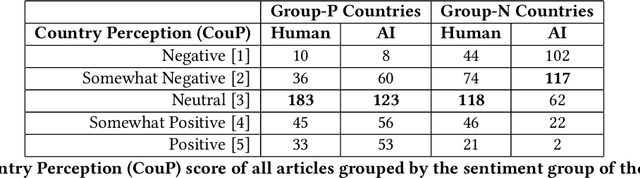
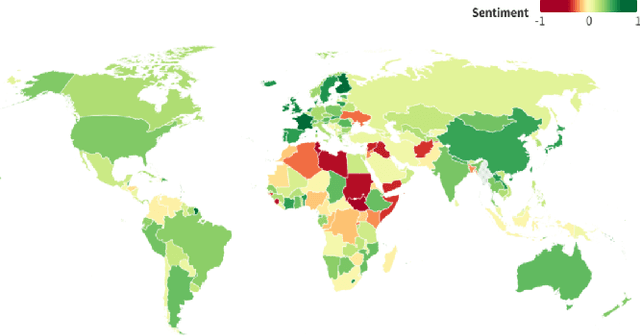

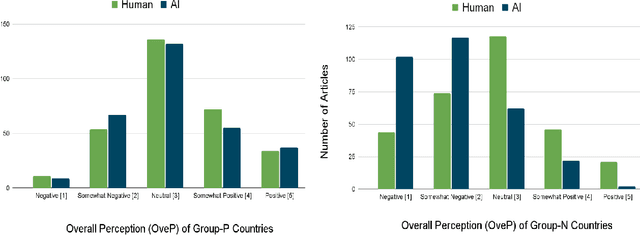
We investigate the potential for nationality biases in natural language processing (NLP) models using human evaluation methods. Biased NLP models can perpetuate stereotypes and lead to algorithmic discrimination, posing a significant challenge to the fairness and justice of AI systems. Our study employs a two-step mixed-methods approach that includes both quantitative and qualitative analysis to identify and understand the impact of nationality bias in a text generation model. Through our human-centered quantitative analysis, we measure the extent of nationality bias in articles generated by AI sources. We then conduct open-ended interviews with participants, performing qualitative coding and thematic analysis to understand the implications of these biases on human readers. Our findings reveal that biased NLP models tend to replicate and amplify existing societal biases, which can translate to harm if used in a sociotechnical setting. The qualitative analysis from our interviews offers insights into the experience readers have when encountering such articles, highlighting the potential to shift a reader's perception of a country. These findings emphasize the critical role of public perception in shaping AI's impact on society and the need to correct biases in AI systems.
Nationality Bias in Text Generation
Feb 14, 2023Little attention is placed on analyzing nationality bias in language models, especially when nationality is highly used as a factor in increasing the performance of social NLP models. This paper examines how a text generation model, GPT-2, accentuates pre-existing societal biases about country-based demonyms. We generate stories using GPT-2 for various nationalities and use sensitivity analysis to explore how the number of internet users and the country's economic status impacts the sentiment of the stories. To reduce the propagation of biases through large language models (LLM), we explore the debiasing method of adversarial triggering. Our results show that GPT-2 demonstrates significant bias against countries with lower internet users, and adversarial triggering effectively reduces the same.