 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Experience-Centered AI: A Framework for Integrating Lived Experience in Design and Development
Aug 09, 2025Lived experiences fundamentally shape how individuals interact with AI systems, influencing perceptions of safety, trust, and usability. While prior research has focused on developing techniques to emulate human preferences, and proposed taxonomies to categorize risks (such as psychological harms and algorithmic biases), these efforts have provided limited systematic understanding of lived human experiences or actionable strategies for embedding them meaningfully into the AI development lifecycle. This work proposes a framework for meaningfully integrating lived experience into the design and evaluation of AI systems. We synthesize interdisciplinary literature across lived experience philosophy, human-centered design, and human-AI interaction, arguing that centering lived experience can lead to models that more accurately reflect the retrospective, emotional, and contextual dimensions of human cognition. Drawing from a wide body of work across psychology, education, healthcare, and social policy, we present a targeted taxonomy of lived experiences with specific applicability to AI systems. To ground our framework, we examine three application domains (i) education, (ii) healthcare, and (iii) cultural alignment, illustrating how lived experience informs user goals, system expectations, and ethical considerations in each context. We further incorporate insights from AI system operators and human-AI partnerships to highlight challenges in responsibility allocation, mental model calibration, and long-term system adaptation. We conclude with actionable recommendations for developing experience-centered AI systems that are not only technically robust but also empathetic, context-aware, and aligned with human realities. This work offers a foundation for future research that bridges technical development with the lived experiences of those impacted by AI systems.
Reasoning Is Not All You Need: Examining LLMs for Multi-Turn Mental Health Conversations
May 28, 2025Limited access to mental healthcare, extended wait times, and increasing capabilities of Large Language Models (LLMs) has led individuals to turn to LLMs for fulfilling their mental health needs. However, examining the multi-turn mental health conversation capabilities of LLMs remains under-explored. Existing evaluation frameworks typically focus on diagnostic accuracy and win-rates and often overlook alignment with patient-specific goals, values, and personalities required for meaningful conversations. To address this, we introduce MedAgent, a novel framework for synthetically generating realistic, multi-turn mental health sensemaking conversations and use it to create the Mental Health Sensemaking Dialogue (MHSD) dataset, comprising over 2,200 patient-LLM conversations. Additionally, we present MultiSenseEval, a holistic framework to evaluate the multi-turn conversation abilities of LLMs in healthcare settings using human-centric criteria. Our findings reveal that frontier reasoning models yield below-par performance for patient-centric communication and struggle at advanced diagnostic capabilities with average score of 31%. Additionally, we observed variation in model performance based on patient's persona and performance drop with increasing turns in the conversation. Our work provides a comprehensive synthetic data generation framework, a dataset and evaluation framework for assessing LLMs in multi-turn mental health conversations.
Longitudinal Study on Social and Emotional Use of AI Conversational Agent
Apr 19, 2025Development in digital technologies has continuously reshaped how individuals seek and receive social and emotional support. While online platforms and communities have long served this need, the increased integration of general-purpose conversational AI into daily lives has introduced new dynamics in how support is provided and experienced. Existing research has highlighted both benefits (e.g., wider access to well-being resources) and potential risks (e.g., over-reliance) of using AI for support seeking. In this five-week, exploratory study, we recruited 149 participants divided into two usage groups: a baseline usage group (BU, n=60) that used the internet and AI as usual, and an active usage group (AU, n=89) encouraged to use one of four commercially available AI tools (Microsoft Copilot, Google Gemini, PI AI, ChatGPT) for social and emotional interactions. Our analysis revealed significant increases in perceived attachment towards AI (32.99 percentage points), perceived AI empathy (25.8 p.p.), and motivation to use AI for entertainment (22.90 p.p.) among the AU group. We also observed that individual differences (e.g., gender identity, prior AI usage) influenced perceptions of AI empathy and attachment. Lastly, the AU group expressed higher comfort in seeking personal help, managing stress, obtaining social support, and talking about health with AI, indicating potential for broader emotional support while highlighting the need for safeguards against problematic usage. Overall, our exploratory findings underscore the importance of developing consumer-facing AI tools that support emotional well-being responsibly, while empowering users to understand the limitations of these tools.
A Framework for Situating Innovations, Opportunities, and Challenges in Advancing Vertical Systems with Large AI Models
Apr 03, 2025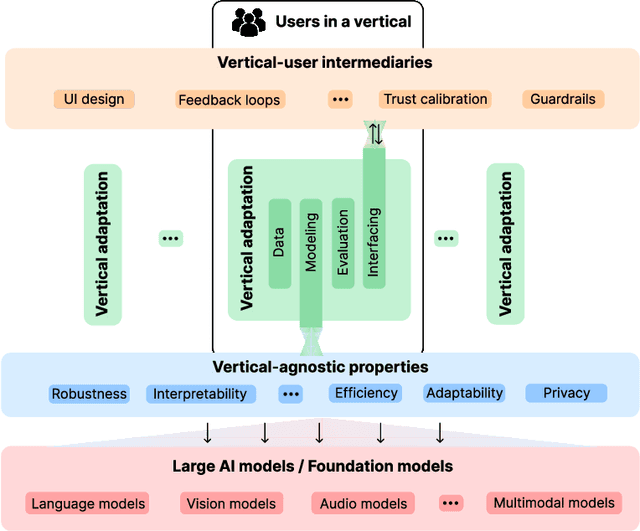
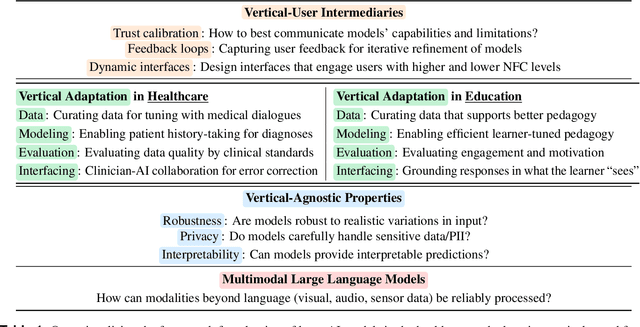
Large artificial intelligence (AI) models have garnered significant attention for their remarkable, often "superhuman", performance on standardized benchmarks. However, when these models are deployed in high-stakes verticals such as healthcare, education, and law, they often reveal notable limitations. For instance, they exhibit brittleness to minor variations in input data, present contextually uninformed decisions in critical settings, and undermine user trust by confidently producing or reproducing inaccuracies. These challenges in applying large models necessitate cross-disciplinary innovations to align the models' capabilities with the needs of real-world applications. We introduce a framework that addresses this gap through a layer-wise abstraction of innovations aimed at meeting users' requirements with large models. Through multiple case studies, we illustrate how researchers and practitioners across various fields can operationalize this framework. Beyond modularizing the pipeline of transforming large models into useful "vertical systems", we also highlight the dynamism that exists within different layers of the framework. Finally, we discuss how our framework can guide researchers and practitioners to (i) optimally situate their innovations (e.g., when vertical-specific insights can empower broadly impactful vertical-agnostic innovations), (ii) uncover overlooked opportunities (e.g., spotting recurring problems across verticals to develop practically useful foundation models instead of chasing benchmarks), and (iii) facilitate cross-disciplinary communication of critical challenges (e.g., enabling a shared vocabulary for AI developers, domain experts, and human-computer interaction scholars).
From Lived Experience to Insight: Unpacking the Psychological Risks of Using AI Conversational Agents
Dec 12, 2024Recent gain in popularity of AI conversational agents has led to their increased use for improving productivity and supporting well-being. While previous research has aimed to understand the risks associated with interactions with AI conversational agents, these studies often fall short in capturing the lived experiences. Additionally, psychological risks have often been presented as a sub-category within broader AI-related risks in past taxonomy works, leading to under-representation of the impact of psychological risks of AI use. To address these challenges, our work presents a novel risk taxonomy focusing on psychological risks of using AI gathered through lived experience of individuals. We employed a mixed-method approach, involving a comprehensive survey with 283 individuals with lived mental health experience and workshops involving lived experience experts to develop a psychological risk taxonomy. Our taxonomy features 19 AI behaviors, 21 negative psychological impacts, and 15 contexts related to individuals. Additionally, we propose a novel multi-path vignette based framework for understanding the complex interplay between AI behaviors, psychological impacts, and individual user contexts. Finally, based on the feedback obtained from the workshop sessions, we present design recommendations for developing safer and more robust AI agents. Our work offers an in-depth understanding of the psychological risks associated with AI conversational agents and provides actionable recommendations for policymakers, researchers, and developers.
Lived Experience Not Found: LLMs Struggle to Align with Experts on Addressing Adverse Drug Reactions from Psychiatric Medication Use
Oct 24, 2024



Adverse Drug Reactions (ADRs) from psychiatric medications are the leading cause of hospitalizations among mental health patients. With healthcare systems and online communities facing limitations in resolving ADR-related issues, Large Language Models (LLMs) have the potential to fill this gap. Despite the increasing capabilities of LLMs, past research has not explored their capabilities in detecting ADRs related to psychiatric medications or in providing effective harm reduction strategies. To address this, we introduce the Psych-ADR benchmark and the Adverse Drug Reaction Response Assessment (ADRA) framework to systematically evaluate LLM performance in detecting ADR expressions and delivering expert-aligned mitigation strategies. Our analyses show that LLMs struggle with understanding the nuances of ADRs and differentiating between types of ADRs. While LLMs align with experts in terms of expressed emotions and tone of the text, their responses are more complex, harder to read, and only 70.86% aligned with expert strategies. Furthermore, they provide less actionable advice by a margin of 12.32% on average. Our work provides a comprehensive benchmark and evaluation framework for assessing LLMs in strategy-driven tasks within high-risk domains.
MedHalu: Hallucinations in Responses to Healthcare Queries by Large Language Models
Sep 29, 2024The remarkable capabilities of large language models (LLMs) in language understanding and generation have not rendered them immune to hallucinations. LLMs can still generate plausible-sounding but factually incorrect or fabricated information. As LLM-empowered chatbots become popular, laypeople may frequently ask health-related queries and risk falling victim to these LLM hallucinations, resulting in various societal and healthcare implications. In this work, we conduct a pioneering study of hallucinations in LLM-generated responses to real-world healthcare queries from patients. We propose MedHalu, a carefully crafted first-of-its-kind medical hallucination dataset with a diverse range of health-related topics and the corresponding hallucinated responses from LLMs with labeled hallucination types and hallucinated text spans. We also introduce MedHaluDetect framework to evaluate capabilities of various LLMs in detecting hallucinations. We also employ three groups of evaluators -- medical experts, LLMs, and laypeople -- to study who are more vulnerable to these medical hallucinations. We find that LLMs are much worse than the experts. They also perform no better than laypeople and even worse in few cases in detecting hallucinations. To fill this gap, we propose expert-in-the-loop approach to improve hallucination detection through LLMs by infusing expert reasoning. We observe significant performance gains for all the LLMs with an average macro-F1 improvement of 6.3 percentage points for GPT-4.
Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries
Oct 23, 2023Large language models (LLMs) are transforming the ways the general public accesses and consumes information. Their influence is particularly pronounced in pivotal sectors like healthcare, where lay individuals are increasingly appropriating LLMs as conversational agents for everyday queries. While LLMs demonstrate impressive language understanding and generation proficiencies, concerns regarding their safety remain paramount in these high-stake domains. Moreover, the development of LLMs is disproportionately focused on English. It remains unclear how these LLMs perform in the context of non-English languages, a gap that is critical for ensuring equity in the real-world use of these systems.This paper provides a framework to investigate the effectiveness of LLMs as multi-lingual dialogue systems for healthcare queries. Our empirically-derived framework XlingEval focuses on three fundamental criteria for evaluating LLM responses to naturalistic human-authored health-related questions: correctness, consistency, and verifiability. Through extensive experiments on four major global languages, including English, Spanish, Chinese, and Hindi, spanning three expert-annotated large health Q&A datasets, and through an amalgamation of algorithmic and human-evaluation strategies, we found a pronounced disparity in LLM responses across these languages, indicating a need for enhanced cross-lingual capabilities. We further propose XlingHealth, a cross-lingual benchmark for examining the multilingual capabilities of LLMs in the healthcare context. Our findings underscore the pressing need to bolster the cross-lingual capacities of these models, and to provide an equitable information ecosystem accessible to all.
Understanding the Humans Behind Online Misinformation: An Observational Study Through the Lens of the COVID-19 Pandemic
Oct 12, 2023



The proliferation of online misinformation has emerged as one of the biggest threats to society. Considerable efforts have focused on building misinformation detection models, still the perils of misinformation remain abound. Mitigating online misinformation and its ramifications requires a holistic approach that encompasses not only an understanding of its intricate landscape in relation to the complex issue and topic-rich information ecosystem online, but also the psychological drivers of individuals behind it. Adopting a time series analytic technique and robust causal inference-based design, we conduct a large-scale observational study analyzing over 32 million COVID-19 tweets and 16 million historical timeline tweets. We focus on understanding the behavior and psychology of users disseminating misinformation during COVID-19 and its relationship with the historical inclinations towards sharing misinformation on Non-COVID topics before the pandemic. Our analysis underscores the intricacies inherent to cross-topic misinformation, and highlights that users' historical inclination toward sharing misinformation is positively associated with their present behavior pertaining to misinformation sharing on emergent topics and beyond. This work may serve as a valuable foundation for designing user-centric inoculation strategies and ecologically-grounded agile interventions for effectively tackling online misinformation.
Towards Massively Multi-domain Multilingual Readability Assessment
May 23, 2023



We present ReadMe++, a massively multi-domain multilingual dataset for automatic readability assessment. Prior work on readability assessment has been mostly restricted to the English language and one or two text domains. Additionally, the readability levels of sentences used in many previous datasets are assumed on the document-level other than sentence-level, which raises doubt about the quality of previous evaluations. We address those gaps in the literature by providing an annotated dataset of 6,330 sentences in Arabic, English, and Hindi collected from 64 different domains of text. Unlike previous datasets, ReadMe++ offers more domain and language diversity and is manually annotated at a sentence level using the Common European Framework of Reference for Languages (CEFR) and through a Rank-and-Rate annotation framework that reduces subjectivity in annotation. Our experiments demonstrate that models fine-tuned using ReadMe++ achieve strong cross-lingual transfer capabilities and generalization to unseen domains. ReadMe++ will be made publicly available to the research community.