 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntroCoT: Enhancing Chain-of-Thought via Adaptive Entropy-Guided Segmentation
Jan 08, 2026Chain-of-Thought (CoT) prompting has significantly enhanced the mathematical reasoning capabilities of Large Language Models. We find existing fine-tuning datasets frequently suffer from the "answer right but reasoning wrong" probelm, where correct final answers are derived from hallucinated, redundant, or logically invalid intermediate steps. This paper proposes EntroCoT, a unified framework for automatically identifying and refining low-quality CoT supervision traces. EntroCoT first proposes an entropy-based mechanism to segment the reasoning trace into multiple steps at uncertain junctures, and then introduces a Monte Carlo rollout-based mechanism to evaluate the marginal contribution of each step. By accurately filtering deceptive reasoning samples, EntroCoT constructs a high-quality dataset where every intermediate step in each reasoning trace facilitates the final answer. Extensive experiments on mathematical benchmarks demonstrate that fine-tuning on the subset constructed by EntroCoT consistently outperforms the baseslines of full-dataset supervision.
CFT-RAG: An Entity Tree Based Retrieval Augmented Generation Algorithm With Cuckoo Filter
Jan 25, 2025



Although retrieval-augmented generation(RAG) significantly improves generation quality by retrieving external knowledge bases and integrating generated content, it faces computational efficiency bottlenecks, particularly in knowledge retrieval tasks involving hierarchical structures for Tree-RAG. This paper proposes a Tree-RAG acceleration method based on the improved Cuckoo Filter, which optimizes entity localization during the retrieval process to achieve significant performance improvements. Tree-RAG effectively organizes entities through the introduction of a hierarchical tree structure, while the Cuckoo Filter serves as an efficient data structure that supports rapid membership queries and dynamic updates. The experiment results demonstrate that our method is much faster than naive Tree-RAG while maintaining high levels of generative quality. When the number of trees is large, our method is hundreds of times faster than naive Tree-RAG. Our work is available at https://github.com/TUPYP7180/CFT-RAG-2025.
Do Large Language Models Align with Core Mental Health Counseling Competencies?
Oct 29, 2024



The rapid evolution of Large Language Models (LLMs) offers promising potential to alleviate the global scarcity of mental health professionals. However, LLMs' alignment with essential mental health counseling competencies remains understudied. We introduce CounselingBench, a novel NCMHCE-based benchmark evaluating LLMs across five key mental health counseling competencies. Testing 22 general-purpose and medical-finetuned LLMs, we find frontier models exceed minimum thresholds but fall short of expert-level performance, with significant variations: they excel in Intake, Assessment & Diagnosis yet struggle with Core Counseling Attributes and Professional Practice & Ethics. Medical LLMs surprisingly underperform generalist models accuracy-wise, while at the same time producing slightly higher-quality justifications but making more context-related errors. Our findings highlight the complexities of developing AI systems for mental health counseling, particularly for competencies requiring empathy and contextual understanding. We found that frontier LLMs perform at a level exceeding the minimal required level of aptitude for all key mental health counseling competencies, but fall short of expert-level performance, and that current medical LLMs do not significantly improve upon generalist models in mental health counseling competencies. This underscores the critical need for specialized, mental health counseling-specific fine-tuned LLMs that rigorously aligns with core competencies combined with appropriate human supervision before any responsible real-world deployment can be considered.
Lived Experience Not Found: LLMs Struggle to Align with Experts on Addressing Adverse Drug Reactions from Psychiatric Medication Use
Oct 24, 2024



Adverse Drug Reactions (ADRs) from psychiatric medications are the leading cause of hospitalizations among mental health patients. With healthcare systems and online communities facing limitations in resolving ADR-related issues, Large Language Models (LLMs) have the potential to fill this gap. Despite the increasing capabilities of LLMs, past research has not explored their capabilities in detecting ADRs related to psychiatric medications or in providing effective harm reduction strategies. To address this, we introduce the Psych-ADR benchmark and the Adverse Drug Reaction Response Assessment (ADRA) framework to systematically evaluate LLM performance in detecting ADR expressions and delivering expert-aligned mitigation strategies. Our analyses show that LLMs struggle with understanding the nuances of ADRs and differentiating between types of ADRs. While LLMs align with experts in terms of expressed emotions and tone of the text, their responses are more complex, harder to read, and only 70.86% aligned with expert strategies. Furthermore, they provide less actionable advice by a margin of 12.32% on average. Our work provides a comprehensive benchmark and evaluation framework for assessing LLMs in strategy-driven tasks within high-risk domains.
VisualRWKV-HD and UHD: Advancing High-Resolution Processing for Visual Language Models
Oct 15, 2024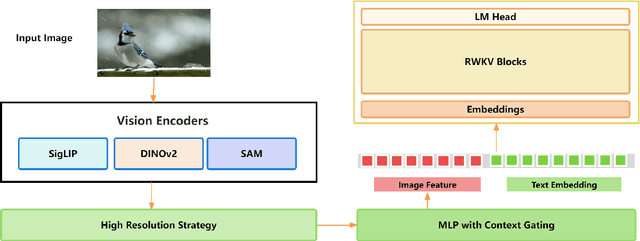

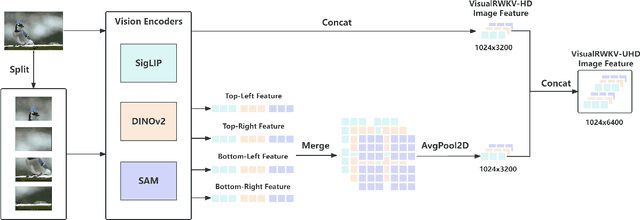
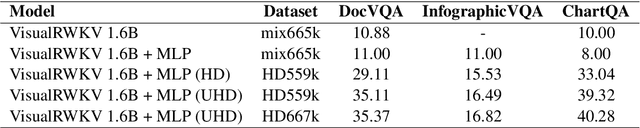
Accurately understanding complex visual information is crucial for visual language models (VLMs). Enhancing image resolution can improve visual perception capabilities, not only reducing hallucinations but also boosting performance in tasks that demand high resolution, such as text-rich or document analysis. In this paper, we present VisualRWKV-HD and VisualRWKV-UHD, two advancements in the VisualRWKV model family, specifically designed to process high-resolution visual inputs. For VisualRWKV-HD, we developed a lossless downsampling method to effectively integrate a high-resolution vision encoder with low-resolution encoders, without extending the input sequence length. For the VisualRWKV-UHD model, we enhanced image representation by dividing the image into four segments, which are then recombined with the original image. This technique allows the model to incorporate both high-resolution and low-resolution features, effectively balancing coarse and fine-grained information. As a result, the model supports resolutions up to 4096 x 4096 pixels, offering a more detailed and comprehensive visual processing capability. Both VisualRWKV-HD and VisualRWKV-UHD not only achieve strong results on VLM benchmarks but also show marked improvements in performance for text-rich tasks.
Supporters and Skeptics: LLM-based Analysis of Engagement with Mental Health (Mis)Information Content on Video-sharing Platforms
Jul 02, 2024



Over one in five adults in the US lives with a mental illness. In the face of a shortage of mental health professionals and offline resources, online short-form video content has grown to serve as a crucial conduit for disseminating mental health help and resources. However, the ease of content creation and access also contributes to the spread of misinformation, posing risks to accurate diagnosis and treatment. Detecting and understanding engagement with such content is crucial to mitigating their harmful effects on public health. We perform the first quantitative study of the phenomenon using YouTube Shorts and Bitchute as the sites of study. We contribute MentalMisinfo, a novel labeled mental health misinformation (MHMisinfo) dataset of 739 videos (639 from Youtube and 100 from Bitchute) and 135372 comments in total, using an expert-driven annotation schema. We first found that few-shot in-context learning with large language models (LLMs) are effective in detecting MHMisinfo videos. Next, we discover distinct and potentially alarming linguistic patterns in how audiences engage with MHMisinfo videos through commentary on both video-sharing platforms. Across the two platforms, comments could exacerbate prevailing stigma with some groups showing heightened susceptibility to and alignment with MHMisinfo. We discuss technical and public health-driven adaptive solutions to tackling the "epidemic" of mental health misinformation online.