 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualRWKV-HD and UHD: Advancing High-Resolution Processing for Visual Language Models
Paper and Code
Oct 15, 2024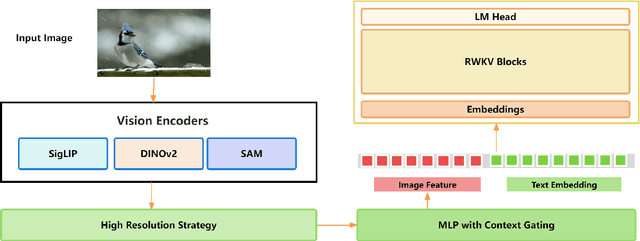

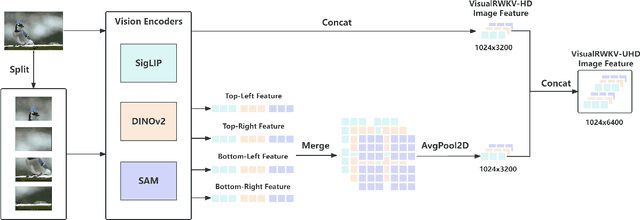
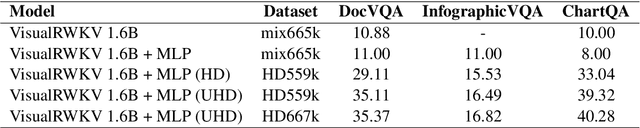
Accurately understanding complex visual information is crucial for visual language models (VLMs). Enhancing image resolution can improve visual perception capabilities, not only reducing hallucinations but also boosting performance in tasks that demand high resolution, such as text-rich or document analysis. In this paper, we present VisualRWKV-HD and VisualRWKV-UHD, two advancements in the VisualRWKV model family, specifically designed to process high-resolution visual inputs. For VisualRWKV-HD, we developed a lossless downsampling method to effectively integrate a high-resolution vision encoder with low-resolution encoders, without extending the input sequence length. For the VisualRWKV-UHD model, we enhanced image representation by dividing the image into four segments, which are then recombined with the original image. This technique allows the model to incorporate both high-resolution and low-resolution features, effectively balancing coarse and fine-grained information. As a result, the model supports resolutions up to 4096 x 4096 pixels, offering a more detailed and comprehensive visual processing capability. Both VisualRWKV-HD and VisualRWKV-UHD not only achieve strong results on VLM benchmarks but also show marked improvements in performance for text-rich tasks.