 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMAG: Self-Evolutionary Multi-Agent Code Generation
Mar 16, 2026Large Language Models (LLMs) have made significant progress in handling complex programming tasks. However, current methods rely on manual model selection and fixed workflows, which limit their ability to adapt to changing task complexities. To address this, we propose SEMAG, a Self-Evolutionary Multi-Agent code Generation framework that mimics human coding practices. It decomposes programming tasks into stages, including planning, coding, debugging, and discussion, while adapting workflows to task difficulty. Its self-evolutionary agents can access the latest models in real time and automatically upgrade the backbone model. SEMAG sets new state-of-the-art Pass@1 accuracy across benchmarks. Using identical backbone models, SEMAG outperforms prior methods by 3.3% on CodeContests. When augmented with self-evolutionary model selection that automatically identifies optimal backbones, SEMAG reaches 52.6%, showcasing both framework effectiveness and adaptability to evolving LLM capabilities.
EmbeddingRWKV: State-Centric Retrieval with Reusable States
Jan 10, 2026Current Retrieval-Augmented Generation (RAG) systems typically employ a traditional two-stage pipeline: an embedding model for initial retrieval followed by a reranker for refinement. However, this paradigm suffers from significant inefficiency due to the lack of shared information between stages, leading to substantial redundant computation. To address this limitation, we propose \textbf{State-Centric Retrieval}, a unified retrieval paradigm that utilizes "states" as a bridge to connect embedding models and rerankers. First, we perform state representation learning by fine-tuning an RWKV-based LLM, transforming it into \textbf{EmbeddingRWKV}, a unified model that serves as both an embedding model and a state backbone for extracting compact, reusable states. Building upon these reusable states, we further design a state-based reranker to fully leverage precomputed information. During reranking, the model processes only query tokens, decoupling inference cost from document length and yielding a 5.4$\times$--44.8$\times$ speedup. Furthermore, we observe that retaining all intermediate layer states is unnecessary; with a uniform layer selection strategy, our model maintains 98.62\% of full-model performance using only 25\% of the layers. Extensive experiments demonstrate that State-Centric Retrieval achieves high-quality retrieval and reranking results while significantly enhancing overall system efficiency. Code is available at \href{https://github.com/howard-hou/EmbeddingRWKV}{our GitHub repository}.
SceneRAG: Scene-level Retrieval-Augmented Generation for Video Understanding
Jun 09, 2025



Despite recent advances in retrieval-augmented generation (RAG) for video understanding, effectively understanding long-form video content remains underexplored due to the vast scale and high complexity of video data. Current RAG approaches typically segment videos into fixed-length chunks, which often disrupts the continuity of contextual information and fails to capture authentic scene boundaries. Inspired by the human ability to naturally organize continuous experiences into coherent scenes, we present SceneRAG, a unified framework that leverages large language models to segment videos into narrative-consistent scenes by processing ASR transcripts alongside temporal metadata. SceneRAG further sharpens these initial boundaries through lightweight heuristics and iterative correction. For each scene, the framework fuses information from both visual and textual modalities to extract entity relations and dynamically builds a knowledge graph, enabling robust multi-hop retrieval and generation that account for long-range dependencies. Experiments on the LongerVideos benchmark, featuring over 134 hours of diverse content, confirm that SceneRAG substantially outperforms prior baselines, achieving a win rate of up to 72.5 percent on generation tasks.
RWKV-X: A Linear Complexity Hybrid Language Model
Apr 30, 2025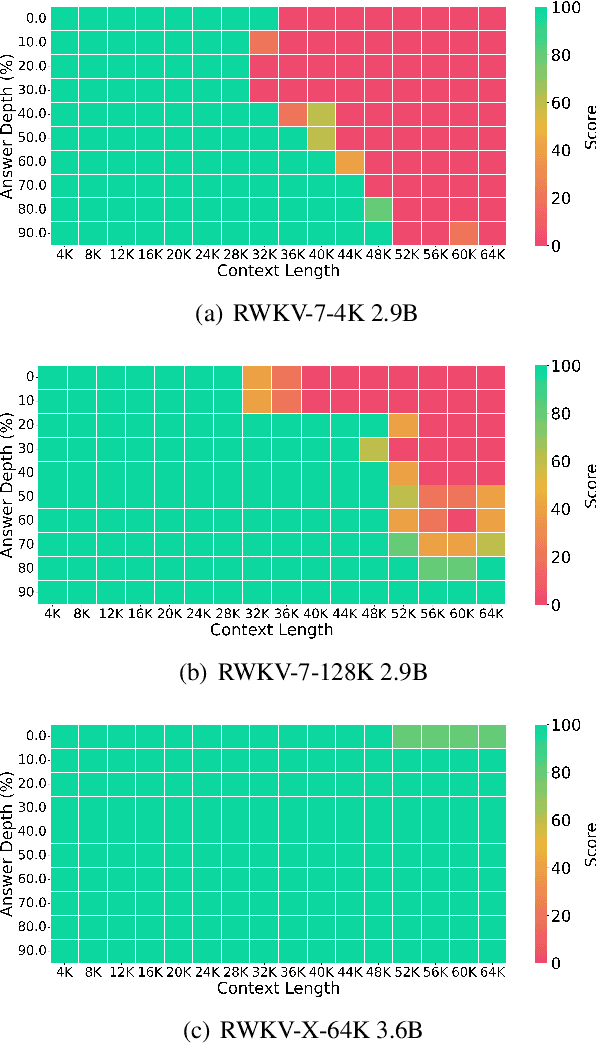
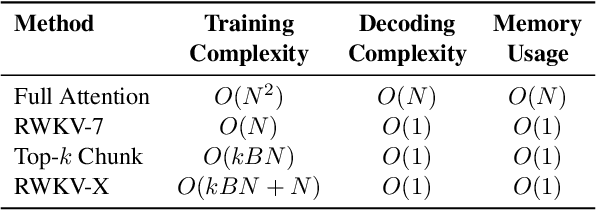
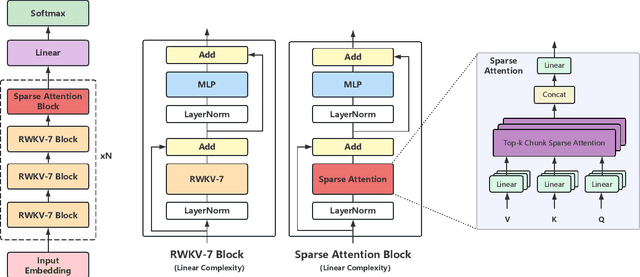
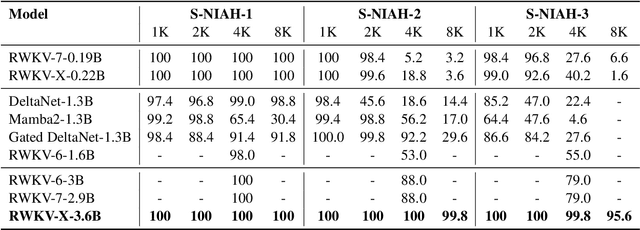
In this paper, we introduce \textbf{RWKV-X}, a novel hybrid architecture that combines the efficiency of RWKV for short-range modeling with a sparse attention mechanism designed to capture long-range context. Unlike previous hybrid approaches that rely on full attention layers and retain quadratic complexity, RWKV-X achieves linear-time complexity in training and constant-time complexity in inference decoding. We demonstrate that RWKV-X, when continually pretrained on 64K-token sequences, achieves near-perfect accuracy on the 64K passkey retrieval benchmark. It consistently outperforms prior RWKV-7 models on long-context benchmarks, while maintaining strong performance on short-context tasks. These results highlight RWKV-X as a scalable and efficient backbone for general-purpose language modeling, capable of decoding sequences up to 1 million tokens with stable speed and memory usage. To facilitate further research and analysis, we have made the checkpoints and the associated code publicly accessible at: https://github.com/howard-hou/RWKV-X.
RWKV-7 "Goose" with Expressive Dynamic State Evolution
Mar 18, 2025We present RWKV-7 "Goose", a new sequence modeling architecture, along with pre-trained language models that establish a new state-of-the-art in downstream performance at the 3 billion parameter scale on multilingual tasks, and match current SoTA English language performance despite being trained on dramatically fewer tokens than other top 3B models. Nevertheless, RWKV-7 models require only constant memory usage and constant inference time per token. RWKV-7 introduces a newly generalized formulation of the delta rule with vector-valued gating and in-context learning rates, as well as a relaxed value replacement rule. We show that RWKV-7 can perform state tracking and recognize all regular languages, while retaining parallelizability of training. This exceeds the capabilities of Transformers under standard complexity conjectures, which are limited to $\mathsf{TC}^0$. To demonstrate RWKV-7's language modeling capability, we also present an extended open source 3.1 trillion token multilingual corpus, and train four RWKV-7 models ranging from 0.19 billion to 2.9 billion parameters on this dataset. To foster openness, reproduction, and adoption, we release our models and dataset component listing at https://huggingface.co/RWKV, and our training and inference code at https://github.com/RWKV/RWKV-LM all under the Apache 2.0 License.
Delta-WKV: A Novel Meta-in-Context Learner for MRI Super-Resolution
Feb 28, 2025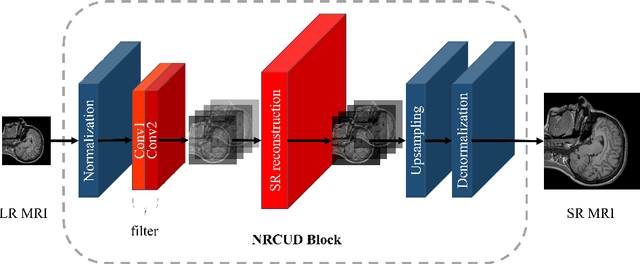
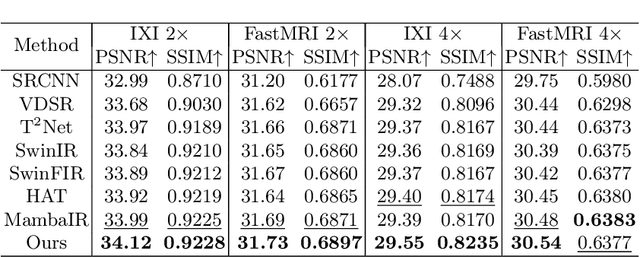
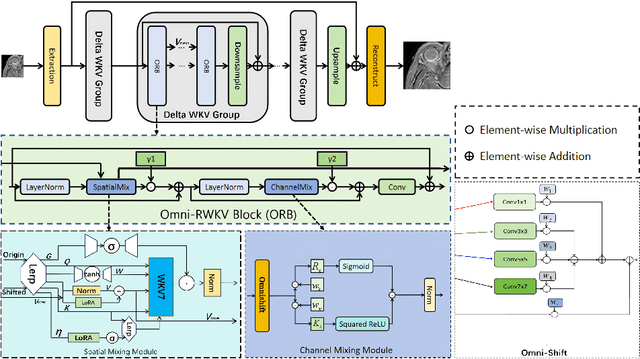
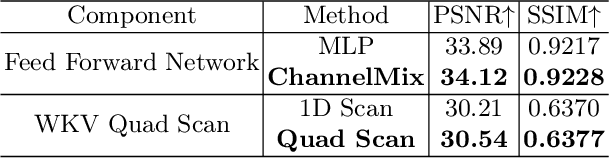
Magnetic Resonance Imaging (MRI) Super-Resolution (SR) addresses the challenges such as long scan times and expensive equipment by enhancing image resolution from low-quality inputs acquired in shorter scan times in clinical settings. However, current SR techniques still have problems such as limited ability to capture both local and global static patterns effectively and efficiently. To address these limitations, we propose Delta-WKV, a novel MRI super-resolution model that combines Meta-in-Context Learning (MiCL) with the Delta rule to better recognize both local and global patterns in MRI images. This approach allows Delta-WKV to adjust weights dynamically during inference, improving pattern recognition with fewer parameters and less computational effort, without using state-space modeling. Additionally, inspired by Receptance Weighted Key Value (RWKV), Delta-WKV uses a quad-directional scanning mechanism with time-mixing and channel-mixing structures to capture long-range dependencies while maintaining high-frequency details. Tests on the IXI and fastMRI datasets show that Delta-WKV outperforms existing methods, improving PSNR by 0.06 dB and SSIM by 0.001, while reducing training and inference times by over 15\%. These results demonstrate its efficiency and potential for clinical use with large datasets and high-resolution imaging.
RWKV-UI: UI Understanding with Enhanced Perception and Reasoning
Feb 06, 2025



Existing Visual Language Modelsoften struggle with information loss and limited reasoning abilities when handling high-resolution web interfaces that combine complex visual, textual, and interactive elements. These challenges are particularly evident in tasks requiring webpage layout comprehension and multi-step interactive reasoning. To address these challenges, we propose RWKV-UI, a Visual Language Model based on the RWKV architecture, specifically designed to handle high-resolution UI images. During model training, we introduce layout detection as a visual prompt to help the model better understand the webpage layout structures. Additionally, we design a visual prompt based on the Chain-of-Thought(CoT) mechanism, which enhances the model's ability to understand and reason about webpage content through reasoning chains. Experimental results show that RWKV-UI demonstrates significant performance improvements in high-resolution UI understanding and interactive reasoning tasks.
ImDy: Human Inverse Dynamics from Imitated Observations
Oct 23, 2024



Inverse dynamics (ID), which aims at reproducing the driven torques from human kinematic observations, has been a critical tool for gait analysis. However, it is hindered from wider application to general motion due to its limited scalability. Conventional optimization-based ID requires expensive laboratory setups, restricting its availability. To alleviate this problem, we propose to exploit the recently progressive human motion imitation algorithms to learn human inverse dynamics in a data-driven manner. The key insight is that the human ID knowledge is implicitly possessed by motion imitators, though not directly applicable. In light of this, we devise an efficient data collection pipeline with state-of-the-art motion imitation algorithms and physics simulators, resulting in a large-scale human inverse dynamics benchmark as Imitated Dynamics (ImDy). ImDy contains over 150 hours of motion with joint torque and full-body ground reaction force data. With ImDy, we train a data-driven human inverse dynamics solver ImDyS(olver) in a fully supervised manner, which conducts ID and ground reaction force estimation simultaneously. Experiments on ImDy and real-world data demonstrate the impressive competency of ImDyS in human inverse dynamics and ground reaction force estimation. Moreover, the potential of ImDy(-S) as a fundamental motion analysis tool is exhibited with downstream applications. The project page is https://foruck.github.io/ImDy/.
VisualRWKV-HD and UHD: Advancing High-Resolution Processing for Visual Language Models
Oct 15, 2024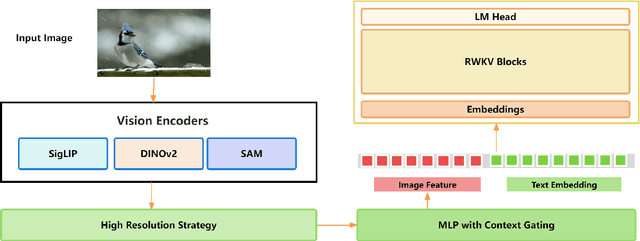

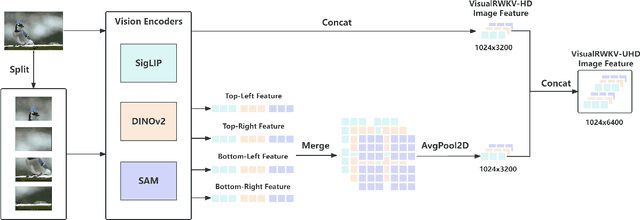
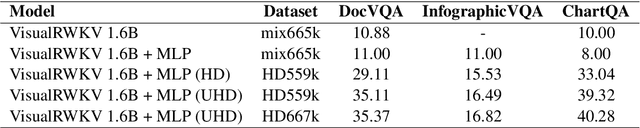
Accurately understanding complex visual information is crucial for visual language models (VLMs). Enhancing image resolution can improve visual perception capabilities, not only reducing hallucinations but also boosting performance in tasks that demand high resolution, such as text-rich or document analysis. In this paper, we present VisualRWKV-HD and VisualRWKV-UHD, two advancements in the VisualRWKV model family, specifically designed to process high-resolution visual inputs. For VisualRWKV-HD, we developed a lossless downsampling method to effectively integrate a high-resolution vision encoder with low-resolution encoders, without extending the input sequence length. For the VisualRWKV-UHD model, we enhanced image representation by dividing the image into four segments, which are then recombined with the original image. This technique allows the model to incorporate both high-resolution and low-resolution features, effectively balancing coarse and fine-grained information. As a result, the model supports resolutions up to 4096 x 4096 pixels, offering a more detailed and comprehensive visual processing capability. Both VisualRWKV-HD and VisualRWKV-UHD not only achieve strong results on VLM benchmarks but also show marked improvements in performance for text-rich tasks.
Enhancing and Accelerating Large Language Models via Instruction-Aware Contextual Compression
Aug 28, 2024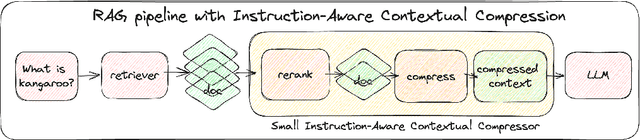


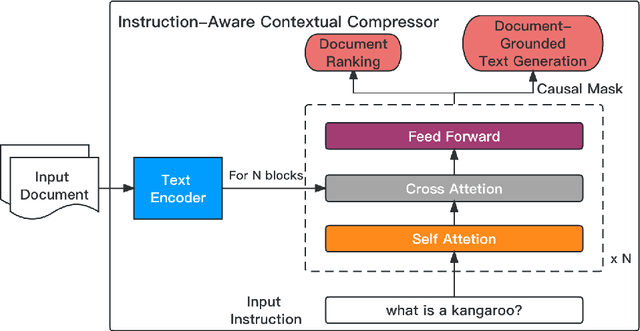
Large Language Models (LLMs) have garnered widespread attention due to their remarkable performance across various tasks. However, to mitigate the issue of hallucinations, LLMs often incorporate retrieval-augmented pipeline to provide them with rich external knowledge and context. Nevertheless, challenges stem from inaccurate and coarse-grained context retrieved from the retriever. Supplying irrelevant context to the LLMs can result in poorer responses, increased inference latency, and higher costs. This paper introduces a method called Instruction-Aware Contextual Compression, which filters out less informative content, thereby accelerating and enhancing the use of LLMs. The experimental results demonstrate that Instruction-Aware Contextual Compression notably reduces memory consumption and minimizes generation latency while maintaining performance levels comparable to those achieved with the use of the full context. Specifically, we achieved a 50% reduction in context-related costs, resulting in a 5% reduction in inference memory usage and a 2.2-fold increase in inference speed, with only a minor drop of 0.047 in Rouge-1. These findings suggest that our method strikes an effective balance between efficiency and performance.