 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceiving and Acting in First-Person: A Dataset and Benchmark for Egocentric Human-Object-Human Interactions
Aug 06, 2025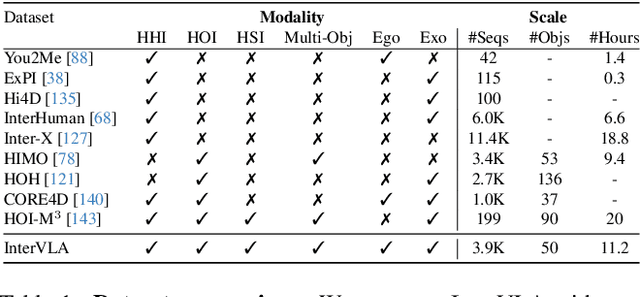

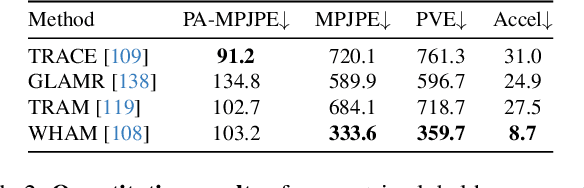

Learning action models from real-world human-centric interaction datasets is important towards building general-purpose intelligent assistants with efficiency. However, most existing datasets only offer specialist interaction category and ignore that AI assistants perceive and act based on first-person acquisition. We urge that both the generalist interaction knowledge and egocentric modality are indispensable. In this paper, we embed the manual-assisted task into a vision-language-action framework, where the assistant provides services to the instructor following egocentric vision and commands. With our hybrid RGB-MoCap system, pairs of assistants and instructors engage with multiple objects and the scene following GPT-generated scripts. Under this setting, we accomplish InterVLA, the first large-scale human-object-human interaction dataset with 11.4 hours and 1.2M frames of multimodal data, spanning 2 egocentric and 5 exocentric videos, accurate human/object motions and verbal commands. Furthermore, we establish novel benchmarks on egocentric human motion estimation, interaction synthesis, and interaction prediction with comprehensive analysis. We believe that our InterVLA testbed and the benchmarks will foster future works on building AI agents in the physical world.
ImDy: Human Inverse Dynamics from Imitated Observations
Oct 23, 2024



Inverse dynamics (ID), which aims at reproducing the driven torques from human kinematic observations, has been a critical tool for gait analysis. However, it is hindered from wider application to general motion due to its limited scalability. Conventional optimization-based ID requires expensive laboratory setups, restricting its availability. To alleviate this problem, we propose to exploit the recently progressive human motion imitation algorithms to learn human inverse dynamics in a data-driven manner. The key insight is that the human ID knowledge is implicitly possessed by motion imitators, though not directly applicable. In light of this, we devise an efficient data collection pipeline with state-of-the-art motion imitation algorithms and physics simulators, resulting in a large-scale human inverse dynamics benchmark as Imitated Dynamics (ImDy). ImDy contains over 150 hours of motion with joint torque and full-body ground reaction force data. With ImDy, we train a data-driven human inverse dynamics solver ImDyS(olver) in a fully supervised manner, which conducts ID and ground reaction force estimation simultaneously. Experiments on ImDy and real-world data demonstrate the impressive competency of ImDyS in human inverse dynamics and ground reaction force estimation. Moreover, the potential of ImDy(-S) as a fundamental motion analysis tool is exhibited with downstream applications. The project page is https://foruck.github.io/ImDy/.
MotionBank: A Large-scale Video Motion Benchmark with Disentangled Rule-based Annotations
Oct 17, 2024



In this paper, we tackle the problem of how to build and benchmark a large motion model (LMM). The ultimate goal of LMM is to serve as a foundation model for versatile motion-related tasks, e.g., human motion generation, with interpretability and generalizability. Though advanced, recent LMM-related works are still limited by small-scale motion data and costly text descriptions. Besides, previous motion benchmarks primarily focus on pure body movements, neglecting the ubiquitous motions in context, i.e., humans interacting with humans, objects, and scenes. To address these limitations, we consolidate large-scale video action datasets as knowledge banks to build MotionBank, which comprises 13 video action datasets, 1.24M motion sequences, and 132.9M frames of natural and diverse human motions. Different from laboratory-captured motions, in-the-wild human-centric videos contain abundant motions in context. To facilitate better motion text alignment, we also meticulously devise a motion caption generation algorithm to automatically produce rule-based, unbiased, and disentangled text descriptions via the kinematic characteristics for each motion. Extensive experiments show that our MotionBank is beneficial for general motion-related tasks of human motion generation, motion in-context generation, and motion understanding. Video motions together with the rule-based text annotations could serve as an efficient alternative for larger LMMs. Our dataset, codes, and benchmark will be publicly available at https://github.com/liangxuy/MotionBank.