 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeThink: Toward General-purpose Vision-Language Reasoning via Reinforcement Learning
Jun 09, 2025Building on the success of text-based reasoning models like DeepSeek-R1, extending these capabilities to multimodal reasoning holds great promise. While recent works have attempted to adapt DeepSeek-R1-style reinforcement learning (RL) training paradigms to multimodal large language models (MLLM), focusing on domain-specific tasks like math and visual perception, a critical question remains: How can we achieve the general-purpose visual-language reasoning through RL? To address this challenge, we make three key efforts: (1) A novel Scalable Multimodal QA Synthesis pipeline that autonomously generates context-aware, reasoning-centric question-answer (QA) pairs directly from the given images. (2) The open-source WeThink dataset containing over 120K multimodal QA pairs with annotated reasoning paths, curated from 18 diverse dataset sources and covering various question domains. (3) A comprehensive exploration of RL on our dataset, incorporating a hybrid reward mechanism that combines rule-based verification with model-based assessment to optimize RL training efficiency across various task domains. Across 14 diverse MLLM benchmarks, we demonstrate that our WeThink dataset significantly enhances performance, from mathematical reasoning to diverse general multimodal tasks. Moreover, we show that our automated data pipeline can continuously increase data diversity to further improve model performance.
MotionBank: A Large-scale Video Motion Benchmark with Disentangled Rule-based Annotations
Oct 17, 2024



In this paper, we tackle the problem of how to build and benchmark a large motion model (LMM). The ultimate goal of LMM is to serve as a foundation model for versatile motion-related tasks, e.g., human motion generation, with interpretability and generalizability. Though advanced, recent LMM-related works are still limited by small-scale motion data and costly text descriptions. Besides, previous motion benchmarks primarily focus on pure body movements, neglecting the ubiquitous motions in context, i.e., humans interacting with humans, objects, and scenes. To address these limitations, we consolidate large-scale video action datasets as knowledge banks to build MotionBank, which comprises 13 video action datasets, 1.24M motion sequences, and 132.9M frames of natural and diverse human motions. Different from laboratory-captured motions, in-the-wild human-centric videos contain abundant motions in context. To facilitate better motion text alignment, we also meticulously devise a motion caption generation algorithm to automatically produce rule-based, unbiased, and disentangled text descriptions via the kinematic characteristics for each motion. Extensive experiments show that our MotionBank is beneficial for general motion-related tasks of human motion generation, motion in-context generation, and motion understanding. Video motions together with the rule-based text annotations could serve as an efficient alternative for larger LMMs. Our dataset, codes, and benchmark will be publicly available at https://github.com/liangxuy/MotionBank.
EE-MLLM: A Data-Efficient and Compute-Efficient Multimodal Large Language Model
Aug 21, 2024



In the realm of multimodal research, numerous studies leverage substantial image-text pairs to conduct modal alignment learning, transforming Large Language Models (LLMs) into Multimodal LLMs and excelling in a variety of visual-language tasks. The prevailing methodologies primarily fall into two categories: self-attention-based and cross-attention-based methods. While self-attention-based methods offer superior data efficiency due to their simple MLP architecture, they often suffer from lower computational efficiency due to concatenating visual and textual tokens as input for LLM. Conversely, cross-attention-based methods, although less data-efficient due to additional learnable parameters, exhibit higher computational efficiency by avoiding long sequence input for LLM. To address these trade-offs, we introduce the Data-Efficient and Compute-Efficient Multimodal Large Language Model (EE-MLLM). Without introducing additional modules or learnable parameters, EE-MLLM achieves both data and compute efficiency. Specifically, we modify the original self-attention mechanism in MLLM to a composite attention mechanism. This mechanism has two key characteristics: 1) Eliminating the computational overhead of self-attention within visual tokens to achieve compute efficiency, and 2) Reusing the weights on each layer of LLM to facilitate effective modality alignment between vision and language for data efficiency. Experimental results demonstrate the effectiveness of EE-MLLM across a range of benchmarks, including general-purpose datasets like MMBench and SeedBench, as well as fine-grained tasks such as TextVQA and DocVQA.
Visual Perception by Large Language Model's Weights
May 30, 2024



Existing Multimodal Large Language Models (MLLMs) follow the paradigm that perceives visual information by aligning visual features with the input space of Large Language Models (LLMs), and concatenating visual tokens with text tokens to form a unified sequence input for LLMs. These methods demonstrate promising results on various vision-language tasks but are limited by the high computational effort due to the extended input sequence resulting from the involvement of visual tokens. In this paper, instead of input space alignment, we propose a novel parameter space alignment paradigm that represents visual information as model weights. For each input image, we use a vision encoder to extract visual features, convert features into perceptual weights, and merge the perceptual weights with LLM's weights. In this way, the input of LLM does not require visual tokens, which reduces the length of the input sequence and greatly improves efficiency. Following this paradigm, we propose VLoRA with the perceptual weights generator. The perceptual weights generator is designed to convert visual features to perceptual weights with low-rank property, exhibiting a form similar to LoRA. The experimental results show that our VLoRA achieves comparable performance on various benchmarks for MLLMs, while significantly reducing the computational costs for both training and inference. The code and models will be made open-source.
Multi-Modal Generative Embedding Model
May 29, 2024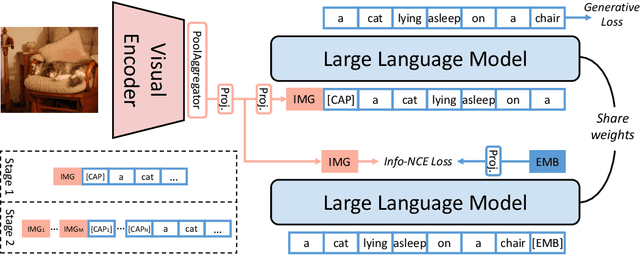



Most multi-modal tasks can be formulated into problems of either generation or embedding. Existing models usually tackle these two types of problems by decoupling language modules into a text decoder for generation, and a text encoder for embedding. To explore the minimalism of multi-modal paradigms, we attempt to achieve only one model per modality in this work. We propose a Multi-Modal Generative Embedding Model (MM-GEM), whereby the generative and embedding objectives are encapsulated in one Large Language Model. We also propose a PoolAggregator to boost efficiency and enable the ability of fine-grained embedding and generation. A surprising finding is that these two objectives do not significantly conflict with each other. For example, MM-GEM instantiated from ViT-Large and TinyLlama shows competitive performance on benchmarks for multimodal embedding models such as cross-modal retrieval and zero-shot classification, while has good ability of image captioning. Additionally, MM-GEM can seamlessly execute region-level image caption generation and retrieval tasks. Besides, the advanced text model in MM-GEM brings over 5% improvement in Recall@1 for long text and image retrieval.
Text-Only Image Captioning with Multi-Context Data Generation
May 29, 2023

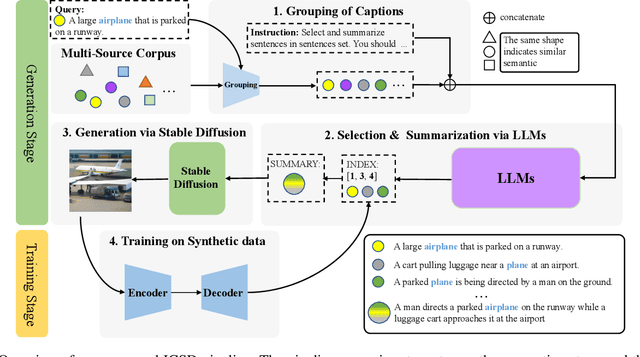

Text-only Image Captioning (TIC) is an approach that aims to construct a model solely based on text that can accurately describe images. Recently, diffusion models have demonstrated remarkable capabilities in generating high-quality images that are semantically coherent with given texts. This presents an opportunity to generate synthetic training images for TIC. However, we have identified a challenge that the images generated from simple descriptions typically exhibit a single perspective with one or limited contexts, which is not aligned with the complexity of real-world scenes in the image domain. In this paper, we propose a novel framework that addresses this issue by introducing multi-context data generation. Starting with an initial text corpus, our framework employs a large language model to select multiple sentences that describe the same scene from various perspectives. These sentences are then summarized into a single sentence with multiple contexts. We generate simple images using the straightforward sentences and complex images using the summarized sentences through diffusion models. Finally, we train the model exclusively using the synthetic image-text pairs obtained from this process. Experimental results demonstrate that our proposed framework effectively tackles the central challenge we have identified, achieving the state-of-the-art performance on popular datasets such as MSCOCO, Flickr30k, and SS1M.
A Similarity Alignment Model for Video Copy Segment Matching
May 25, 2023



With the development of multimedia technology, Video Copy Detection has been a crucial problem for social media platforms. Meta AI hold Video Similarity Challenge on CVPR 2023 to push the technology forward. In this report, we share our winner solutions on Matching Track. We propose a Similarity Alignment Model(SAM) for video copy segment matching. Our SAM exhibits superior performance compared to other competitors, with a 0.108 / 0.144 absolute improvement over the second-place competitor in Phase 1 / Phase 2. Code is available at https://github.com/FeipengMa6/VSC22-Submission/tree/main/VSC22-Matching-Track-1st.
A Dual-level Detection Method for Video Copy Detection
May 21, 2023With the development of multimedia technology, Video Copy Detection has been a crucial problem for social media platforms. Meta AI hold Video Similarity Challenge on CVPR 2023 to push the technology forward. In this paper, we share our winner solutions on both tracks to help progress in this area. For Descriptor Track, we propose a dual-level detection method with Video Editing Detection (VED) and Frame Scenes Detection (FSD) to tackle the core challenges on Video Copy Detection. Experimental results demonstrate the effectiveness and efficiency of our proposed method. Code is available at https://github.com/FeipengMa6/VSC22-Submission.