 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
Aug 07, 2025We present a simple yet theoretically motivated improvement to Supervised Fine-Tuning (SFT) for the Large Language Model (LLM), addressing its limited generalization compared to reinforcement learning (RL). Through mathematical analysis, we reveal that standard SFT gradients implicitly encode a problematic reward structure that may severely restrict the generalization capabilities of model. To rectify this, we propose Dynamic Fine-Tuning (DFT), stabilizing gradient updates for each token by dynamically rescaling the objective function with the probability of this token. Remarkably, this single-line code change significantly outperforms standard SFT across multiple challenging benchmarks and base models, demonstrating greatly improved generalization. Additionally, our approach shows competitive results in offline RL settings, offering an effective yet simpler alternative. This work bridges theoretical insight and practical solutions, substantially advancing SFT performance. The code will be available at https://github.com/yongliang-wu/DFT.
PerturboLLaVA: Reducing Multimodal Hallucinations with Perturbative Visual Training
Mar 09, 2025This paper aims to address the challenge of hallucinations in Multimodal Large Language Models (MLLMs) particularly for dense image captioning tasks. To tackle the challenge, we identify the current lack of a metric that finely measures the caption quality in concept level. We hereby introduce HalFscore, a novel metric built upon the language graph and is designed to evaluate both the accuracy and completeness of dense captions at a granular level. Additionally, we identify the root cause of hallucination as the model's over-reliance on its language prior. To address this, we propose PerturboLLaVA, which reduces the model's reliance on the language prior by incorporating adversarially perturbed text during training. This method enhances the model's focus on visual inputs, effectively reducing hallucinations and producing accurate, image-grounded descriptions without incurring additional computational overhead. PerturboLLaVA significantly improves the fidelity of generated captions, outperforming existing approaches in handling multimodal hallucinations and achieving improved performance across general multimodal benchmarks.
A Study on Educational Data Analysis and Personalized Feedback Report Generation Based on Tags and ChatGPT
Jan 12, 2025This study introduces a novel method that employs tag annotation coupled with the ChatGPT language model to analyze student learning behaviors and generate personalized feedback. Central to this approach is the conversion of complex student data into an extensive set of tags, which are then decoded through tailored prompts to deliver constructive feedback that encourages rather than discourages students. This methodology focuses on accurately feeding student data into large language models and crafting prompts that enhance the constructive nature of feedback. The effectiveness of this approach was validated through surveys conducted with over 20 mathematics teachers, who confirmed the reliability of the generated reports. This method can be seamlessly integrated into intelligent adaptive learning systems or provided as a tool to significantly reduce the workload of teachers, providing accurate and timely feedback to students. By transforming raw educational data into interpretable tags, this method supports the provision of efficient and timely personalized learning feedback that offers constructive suggestions tailored to individual learner needs.
AI Agent for Education: von Neumann Multi-Agent System Framework
Dec 30, 2024The development of large language models has ushered in new paradigms for education. This paper centers on the multi-Agent system in education and proposes the von Neumann multi-Agent system framework. It breaks down each AI Agent into four modules: control unit, logic unit, storage unit, and input-output devices, defining four types of operations: task deconstruction, self-reflection, memory processing, and tool invocation. Furthermore, it introduces related technologies such as Chain-of-Thought, Reson+Act, and Multi-Agent Debate associated with these four types of operations. The paper also discusses the ability enhancement cycle of a multi-Agent system for education, including the outer circulation for human learners to promote knowledge construction and the inner circulation for LLM-based-Agents to enhance swarm intelligence. Through collaboration and reflection, the multi-Agent system can better facilitate human learners' learning and enhance their teaching abilities in this process.
Number it: Temporal Grounding Videos like Flipping Manga
Nov 15, 2024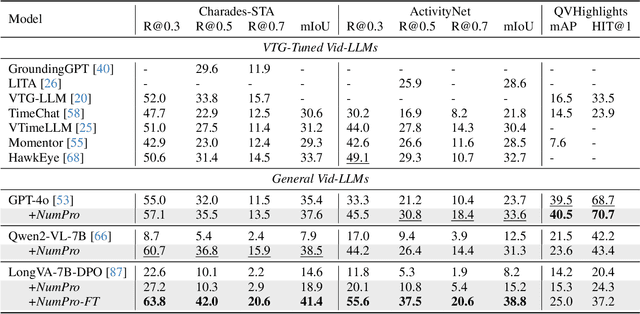

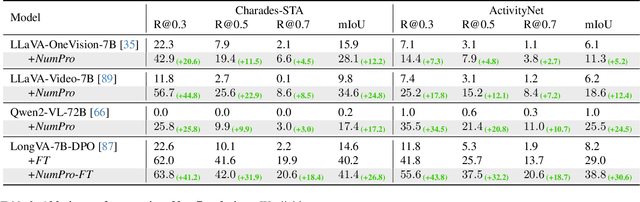
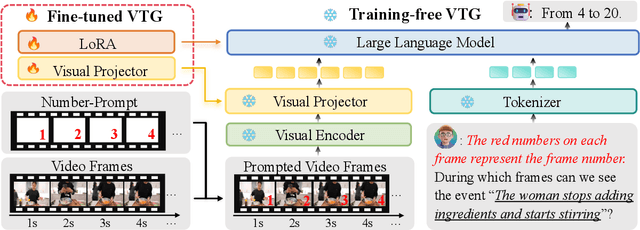
Video Large Language Models (Vid-LLMs) have made remarkable advancements in comprehending video content for QA dialogue. However, they struggle to extend this visual understanding to tasks requiring precise temporal localization, known as Video Temporal Grounding (VTG). To address this gap, we introduce Number-Prompt (NumPro), a novel method that empowers Vid-LLMs to bridge visual comprehension with temporal grounding by adding unique numerical identifiers to each video frame. Treating a video as a sequence of numbered frame images, NumPro transforms VTG into an intuitive process: flipping through manga panels in sequence. This allows Vid-LLMs to "read" event timelines, accurately linking visual content with corresponding temporal information. Our experiments demonstrate that NumPro significantly boosts VTG performance of top-tier Vid-LLMs without additional computational cost. Furthermore, fine-tuning on a NumPro-enhanced dataset defines a new state-of-the-art for VTG, surpassing previous top-performing methods by up to 6.9\% in mIoU for moment retrieval and 8.5\% in mAP for highlight detection. The code will be available at https://github.com/yongliang-wu/NumPro.
MMAR: Towards Lossless Multi-Modal Auto-Regressive Probabilistic Modeling
Oct 15, 2024Recent advancements in multi-modal large language models have propelled the development of joint probabilistic models capable of both image understanding and generation. However, we have identified that recent methods inevitably suffer from loss of image information during understanding task, due to either image discretization or diffusion denoising steps. To address this issue, we propose a novel Multi-Modal Auto-Regressive (MMAR) probabilistic modeling framework. Unlike discretization line of method, MMAR takes in continuous-valued image tokens to avoid information loss. Differing from diffusion-based approaches, we disentangle the diffusion process from auto-regressive backbone model by employing a light-weight diffusion head on top each auto-regressed image patch embedding. In this way, when the model transits from image generation to understanding through text generation, the backbone model's hidden representation of the image is not limited to the last denoising step. To successfully train our method, we also propose a theoretically proven technique that addresses the numerical stability issue and a training strategy that balances the generation and understanding task goals. Through extensive evaluations on 18 image understanding benchmarks, MMAR demonstrates much more superior performance than other joint multi-modal models, matching the method that employs pretrained CLIP vision encoder, meanwhile being able to generate high quality images at the same time. We also showed that our method is scalable with larger data and model size.
EE-MLLM: A Data-Efficient and Compute-Efficient Multimodal Large Language Model
Aug 21, 2024



In the realm of multimodal research, numerous studies leverage substantial image-text pairs to conduct modal alignment learning, transforming Large Language Models (LLMs) into Multimodal LLMs and excelling in a variety of visual-language tasks. The prevailing methodologies primarily fall into two categories: self-attention-based and cross-attention-based methods. While self-attention-based methods offer superior data efficiency due to their simple MLP architecture, they often suffer from lower computational efficiency due to concatenating visual and textual tokens as input for LLM. Conversely, cross-attention-based methods, although less data-efficient due to additional learnable parameters, exhibit higher computational efficiency by avoiding long sequence input for LLM. To address these trade-offs, we introduce the Data-Efficient and Compute-Efficient Multimodal Large Language Model (EE-MLLM). Without introducing additional modules or learnable parameters, EE-MLLM achieves both data and compute efficiency. Specifically, we modify the original self-attention mechanism in MLLM to a composite attention mechanism. This mechanism has two key characteristics: 1) Eliminating the computational overhead of self-attention within visual tokens to achieve compute efficiency, and 2) Reusing the weights on each layer of LLM to facilitate effective modality alignment between vision and language for data efficiency. Experimental results demonstrate the effectiveness of EE-MLLM across a range of benchmarks, including general-purpose datasets like MMBench and SeedBench, as well as fine-grained tasks such as TextVQA and DocVQA.
Enhancing Explainability of Knowledge Learning Paths: Causal Knowledge Networks
Jun 26, 2024A reliable knowledge structure is a prerequisite for building effective adaptive learning systems and intelligent tutoring systems. Pursuing an explainable and trustworthy knowledge structure, we propose a method for constructing causal knowledge networks. This approach leverages Bayesian networks as a foundation and incorporates causal relationship analysis to derive a causal network. Additionally, we introduce a dependable knowledge-learning path recommendation technique built upon this framework, improving teaching and learning quality while maintaining transparency in the decision-making process.
Visual Perception by Large Language Model's Weights
May 30, 2024



Existing Multimodal Large Language Models (MLLMs) follow the paradigm that perceives visual information by aligning visual features with the input space of Large Language Models (LLMs), and concatenating visual tokens with text tokens to form a unified sequence input for LLMs. These methods demonstrate promising results on various vision-language tasks but are limited by the high computational effort due to the extended input sequence resulting from the involvement of visual tokens. In this paper, instead of input space alignment, we propose a novel parameter space alignment paradigm that represents visual information as model weights. For each input image, we use a vision encoder to extract visual features, convert features into perceptual weights, and merge the perceptual weights with LLM's weights. In this way, the input of LLM does not require visual tokens, which reduces the length of the input sequence and greatly improves efficiency. Following this paradigm, we propose VLoRA with the perceptual weights generator. The perceptual weights generator is designed to convert visual features to perceptual weights with low-rank property, exhibiting a form similar to LoRA. The experimental results show that our VLoRA achieves comparable performance on various benchmarks for MLLMs, while significantly reducing the computational costs for both training and inference. The code and models will be made open-source.
Multi-Modal Generative Embedding Model
May 29, 2024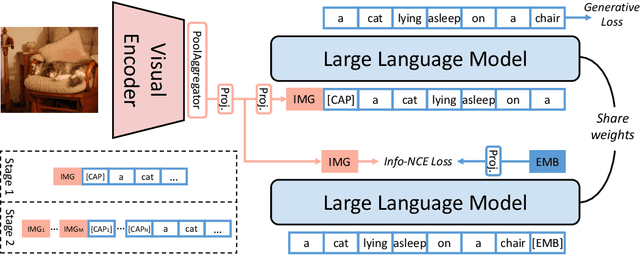



Most multi-modal tasks can be formulated into problems of either generation or embedding. Existing models usually tackle these two types of problems by decoupling language modules into a text decoder for generation, and a text encoder for embedding. To explore the minimalism of multi-modal paradigms, we attempt to achieve only one model per modality in this work. We propose a Multi-Modal Generative Embedding Model (MM-GEM), whereby the generative and embedding objectives are encapsulated in one Large Language Model. We also propose a PoolAggregator to boost efficiency and enable the ability of fine-grained embedding and generation. A surprising finding is that these two objectives do not significantly conflict with each other. For example, MM-GEM instantiated from ViT-Large and TinyLlama shows competitive performance on benchmarks for multimodal embedding models such as cross-modal retrieval and zero-shot classification, while has good ability of image captioning. Additionally, MM-GEM can seamlessly execute region-level image caption generation and retrieval tasks. Besides, the advanced text model in MM-GEM brings over 5% improvement in Recall@1 for long text and image retrieval.