 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREVERSE: Reinforcing Evidence Verification and Search for Agentic Image geo-localization
May 26, 2026Image geo-localization aims to determine where a photograph was taken, a task that often requires more than recognizing visible landmarks. Human experts typically solve it through an iterative workflow: they inspect informative regions, form location hypotheses, seek external evidence, and revise their judgments as new clues appear. Existing methods only partially capture this process: direct prediction methods bypass evidence acquisition altogether, while retrieval-augmented methods introduce external evidence but usually provide limited supervision on the intermediate decisions of where to search, how to query, and how to filter noisy results. We present REVERSE, a framework that reinforces the interplay between evidence search and verification to enable multi-turn agentic reasoning. REVERSE teaches three intermediate decisions: where to look, what to query, and what evidence to trust. To support this, we construct tool-grounded trajectories with annotated region selections, search observations, and geo-informative evidence labels, and introduce process rewards for visual grounding, query utility, and evidence discrimination. An offline search cache makes retrieval observations stable and reusable during reinforcement learning, enabling dense supervision over noisy search results. With a 4B model, REVERSE outperforms strong retrieval-augmented baselines and rivals substantially larger models on Im2GPS3k and YFCC4k. Code is available at https://github.com/yonglleee/REVERSE.
Beyond Chain-of-Thought: Rewrite as a Universal Interface for Generative Multimodal Embeddings
Apr 24, 2026Multimodal Large Language Models (MLLMs) have emerged as a promising foundation for universal multimodal embeddings. Recent studies have shown that reasoning-driven generative multimodal embeddings can outperform discriminative embeddings on several embedding tasks. However, Chain-of-Thought (CoT) reasoning tends to generate redundant thinking steps and introduce semantic ambiguity in the summarized answers in broader retrieval scenarios. To address this limitation, we propose Rewrite-driven Multimodal Embedding (RIME), a unified framework that jointly optimizes generation and embedding through a retrieval-friendly rewrite. Meanwhile, we present the Cross-Mode Alignment (CMA) to bridge the generative and discriminative embedding spaces, enabling flexible mutual retrieval to trade off efficiency and accuracy. Based on this, we also introduce Refine Reinforcement Learning (Refine-RL) that treats discriminative embeddings as stable semantic anchors to guide the rewrite optimization. Extensive experiments on MMEB-V2, MRMR and UVRB demonstrate that RIME substantially outperforms prior generative embedding models while significantly reducing the length of thinking.
AdaMem: Adaptive User-Centric Memory for Long-Horizon Dialogue Agents
Mar 17, 2026Large language model (LLM) agents increasingly rely on external memory to support long-horizon interaction, personalized assistance, and multi-step reasoning. However, existing memory systems still face three core challenges: they often rely too heavily on semantic similarity, which can miss evidence crucial for user-centric understanding; they frequently store related experiences as isolated fragments, weakening temporal and causal coherence; and they typically use static memory granularities that do not adapt well to the requirements of different questions. We propose AdaMem, an adaptive user-centric memory framework for long-horizon dialogue agents. AdaMem organizes dialogue history into working, episodic, persona, and graph memories, enabling the system to preserve recent context, structured long-term experiences, stable user traits, and relation-aware connections within a unified framework. At inference time, AdaMem first resolves the target participant, then builds a question-conditioned retrieval route that combines semantic retrieval with relation-aware graph expansion only when needed, and finally produces the answer through a role-specialized pipeline for evidence synthesis and response generation. We evaluate AdaMem on the LoCoMo and PERSONAMEM benchmarks for long-horizon reasoning and user modeling. Experimental results show that AdaMem achieves state-of-the-art performance on both benchmarks. The code will be released upon acceptance.
SAIL: Self-Amplified Iterative Learning for Diffusion Model Alignment with Minimal Human Feedback
Feb 05, 2026Aligning diffusion models with human preferences remains challenging, particularly when reward models are unavailable or impractical to obtain, and collecting large-scale preference datasets is prohibitively expensive. \textit{This raises a fundamental question: can we achieve effective alignment using only minimal human feedback, without auxiliary reward models, by unlocking the latent capabilities within diffusion models themselves?} In this paper, we propose \textbf{SAIL} (\textbf{S}elf-\textbf{A}mplified \textbf{I}terative \textbf{L}earning), a novel framework that enables diffusion models to act as their own teachers through iterative self-improvement. Starting from a minimal seed set of human-annotated preference pairs, SAIL operates in a closed-loop manner where the model progressively generates diverse samples, self-annotates preferences based on its evolving understanding, and refines itself using this self-augmented dataset. To ensure robust learning and prevent catastrophic forgetting, we introduce a ranked preference mixup strategy that carefully balances exploration with adherence to initial human priors. Extensive experiments demonstrate that SAIL consistently outperforms state-of-the-art methods across multiple benchmarks while using merely 6\% of the preference data required by existing approaches, revealing that diffusion models possess remarkable self-improvement capabilities that, when properly harnessed, can effectively replace both large-scale human annotation and external reward models.
WeThink: Toward General-purpose Vision-Language Reasoning via Reinforcement Learning
Jun 09, 2025Building on the success of text-based reasoning models like DeepSeek-R1, extending these capabilities to multimodal reasoning holds great promise. While recent works have attempted to adapt DeepSeek-R1-style reinforcement learning (RL) training paradigms to multimodal large language models (MLLM), focusing on domain-specific tasks like math and visual perception, a critical question remains: How can we achieve the general-purpose visual-language reasoning through RL? To address this challenge, we make three key efforts: (1) A novel Scalable Multimodal QA Synthesis pipeline that autonomously generates context-aware, reasoning-centric question-answer (QA) pairs directly from the given images. (2) The open-source WeThink dataset containing over 120K multimodal QA pairs with annotated reasoning paths, curated from 18 diverse dataset sources and covering various question domains. (3) A comprehensive exploration of RL on our dataset, incorporating a hybrid reward mechanism that combines rule-based verification with model-based assessment to optimize RL training efficiency across various task domains. Across 14 diverse MLLM benchmarks, we demonstrate that our WeThink dataset significantly enhances performance, from mathematical reasoning to diverse general multimodal tasks. Moreover, we show that our automated data pipeline can continuously increase data diversity to further improve model performance.
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Mar 13, 2025Large Language Models have demonstrated remarkable reasoning capability in complex textual tasks. However, multimodal reasoning, which requires integrating visual and textual information, remains a significant challenge. Existing visual-language models often struggle to effectively analyze and reason visual content, resulting in suboptimal performance on complex reasoning tasks. Moreover, the absence of comprehensive benchmarks hinders the accurate assessment of multimodal reasoning capabilities. In this paper, we introduce R1-Onevision, a multimodal reasoning model designed to bridge the gap between visual perception and deep reasoning. To achieve this, we propose a cross-modal reasoning pipeline that transforms images into formal textural representations, enabling precise language-based reasoning. Leveraging this pipeline, we construct the R1-Onevision dataset which provides detailed, step-by-step multimodal reasoning annotations across diverse domains. We further develop the R1-Onevision model through supervised fine-tuning and reinforcement learning to cultivate advanced reasoning and robust generalization abilities. To comprehensively evaluate multimodal reasoning performance across different grades, we introduce R1-Onevision-Bench, a benchmark aligned with human educational stages, covering exams from junior high school to university and beyond. Experimental results show that R1-Onevision achieves state-of-the-art performance, outperforming models such as GPT-4o and Qwen2.5-VL on multiple challenging multimodal reasoning benchmarks.
MMAR: Towards Lossless Multi-Modal Auto-Regressive Probabilistic Modeling
Oct 15, 2024Recent advancements in multi-modal large language models have propelled the development of joint probabilistic models capable of both image understanding and generation. However, we have identified that recent methods inevitably suffer from loss of image information during understanding task, due to either image discretization or diffusion denoising steps. To address this issue, we propose a novel Multi-Modal Auto-Regressive (MMAR) probabilistic modeling framework. Unlike discretization line of method, MMAR takes in continuous-valued image tokens to avoid information loss. Differing from diffusion-based approaches, we disentangle the diffusion process from auto-regressive backbone model by employing a light-weight diffusion head on top each auto-regressed image patch embedding. In this way, when the model transits from image generation to understanding through text generation, the backbone model's hidden representation of the image is not limited to the last denoising step. To successfully train our method, we also propose a theoretically proven technique that addresses the numerical stability issue and a training strategy that balances the generation and understanding task goals. Through extensive evaluations on 18 image understanding benchmarks, MMAR demonstrates much more superior performance than other joint multi-modal models, matching the method that employs pretrained CLIP vision encoder, meanwhile being able to generate high quality images at the same time. We also showed that our method is scalable with larger data and model size.
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
Nov 30, 2023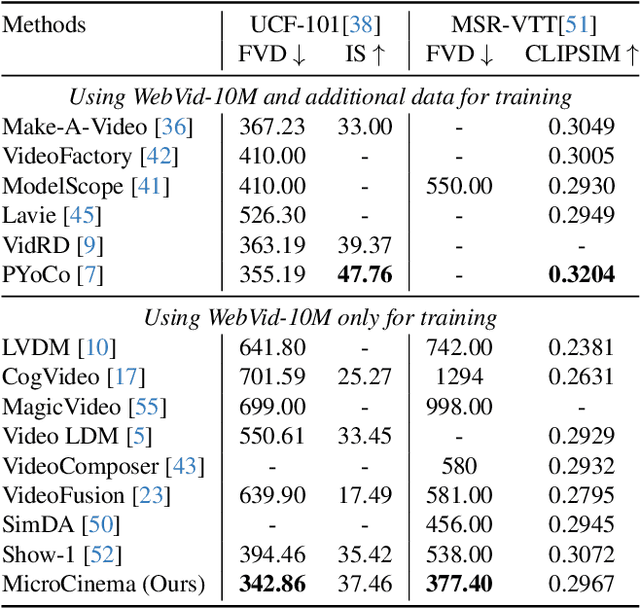
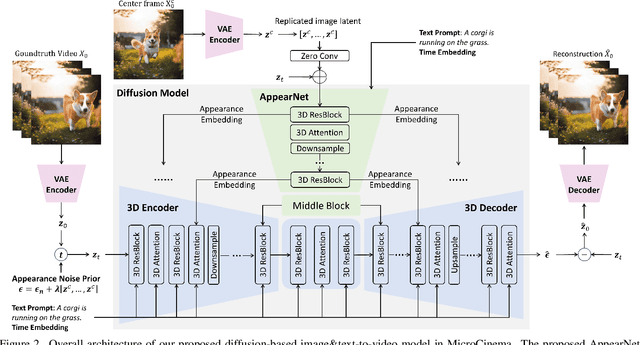
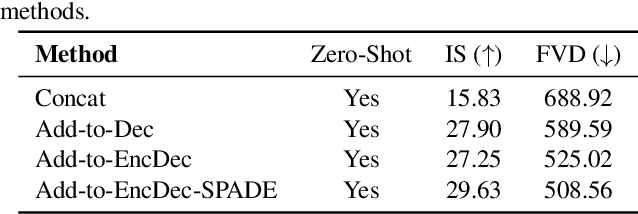
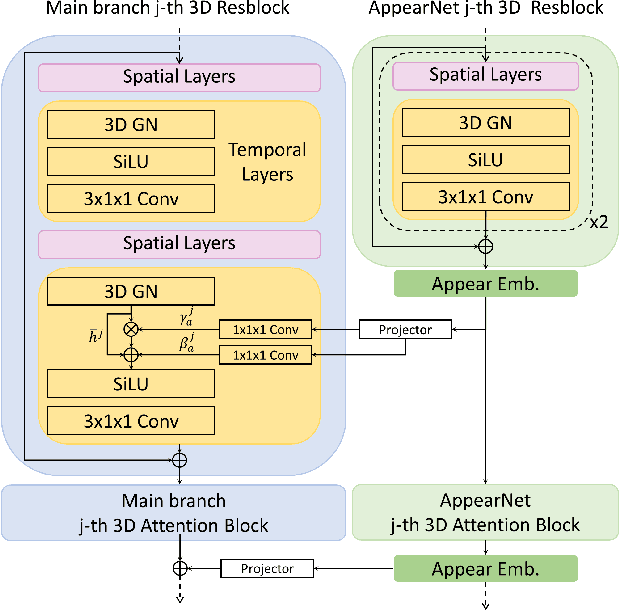
We present MicroCinema, a straightforward yet effective framework for high-quality and coherent text-to-video generation. Unlike existing approaches that align text prompts with video directly, MicroCinema introduces a Divide-and-Conquer strategy which divides the text-to-video into a two-stage process: text-to-image generation and image\&text-to-video generation. This strategy offers two significant advantages. a) It allows us to take full advantage of the recent advances in text-to-image models, such as Stable Diffusion, Midjourney, and DALLE, to generate photorealistic and highly detailed images. b) Leveraging the generated image, the model can allocate less focus to fine-grained appearance details, prioritizing the efficient learning of motion dynamics. To implement this strategy effectively, we introduce two core designs. First, we propose the Appearance Injection Network, enhancing the preservation of the appearance of the given image. Second, we introduce the Appearance Noise Prior, a novel mechanism aimed at maintaining the capabilities of pre-trained 2D diffusion models. These design elements empower MicroCinema to generate high-quality videos with precise motion, guided by the provided text prompts. Extensive experiments demonstrate the superiority of the proposed framework. Concretely, MicroCinema achieves SOTA zero-shot FVD of 342.86 on UCF-101 and 377.40 on MSR-VTT. See https://wangyanhui666.github.io/MicroCinema.github.io/ for video samples.
ART$\boldsymbol{\cdot}$V: Auto-Regressive Text-to-Video Generation with Diffusion Models
Nov 30, 2023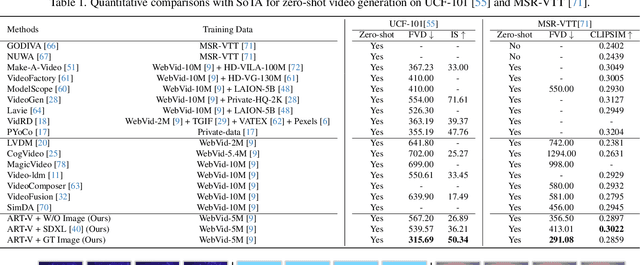
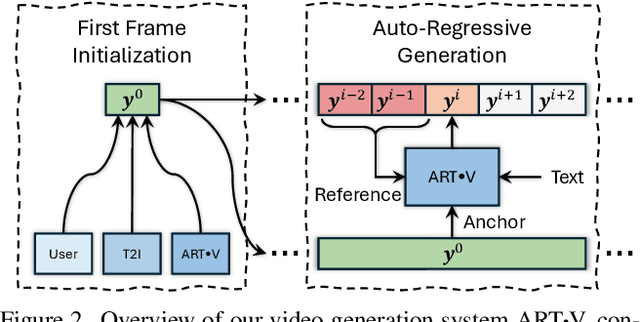
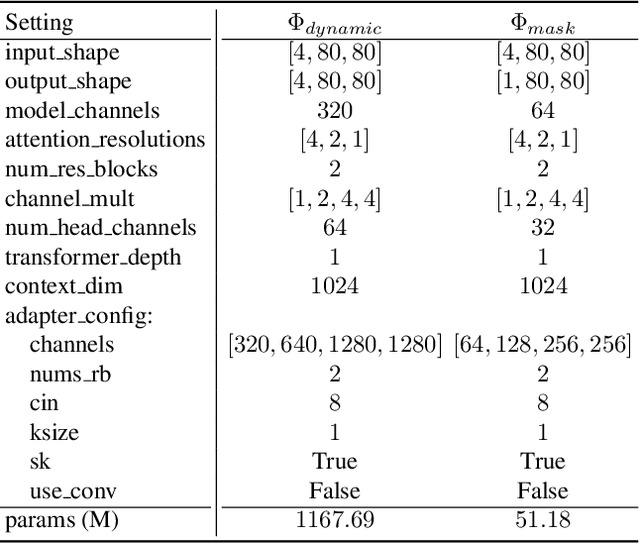
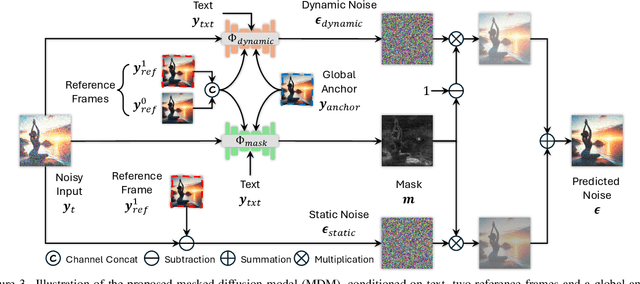
We present ART$\boldsymbol{\cdot}$V, an efficient framework for auto-regressive video generation with diffusion models. Unlike existing methods that generate entire videos in one-shot, ART$\boldsymbol{\cdot}$V generates a single frame at a time, conditioned on the previous ones. The framework offers three distinct advantages. First, it only learns simple continual motions between adjacent frames, therefore avoiding modeling complex long-range motions that require huge training data. Second, it preserves the high-fidelity generation ability of the pre-trained image diffusion models by making only minimal network modifications. Third, it can generate arbitrarily long videos conditioned on a variety of prompts such as text, image or their combinations, making it highly versatile and flexible. To combat the common drifting issue in AR models, we propose masked diffusion model which implicitly learns which information can be drawn from reference images rather than network predictions, in order to reduce the risk of generating inconsistent appearances that cause drifting. Moreover, we further enhance generation coherence by conditioning it on the initial frame, which typically contains minimal noise. This is particularly useful for long video generation. When trained for only two weeks on four GPUs, ART$\boldsymbol{\cdot}$V already can generate videos with natural motions, rich details and a high level of aesthetic quality. Besides, it enables various appealing applications, e.g., composing a long video from multiple text prompts.
Learning Trajectories are Generalization Indicators
May 04, 2023



The aim of this paper is to investigate the connection between learning trajectories of the Deep Neural Networks (DNNs) and their corresponding generalization capabilities when being optimized with broadly used gradient descent and stochastic gradient descent algorithms. In this paper, we construct Linear Approximation Function to model the trajectory information and we propose a new generalization bound with richer trajectory information based on it. Our proposed generalization bound relies on the complexity of learning trajectory and the ratio between the bias and diversity of training set. Experimental results indicate that the proposed method effectively captures the generalization trend across various training steps, learning rates, and label noise levels.