 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenArena: How Can We Achieve Human-Aligned Evaluation for Visual Generation Tasks?
Feb 05, 2026The rapid advancement of visual generation models has outpaced traditional evaluation approaches, necessitating the adoption of Vision-Language Models as surrogate judges. In this work, we systematically investigate the reliability of the prevailing absolute pointwise scoring standard, across a wide spectrum of visual generation tasks. Our analysis reveals that this paradigm is limited due to stochastic inconsistency and poor alignment with human perception. To resolve these limitations, we introduce GenArena, a unified evaluation framework that leverages a pairwise comparison paradigm to ensure stable and human-aligned evaluation. Crucially, our experiments uncover a transformative finding that simply adopting this pairwise protocol enables off-the-shelf open-source models to outperform top-tier proprietary models. Notably, our method boosts evaluation accuracy by over 20% and achieves a Spearman correlation of 0.86 with the authoritative LMArena leaderboard, drastically surpassing the 0.36 correlation of pointwise methods. Based on GenArena, we benchmark state-of-the-art visual generation models across diverse tasks, providing the community with a rigorous and automated evaluation standard for visual generation.
Subject-driven Video Generation via Disentangled Identity and Motion
Apr 23, 2025We propose to train a subject-driven customized video generation model through decoupling the subject-specific learning from temporal dynamics in zero-shot without additional tuning. A traditional method for video customization that is tuning-free often relies on large, annotated video datasets, which are computationally expensive and require extensive annotation. In contrast to the previous approach, we introduce the use of an image customization dataset directly on training video customization models, factorizing the video customization into two folds: (1) identity injection through image customization dataset and (2) temporal modeling preservation with a small set of unannotated videos through the image-to-video training method. Additionally, we employ random image token dropping with randomized image initialization during image-to-video fine-tuning to mitigate the copy-and-paste issue. To further enhance learning, we introduce stochastic switching during joint optimization of subject-specific and temporal features, mitigating catastrophic forgetting. Our method achieves strong subject consistency and scalability, outperforming existing video customization models in zero-shot settings, demonstrating the effectiveness of our framework.
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
Nov 30, 2023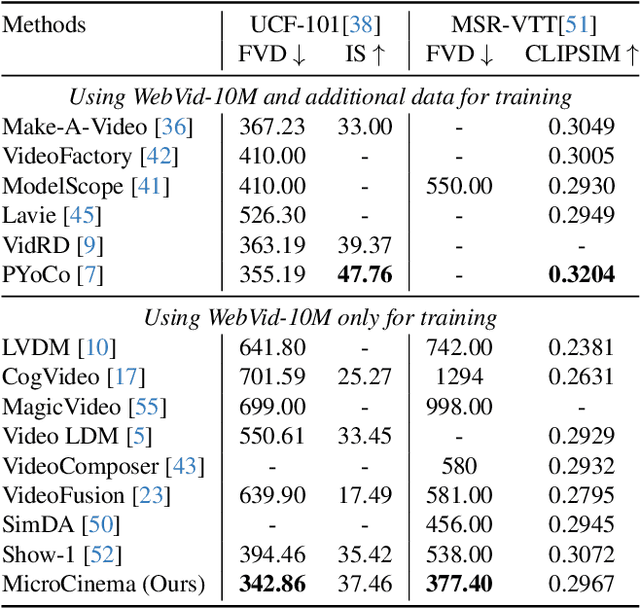
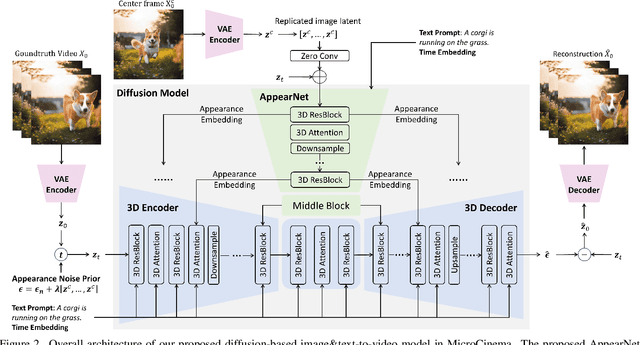
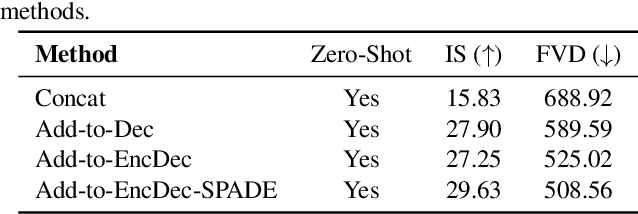
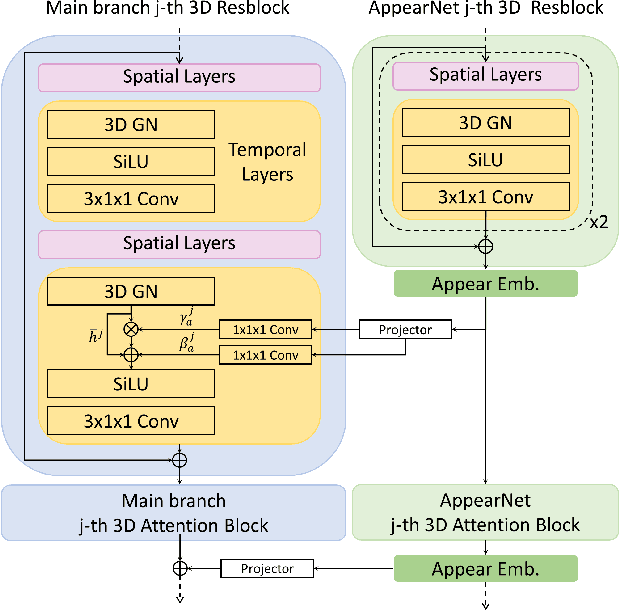
We present MicroCinema, a straightforward yet effective framework for high-quality and coherent text-to-video generation. Unlike existing approaches that align text prompts with video directly, MicroCinema introduces a Divide-and-Conquer strategy which divides the text-to-video into a two-stage process: text-to-image generation and image\&text-to-video generation. This strategy offers two significant advantages. a) It allows us to take full advantage of the recent advances in text-to-image models, such as Stable Diffusion, Midjourney, and DALLE, to generate photorealistic and highly detailed images. b) Leveraging the generated image, the model can allocate less focus to fine-grained appearance details, prioritizing the efficient learning of motion dynamics. To implement this strategy effectively, we introduce two core designs. First, we propose the Appearance Injection Network, enhancing the preservation of the appearance of the given image. Second, we introduce the Appearance Noise Prior, a novel mechanism aimed at maintaining the capabilities of pre-trained 2D diffusion models. These design elements empower MicroCinema to generate high-quality videos with precise motion, guided by the provided text prompts. Extensive experiments demonstrate the superiority of the proposed framework. Concretely, MicroCinema achieves SOTA zero-shot FVD of 342.86 on UCF-101 and 377.40 on MSR-VTT. See https://wangyanhui666.github.io/MicroCinema.github.io/ for video samples.