 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenArena: How Can We Achieve Human-Aligned Evaluation for Visual Generation Tasks?
Feb 05, 2026The rapid advancement of visual generation models has outpaced traditional evaluation approaches, necessitating the adoption of Vision-Language Models as surrogate judges. In this work, we systematically investigate the reliability of the prevailing absolute pointwise scoring standard, across a wide spectrum of visual generation tasks. Our analysis reveals that this paradigm is limited due to stochastic inconsistency and poor alignment with human perception. To resolve these limitations, we introduce GenArena, a unified evaluation framework that leverages a pairwise comparison paradigm to ensure stable and human-aligned evaluation. Crucially, our experiments uncover a transformative finding that simply adopting this pairwise protocol enables off-the-shelf open-source models to outperform top-tier proprietary models. Notably, our method boosts evaluation accuracy by over 20% and achieves a Spearman correlation of 0.86 with the authoritative LMArena leaderboard, drastically surpassing the 0.36 correlation of pointwise methods. Based on GenArena, we benchmark state-of-the-art visual generation models across diverse tasks, providing the community with a rigorous and automated evaluation standard for visual generation.
Distribution Matching Variational AutoEncoder
Dec 08, 2025Most visual generative models compress images into a latent space before applying diffusion or autoregressive modelling. Yet, existing approaches such as VAEs and foundation model aligned encoders implicitly constrain the latent space without explicitly shaping its distribution, making it unclear which types of distributions are optimal for modeling. We introduce \textbf{Distribution-Matching VAE} (\textbf{DMVAE}), which explicitly aligns the encoder's latent distribution with an arbitrary reference distribution via a distribution matching constraint. This generalizes beyond the Gaussian prior of conventional VAEs, enabling alignment with distributions derived from self-supervised features, diffusion noise, or other prior distributions. With DMVAE, we can systematically investigate which latent distributions are more conducive to modeling, and we find that SSL-derived distributions provide an excellent balance between reconstruction fidelity and modeling efficiency, reaching gFID equals 3.2 on ImageNet with only 64 training epochs. Our results suggest that choosing a suitable latent distribution structure (achieved via distribution-level alignment), rather than relying on fixed priors, is key to bridging the gap between easy-to-model latents and high-fidelity image synthesis. Code is avaliable at https://github.com/sen-ye/dmvae.
Equivariant Image Modeling
Mar 24, 2025Current generative models, such as autoregressive and diffusion approaches, decompose high-dimensional data distribution learning into a series of simpler subtasks. However, inherent conflicts arise during the joint optimization of these subtasks, and existing solutions fail to resolve such conflicts without sacrificing efficiency or scalability. We propose a novel equivariant image modeling framework that inherently aligns optimization targets across subtasks by leveraging the translation invariance of natural visual signals. Our method introduces (1) column-wise tokenization which enhances translational symmetry along the horizontal axis, and (2) windowed causal attention which enforces consistent contextual relationships across positions. Evaluated on class-conditioned ImageNet generation at 256x256 resolution, our approach achieves performance comparable to state-of-the-art AR models while using fewer computational resources. Systematic analysis demonstrates that enhanced equivariance reduces inter-task conflicts, significantly improving zero-shot generalization and enabling ultra-long image synthesis. This work establishes the first framework for task-aligned decomposition in generative modeling, offering insights into efficient parameter sharing and conflict-free optimization. The code and models are publicly available at https://github.com/drx-code/EquivariantModeling.
Tokenize Image as a Set
Mar 20, 2025This paper proposes a fundamentally new paradigm for image generation through set-based tokenization and distribution modeling. Unlike conventional methods that serialize images into fixed-position latent codes with a uniform compression ratio, we introduce an unordered token set representation to dynamically allocate coding capacity based on regional semantic complexity. This TokenSet enhances global context aggregation and improves robustness against local perturbations. To address the critical challenge of modeling discrete sets, we devise a dual transformation mechanism that bijectively converts sets into fixed-length integer sequences with summation constraints. Further, we propose Fixed-Sum Discrete Diffusion--the first framework to simultaneously handle discrete values, fixed sequence length, and summation invariance--enabling effective set distribution modeling. Experiments demonstrate our method's superiority in semantic-aware representation and generation quality. Our innovations, spanning novel representation and modeling strategies, advance visual generation beyond traditional sequential token paradigms. Our code and models are publicly available at https://github.com/Gengzigang/TokenSet.
Side Adapter Network for Open-Vocabulary Semantic Segmentation
Feb 23, 2023


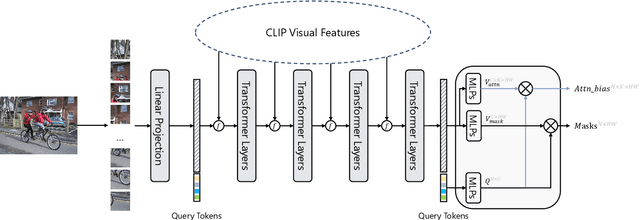
This paper presents a new framework for open-vocabulary semantic segmentation with the pre-trained vision-language model, named Side Adapter Network (SAN). Our approach models the semantic segmentation task as a region recognition problem. A side network is attached to a frozen CLIP model with two branches: one for predicting mask proposals, and the other for predicting attention bias which is applied in the CLIP model to recognize the class of masks. This decoupled design has the benefit CLIP in recognizing the class of mask proposals. Since the attached side network can reuse CLIP features, it can be very light. In addition, the entire network can be trained end-to-end, allowing the side network to be adapted to the frozen CLIP model, which makes the predicted mask proposals CLIP-aware. Our approach is fast, accurate, and only adds a few additional trainable parameters. We evaluate our approach on multiple semantic segmentation benchmarks. Our method significantly outperforms other counterparts, with up to 18 times fewer trainable parameters and 19 times faster inference speed. We hope our approach will serve as a solid baseline and help ease future research in open-vocabulary semantic segmentation. The code will be available at https://github.com/MendelXu/SAN.
A Simple Baseline for Zero-shot Semantic Segmentation with Pre-trained Vision-language Model
Dec 29, 2021
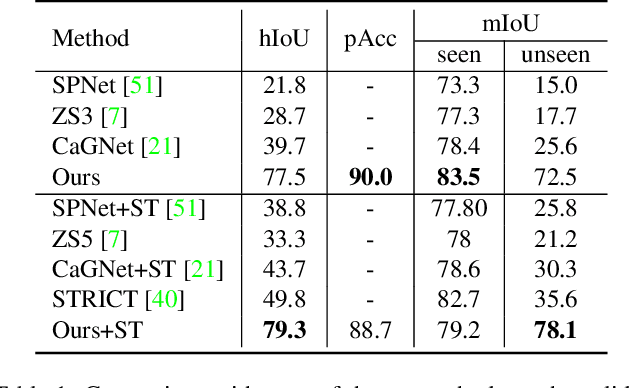

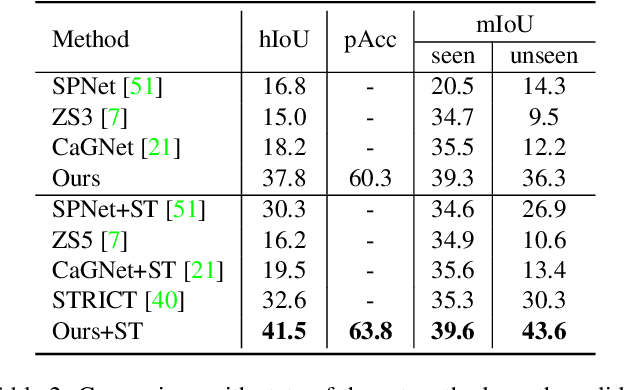
Recently, zero-shot image classification by vision-language pre-training has demonstrated incredible achievements, that the model can classify arbitrary category without seeing additional annotated images of that category. However, it is still unclear how to make the zero-shot recognition working well on broader vision problems, such as object detection and semantic segmentation. In this paper, we target for zero-shot semantic segmentation, by building it on an off-the-shelf pre-trained vision-language model, i.e., CLIP. It is difficult because semantic segmentation and the CLIP model perform on different visual granularity, that semantic segmentation processes on pixels while CLIP performs on images. To remedy the discrepancy on processing granularity, we refuse the use of the prevalent one-stage FCN based framework, and advocate a two-stage semantic segmentation framework, with the first stage extracting generalizable mask proposals and the second stage leveraging an image based CLIP model to perform zero-shot classification on the masked image crops which are generated in the first stage. Our experimental results show that this simple framework surpasses previous state-of-the-arts by a large margin: +29.5 hIoU on the Pascal VOC 2012 dataset, and +8.9 hIoU on the COCO Stuff dataset. With its simplicity and strong performance, we hope this framework to serve as a baseline to facilitate the future research.
Bootstrap Your Object Detector via Mixed Training
Nov 04, 2021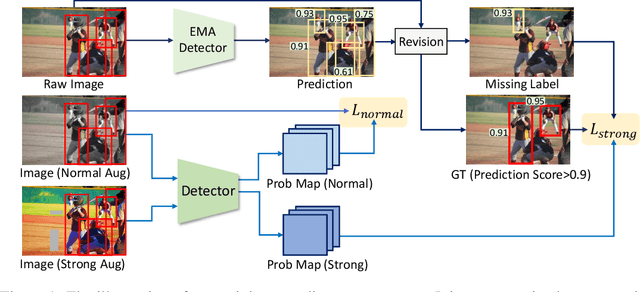


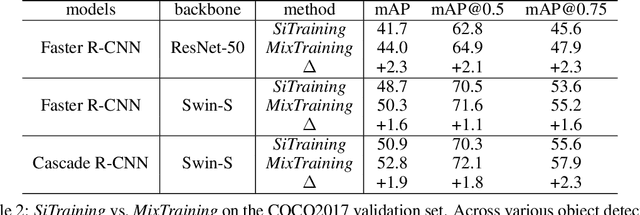
We introduce MixTraining, a new training paradigm for object detection that can improve the performance of existing detectors for free. MixTraining enhances data augmentation by utilizing augmentations of different strengths while excluding the strong augmentations of certain training samples that may be detrimental to training. In addition, it addresses localization noise and missing labels in human annotations by incorporating pseudo boxes that can compensate for these errors. Both of these MixTraining capabilities are made possible through bootstrapping on the detector, which can be used to predict the difficulty of training on a strong augmentation, as well as to generate reliable pseudo boxes thanks to the robustness of neural networks to labeling error. MixTraining is found to bring consistent improvements across various detectors on the COCO dataset. In particular, the performance of Faster R-CNN \cite{ren2015faster} with a ResNet-50 \cite{he2016deep} backbone is improved from 41.7 mAP to 44.0 mAP, and the accuracy of Cascade-RCNN \cite{cai2018cascade} with a Swin-Small \cite{liu2021swin} backbone is raised from 50.9 mAP to 52.8 mAP. The code and models will be made publicly available at \url{https://github.com/MendelXu/MixTraining}.
End-to-End Semi-Supervised Object Detection with Soft Teacher
Jun 17, 2021
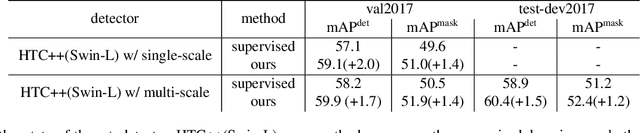


This paper presents an end-to-end semi-supervised object detection approach, in contrast to previous more complex multi-stage methods. The end-to-end training gradually improves pseudo label qualities during the curriculum, and the more and more accurate pseudo labels in turn benefit object detection training. We also propose two simple yet effective techniques within this framework: a soft teacher mechanism where the classification loss of each unlabeled bounding box is weighed by the classification score produced by the teacher network; a box jittering approach to select reliable pseudo boxes for the learning of box regression. On COCO benchmark, the proposed approach outperforms previous methods by a large margin under various labeling ratios, i.e. 1\%, 5\% and 10\%. Moreover, our approach proves to perform also well when the amount of labeled data is relatively large. For example, it can improve a 40.9 mAP baseline detector trained using the full COCO training set by +3.6 mAP, reaching 44.5 mAP, by leveraging the 123K unlabeled images of COCO. On the state-of-the-art Swin Transformer-based object detector (58.9 mAP on test-dev), it can still significantly improve the detection accuracy by +1.5 mAP, reaching 60.4 mAP, and improve the instance segmentation accuracy by +1.2 mAP, reaching 52.4 mAP, pushing the new state-of-the-art.
Progressive and Aligned Pose Attention Transfer for Person Image Generation
Mar 22, 2021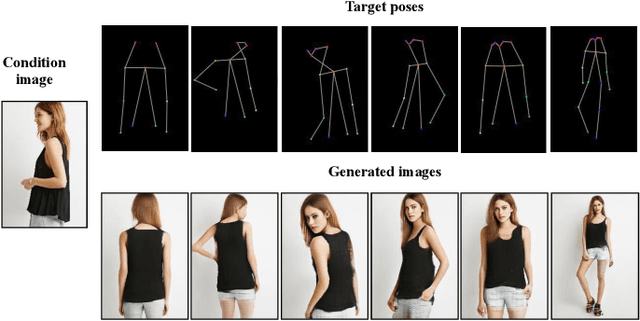
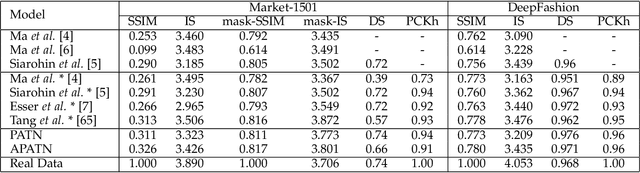
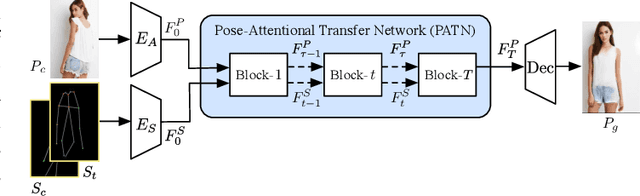
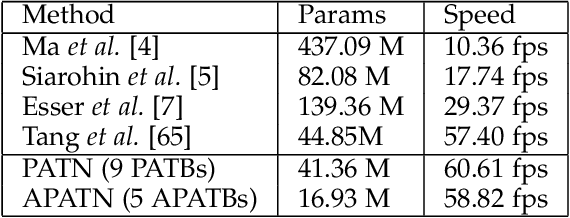
This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. We design a progressive generator which comprises a sequence of transfer blocks. Each block performs an intermediate transfer step by modeling the relationship between the condition and the target poses with attention mechanism. Two types of blocks are introduced, namely Pose-Attentional Transfer Block (PATB) and Aligned Pose-Attentional Transfer Bloc ~(APATB). Compared with previous works, our model generates more photorealistic person images that retain better appearance consistency and shape consistency compared with input images. We verify the efficacy of the model on the Market-1501 and DeepFashion datasets, using quantitative and qualitative measures. Furthermore, we show that our method can be used for data augmentation for the person re-identification task, alleviating the issue of data insufficiency. Code and pretrained models are available at https://github.com/tengteng95/Pose-Transfer.git.
Asymmetric Non-local Neural Networks for Semantic Segmentation
Aug 29, 2019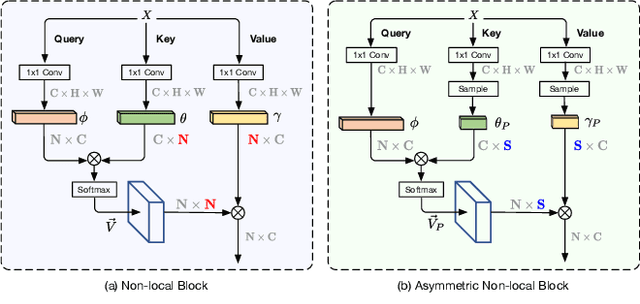
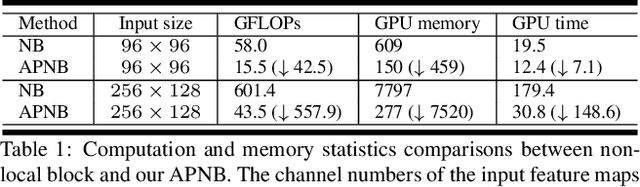
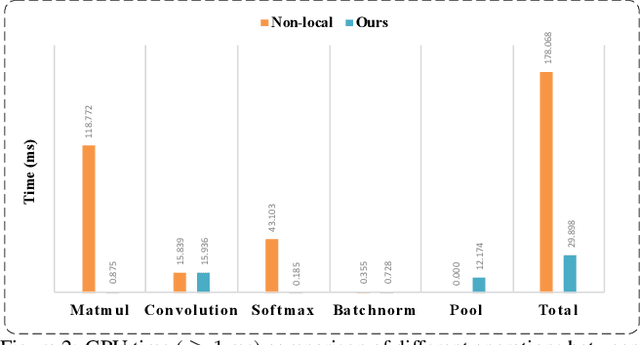
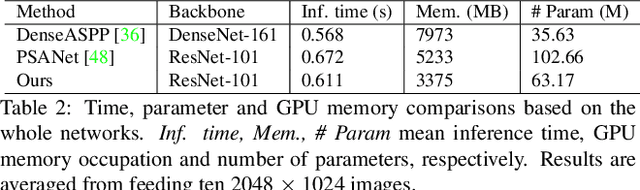
The non-local module works as a particularly useful technique for semantic segmentation while criticized for its prohibitive computation and GPU memory occupation. In this paper, we present Asymmetric Non-local Neural Network to semantic segmentation, which has two prominent components: Asymmetric Pyramid Non-local Block (APNB) and Asymmetric Fusion Non-local Block (AFNB). APNB leverages a pyramid sampling module into the non-local block to largely reduce the computation and memory consumption without sacrificing the performance. AFNB is adapted from APNB to fuse the features of different levels under a sufficient consideration of long range dependencies and thus considerably improves the performance. Extensive experiments on semantic segmentation benchmarks demonstrate the effectiveness and efficiency of our work. In particular, we report the state-of-the-art performance of 81.3 mIoU on the Cityscapes test set. For a 256x128 input, APNB is around 6 times faster than a non-local block on GPU while 28 times smaller in GPU running memory occupation. Code is available at: https://github.com/MendelXu/ANN.git.