 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline for Zero-shot Semantic Segmentation with Pre-trained Vision-language Model
Paper and Code

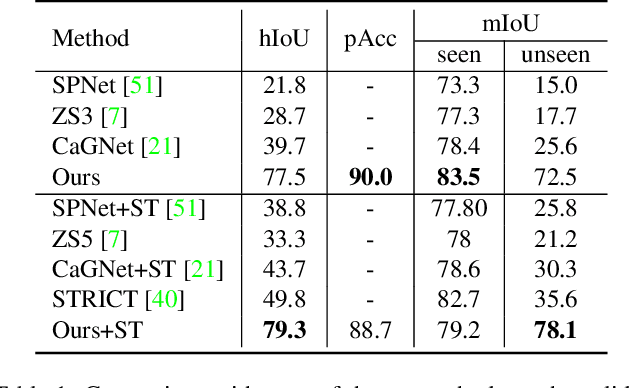

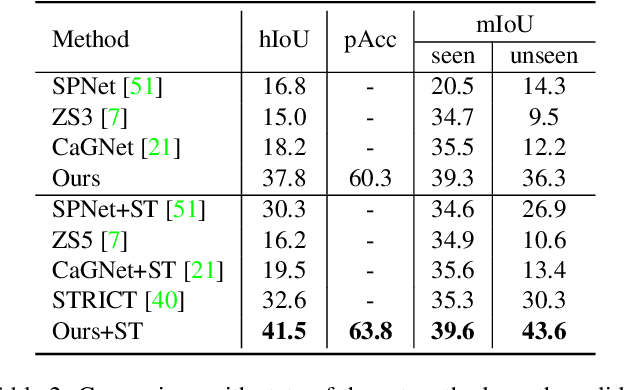
Recently, zero-shot image classification by vision-language pre-training has demonstrated incredible achievements, that the model can classify arbitrary category without seeing additional annotated images of that category. However, it is still unclear how to make the zero-shot recognition working well on broader vision problems, such as object detection and semantic segmentation. In this paper, we target for zero-shot semantic segmentation, by building it on an off-the-shelf pre-trained vision-language model, i.e., CLIP. It is difficult because semantic segmentation and the CLIP model perform on different visual granularity, that semantic segmentation processes on pixels while CLIP performs on images. To remedy the discrepancy on processing granularity, we refuse the use of the prevalent one-stage FCN based framework, and advocate a two-stage semantic segmentation framework, with the first stage extracting generalizable mask proposals and the second stage leveraging an image based CLIP model to perform zero-shot classification on the masked image crops which are generated in the first stage. Our experimental results show that this simple framework surpasses previous state-of-the-arts by a large margin: +29.5 hIoU on the Pascal VOC 2012 dataset, and +8.9 hIoU on the COCO Stuff dataset. With its simplicity and strong performance, we hope this framework to serve as a baseline to facilitate the future research.