 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAMap: Distance-aware MapNet for High Quality HD Map Construction
Oct 26, 2025Predicting High-definition (HD) map elements with high quality (high classification and localization scores) is crucial to the safety of autonomous driving vehicles. However, current methods perform poorly in high quality predictions due to inherent task misalignment. Two main factors are responsible for misalignment: 1) inappropriate task labels due to one-to-many matching queries sharing the same labels, and 2) sub-optimal task features due to task-shared sampling mechanism. In this paper, we reveal two inherent defects in current methods and develop a novel HD map construction method named DAMap to address these problems. Specifically, DAMap consists of three components: Distance-aware Focal Loss (DAFL), Hybrid Loss Scheme (HLS), and Task Modulated Deformable Attention (TMDA). The DAFL is introduced to assign appropriate classification labels for one-to-many matching samples. The TMDA is proposed to obtain discriminative task-specific features. Furthermore, the HLS is proposed to better utilize the advantages of the DAFL. We perform extensive experiments and consistently achieve performance improvement on the NuScenes and Argoverse2 benchmarks under different metrics, baselines, splits, backbones, and schedules. Code will be available at https://github.com/jpdong-xjtu/DAMap.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025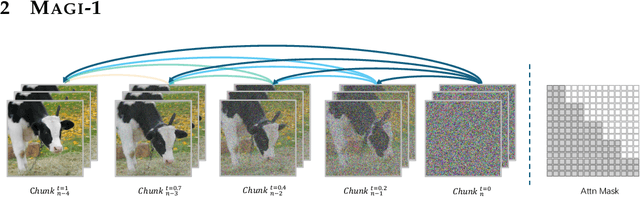
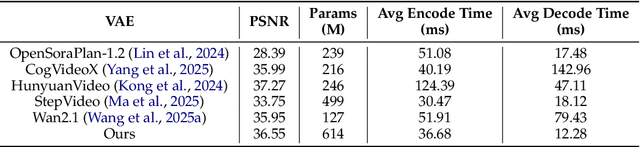
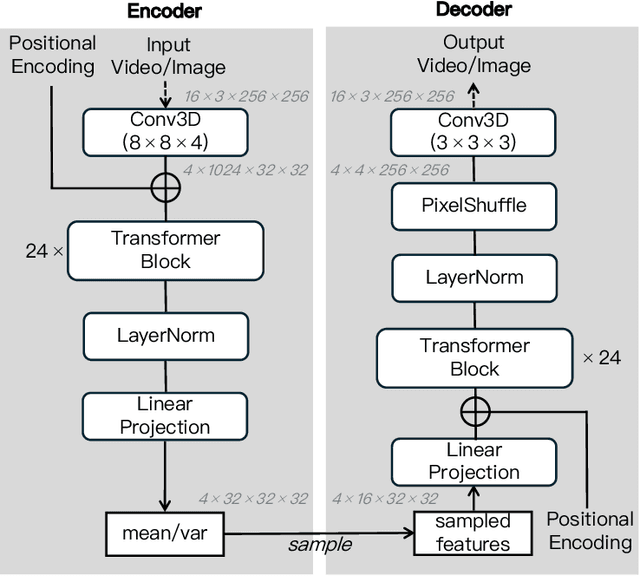
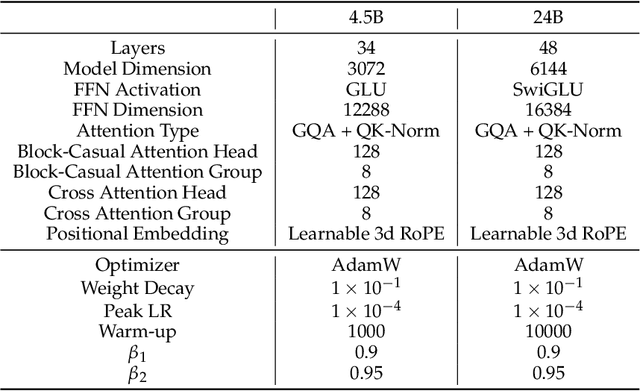
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
Efficient and Economic Large Language Model Inference with Attention Offloading
May 03, 2024
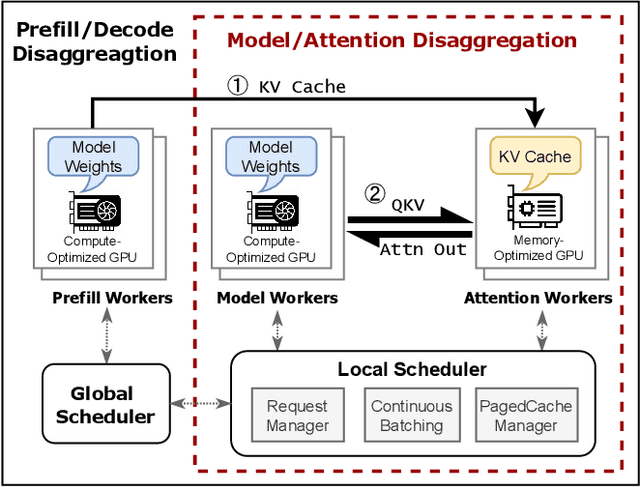


Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
V-DETR: DETR with Vertex Relative Position Encoding for 3D Object Detection
Aug 08, 2023



We introduce a highly performant 3D object detector for point clouds using the DETR framework. The prior attempts all end up with suboptimal results because they fail to learn accurate inductive biases from the limited scale of training data. In particular, the queries often attend to points that are far away from the target objects, violating the locality principle in object detection. To address the limitation, we introduce a novel 3D Vertex Relative Position Encoding (3DV-RPE) method which computes position encoding for each point based on its relative position to the 3D boxes predicted by the queries in each decoder layer, thus providing clear information to guide the model to focus on points near the objects, in accordance with the principle of locality. In addition, we systematically improve the pipeline from various aspects such as data normalization based on our understanding of the task. We show exceptional results on the challenging ScanNetV2 benchmark, achieving significant improvements over the previous 3DETR in $\rm{AP}_{25}$/$\rm{AP}_{50}$ from 65.0\%/47.0\% to 77.8\%/66.0\%, respectively. In addition, our method sets a new record on ScanNetV2 and SUN RGB-D datasets.Code will be released at http://github.com/yichaoshen-MS/V-DETR.
DETR Doesn't Need Multi-Scale or Locality Design
Aug 03, 2023This paper presents an improved DETR detector that maintains a "plain" nature: using a single-scale feature map and global cross-attention calculations without specific locality constraints, in contrast to previous leading DETR-based detectors that reintroduce architectural inductive biases of multi-scale and locality into the decoder. We show that two simple technologies are surprisingly effective within a plain design to compensate for the lack of multi-scale feature maps and locality constraints. The first is a box-to-pixel relative position bias (BoxRPB) term added to the cross-attention formulation, which well guides each query to attend to the corresponding object region while also providing encoding flexibility. The second is masked image modeling (MIM)-based backbone pre-training which helps learn representation with fine-grained localization ability and proves crucial for remedying dependencies on the multi-scale feature maps. By incorporating these technologies and recent advancements in training and problem formation, the improved "plain" DETR showed exceptional improvements over the original DETR detector. By leveraging the Object365 dataset for pre-training, it achieved 63.9 mAP accuracy using a Swin-L backbone, which is highly competitive with state-of-the-art detectors which all heavily rely on multi-scale feature maps and region-based feature extraction. Code is available at https://github.com/impiga/Plain-DETR .
Could Giant Pretrained Image Models Extract Universal Representations?
Nov 03, 2022



Frozen pretrained models have become a viable alternative to the pretraining-then-finetuning paradigm for transfer learning. However, with frozen models there are relatively few parameters available for adapting to downstream tasks, which is problematic in computer vision where tasks vary significantly in input/output format and the type of information that is of value. In this paper, we present a study of frozen pretrained models when applied to diverse and representative computer vision tasks, including object detection, semantic segmentation and video action recognition. From this empirical analysis, our work answers the questions of what pretraining task fits best with this frozen setting, how to make the frozen setting more flexible to various downstream tasks, and the effect of larger model sizes. We additionally examine the upper bound of performance using a giant frozen pretrained model with 3 billion parameters (SwinV2-G) and find that it reaches competitive performance on a varied set of major benchmarks with only one shared frozen base network: 60.0 box mAP and 52.2 mask mAP on COCO object detection test-dev, 57.6 val mIoU on ADE20K semantic segmentation, and 81.7 top-1 accuracy on Kinetics-400 action recognition. With this work, we hope to bring greater attention to this promising path of freezing pretrained image models.
On Data Scaling in Masked Image Modeling
Jun 09, 2022



An important goal of self-supervised learning is to enable model pre-training to benefit from almost unlimited data. However, one method that has recently become popular, namely masked image modeling (MIM), is suspected to be unable to benefit from larger data. In this work, we break this misconception through extensive experiments, with data scales ranging from 10\% of ImageNet-1K to full ImageNet-22K, model sizes ranging from 49 million to 1 billion, and training lengths ranging from 125K iterations to 500K iterations. Our study reveals that: (i) Masked image modeling is also demanding on larger data. We observed that very large models got over-fitted with relatively small data; (ii) The length of training matters. Large models trained with masked image modeling can benefit from more data with longer training; (iii) The validation loss in pre-training is a good indicator to measure how well the model performs for fine-tuning on multiple tasks. This observation allows us to pre-evaluate pre-trained models in advance without having to make costly trial-and-error assessments of downstream tasks. We hope that our findings will advance the understanding of masked image modeling in terms of scaling ability.
A Simple Baseline for Zero-shot Semantic Segmentation with Pre-trained Vision-language Model
Dec 29, 2021
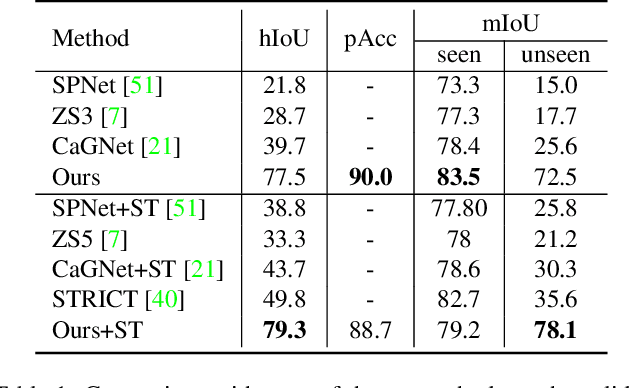

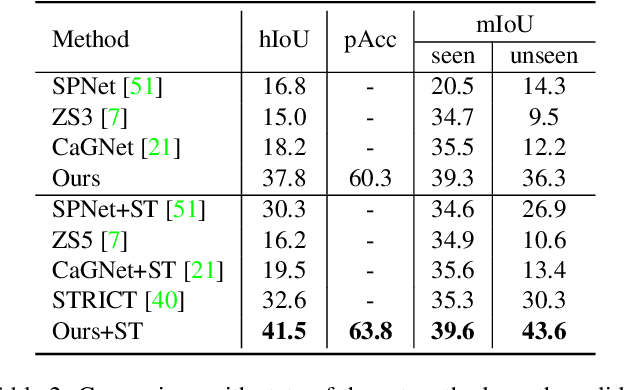
Recently, zero-shot image classification by vision-language pre-training has demonstrated incredible achievements, that the model can classify arbitrary category without seeing additional annotated images of that category. However, it is still unclear how to make the zero-shot recognition working well on broader vision problems, such as object detection and semantic segmentation. In this paper, we target for zero-shot semantic segmentation, by building it on an off-the-shelf pre-trained vision-language model, i.e., CLIP. It is difficult because semantic segmentation and the CLIP model perform on different visual granularity, that semantic segmentation processes on pixels while CLIP performs on images. To remedy the discrepancy on processing granularity, we refuse the use of the prevalent one-stage FCN based framework, and advocate a two-stage semantic segmentation framework, with the first stage extracting generalizable mask proposals and the second stage leveraging an image based CLIP model to perform zero-shot classification on the masked image crops which are generated in the first stage. Our experimental results show that this simple framework surpasses previous state-of-the-arts by a large margin: +29.5 hIoU on the Pascal VOC 2012 dataset, and +8.9 hIoU on the COCO Stuff dataset. With its simplicity and strong performance, we hope this framework to serve as a baseline to facilitate the future research.
SimMIM: A Simple Framework for Masked Image Modeling
Nov 18, 2021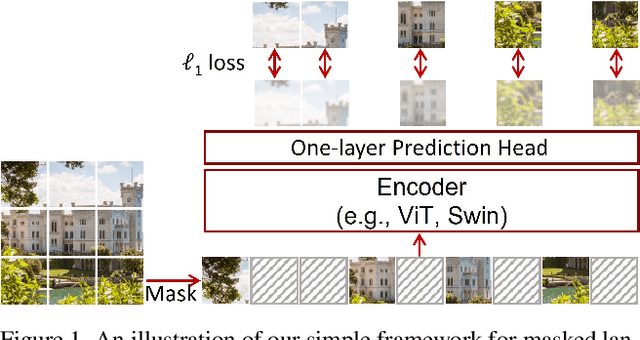
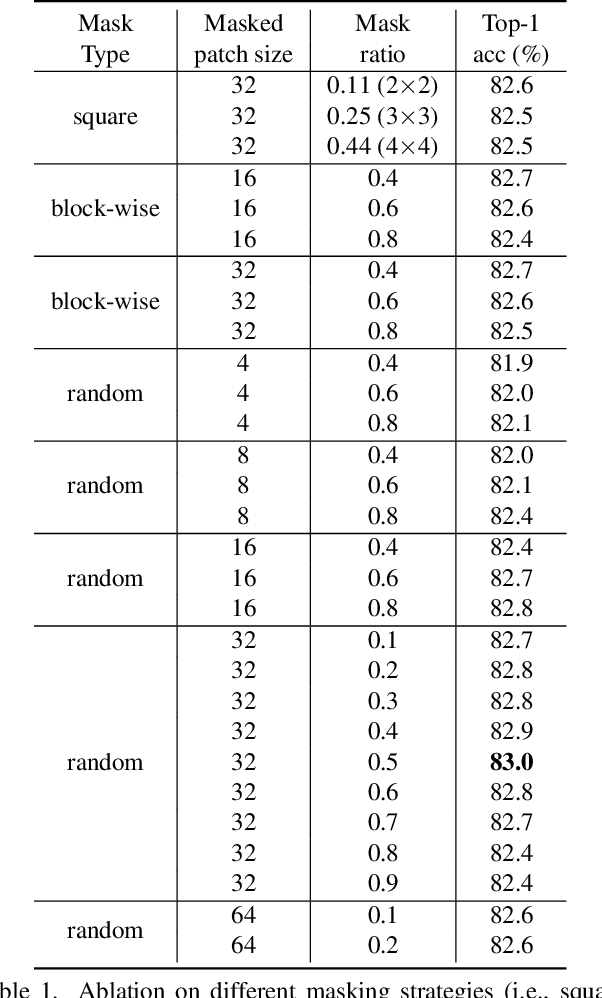

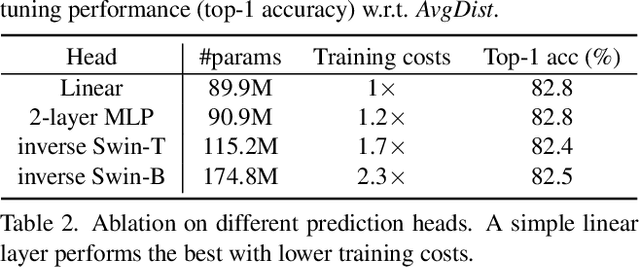
This paper presents SimMIM, a simple framework for masked image modeling. We simplify recently proposed related approaches without special designs such as block-wise masking and tokenization via discrete VAE or clustering. To study what let the masked image modeling task learn good representations, we systematically study the major components in our framework, and find that simple designs of each component have revealed very strong representation learning performance: 1) random masking of the input image with a moderately large masked patch size (e.g., 32) makes a strong pre-text task; 2) predicting raw pixels of RGB values by direct regression performs no worse than the patch classification approaches with complex designs; 3) the prediction head can be as light as a linear layer, with no worse performance than heavier ones. Using ViT-B, our approach achieves 83.8% top-1 fine-tuning accuracy on ImageNet-1K by pre-training also on this dataset, surpassing previous best approach by +0.6%. When applied on a larger model of about 650 million parameters, SwinV2-H, it achieves 87.1% top-1 accuracy on ImageNet-1K using only ImageNet-1K data. We also leverage this approach to facilitate the training of a 3B model (SwinV2-G), that by $40\times$ less data than that in previous practice, we achieve the state-of-the-art on four representative vision benchmarks. The code and models will be publicly available at https://github.com/microsoft/SimMIM.
Swin Transformer V2: Scaling Up Capacity and Resolution
Nov 18, 2021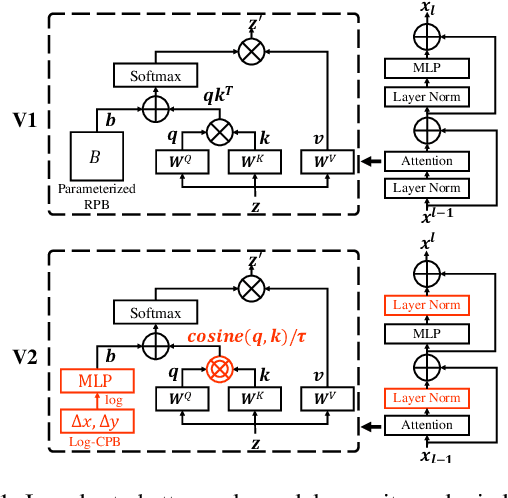
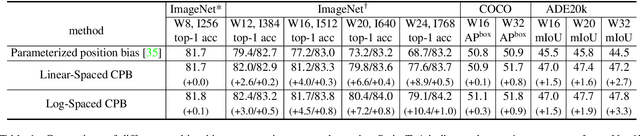
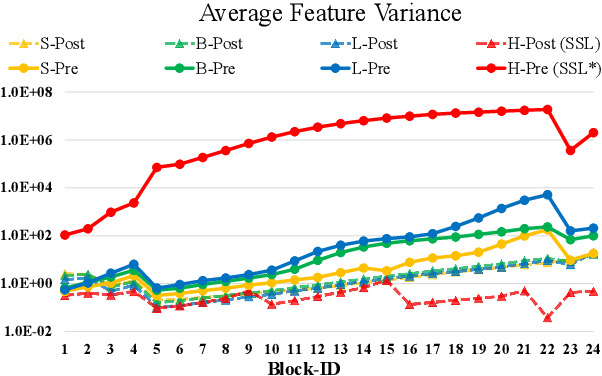
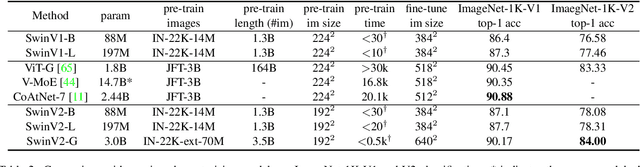
We present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536$\times$1,536 resolution. By scaling up capacity and resolution, Swin Transformer sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1/54.4 box/mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification. Our techniques are generally applicable for scaling up vision models, which has not been widely explored as that of NLP language models, partly due to the following difficulties in training and applications: 1) vision models often face instability issues at scale and 2) many downstream vision tasks require high resolution images or windows and it is not clear how to effectively transfer models pre-trained at low resolutions to higher resolution ones. The GPU memory consumption is also a problem when the image resolution is high. To address these issues, we present several techniques, which are illustrated by using Swin Transformer as a case study: 1) a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models; 2) a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts. In addition, we share our crucial implementation details that lead to significant savings of GPU memory consumption and thus make it feasible to train large vision models with regular GPUs. Using these techniques and self-supervised pre-training, we successfully train a strong 3B Swin Transformer model and effectively transfer it to various vision tasks involving high-resolution images or windows, achieving the state-of-the-art accuracy on a variety of benchmarks.