 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBCN: Batch Channel Normalization for Image Classification
Dec 01, 2023Normalization techniques have been widely used in the field of deep learning due to their capability of enabling higher learning rates and are less careful in initialization. However, the effectiveness of popular normalization technologies is typically limited to specific areas. Unlike the standard Batch Normalization (BN) and Layer Normalization (LN), where BN computes the mean and variance along the (N,H,W) dimensions and LN computes the mean and variance along the (C,H,W) dimensions (N, C, H and W are the batch, channel, spatial height and width dimension, respectively), this paper presents a novel normalization technique called Batch Channel Normalization (BCN). To exploit both the channel and batch dependence and adaptively and combine the advantages of BN and LN based on specific datasets or tasks, BCN separately normalizes inputs along the (N, H, W) and (C, H, W) axes, then combines the normalized outputs based on adaptive parameters. As a basic block, BCN can be easily integrated into existing models for various applications in the field of computer vision. Empirical results show that the proposed technique can be seamlessly applied to various versions of CNN or Vision Transformer architecture. The code is publicly available at https://github.com/AfifaKhaled/BatchChannel-Normalization
FP8-LM: Training FP8 Large Language Models
Oct 27, 2023



In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters. Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner. Experiment results show that, during the training of GPT-175B model on H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%. This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses. Our FP8 low-precision training framework is open-sourced at {https://github.com/Azure/MS-AMP}{aka.ms/MS.AMP}.
Gaussian Mask Convolution for Convolutional Neural Networks
Feb 09, 2023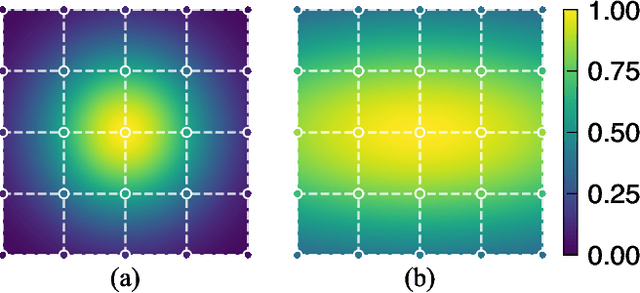



Square convolution is a default unit in convolutional neural networks as it fits well on the tensor computation for convolution operation, which usually has a fixed N x N receptive field (RF). However, what matters most to the network is the effective receptive field (ERF), which indicates the extent each pixel contributes to the output. ERF shows a Gaussian distribution and can not be modeled by simply sampling pixels with offsets. To simulate ERF, we propose a Gaussian Mask convolutional kernel (GMConv) in this work. Specifically, GMConv utilizes the Gaussian function to generate a concentric symmetry mask and put the mask over the kernel to refine the RF. Our GMConv can directly replace the standard convolutions in existing CNNs and can be easily trained end-to-end by standard backpropagation. Extensive experiments on multiple image classification benchmark datasets show that our method is comparable to, and outperforms in many cases, the standard convolution. For instance, using GMConv for AlexNet and ResNet-50, the top-1 accuracy on ImageNet classification is boosted by 0.98% and 0.85%, respectively.
All in Tokens: Unifying Output Space of Visual Tasks via Soft Token
Jan 05, 2023



Unlike language tasks, where the output space is usually limited to a set of tokens, the output space of visual tasks is more complicated, making it difficult to build a unified visual model for various visual tasks. In this paper, we seek to unify the output space of visual tasks, so that we can also build a unified model for visual tasks. To this end, we demonstrate a single unified model that simultaneously handles two typical visual tasks of instance segmentation and depth estimation, which have discrete/fixed-length and continuous/varied-length outputs, respectively. We propose several new techniques that take into account the particularity of visual tasks: 1) Soft token. We employ soft token to represent the task output. Unlike hard tokens in the common VQ-VAE which are assigned one-hot to discrete codebooks/vocabularies, the soft token is assigned softly to the codebook embeddings. Soft token can improve the accuracy of both the next token inference and decoding of the task output; 2) Mask augmentation. Many visual tasks have corruption, undefined or invalid values in label annotations, i.e., occluded area of depth maps. We show that a mask augmentation technique can greatly benefit these tasks. With these new techniques and other designs, we show that the proposed general-purpose task-solver can perform both instance segmentation and depth estimation well. Particularly, we achieve 0.279 RMSE on the specific task of NYUv2 depth estimation, setting a new record on this benchmark. The general-purpose task-solver, dubbed AiT, is available at \url{https://github.com/SwinTransformer/AiT}.
Enhancing the Robustness, Efficiency, and Diversity of Differentiable Architecture Search
Apr 10, 2022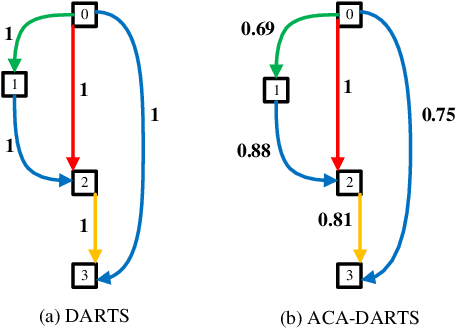
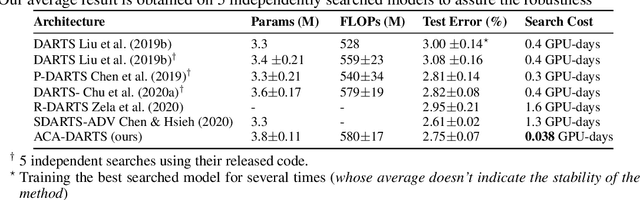
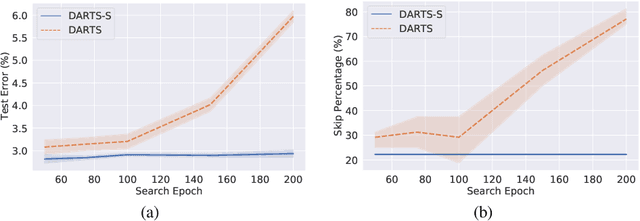
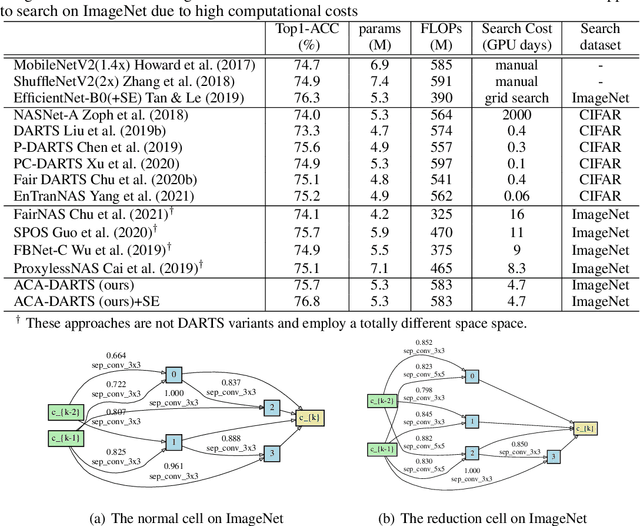
Differentiable architecture search (DARTS) has attracted much attention due to its simplicity and significant improvement in efficiency. However, the excessive accumulation of the skip connection makes it suffer from long-term weak stability and low robustness. Many works attempt to restrict the accumulation of skip connections by indicators or manual design, however, these methods are susceptible to thresholds and human priors. In this work, we suggest a more subtle and direct approach that removes skip connections from the operation space. Then, by introducing an adaptive channel allocation strategy, we redesign the DARTS framework to automatically refill the skip connections in the evaluation stage, resolving the performance degradation caused by the absence of skip connections. Our method, dubbed Adaptive-Channel-Allocation-DARTS (ACA-DRATS), could eliminate the inconsistency in operation strength and significantly expand the architecture diversity. We continue to explore smaller search space under our framework, and offer a direct search on the entire ImageNet dataset. Experiments show that ACA-DRATS improves the search stability and significantly speeds up DARTS by more than ten times while yielding higher accuracy.
Swin Transformer V2: Scaling Up Capacity and Resolution
Nov 18, 2021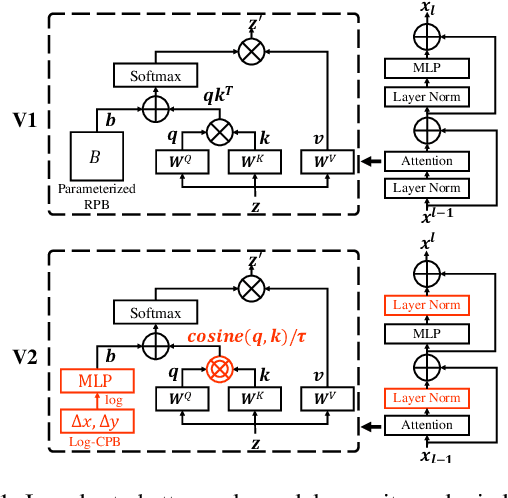
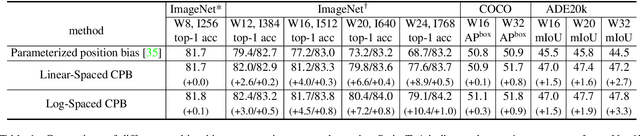
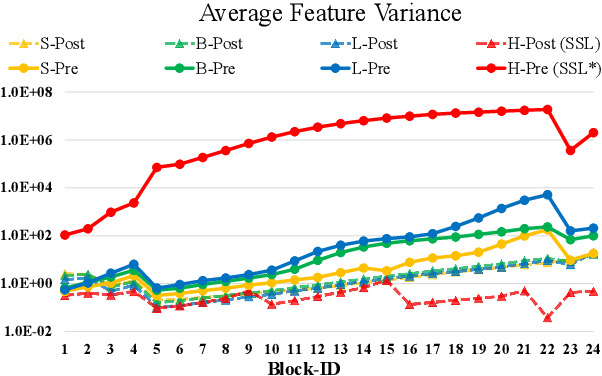
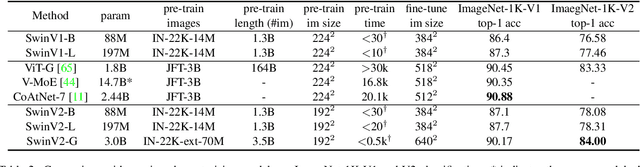
We present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536$\times$1,536 resolution. By scaling up capacity and resolution, Swin Transformer sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1/54.4 box/mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification. Our techniques are generally applicable for scaling up vision models, which has not been widely explored as that of NLP language models, partly due to the following difficulties in training and applications: 1) vision models often face instability issues at scale and 2) many downstream vision tasks require high resolution images or windows and it is not clear how to effectively transfer models pre-trained at low resolutions to higher resolution ones. The GPU memory consumption is also a problem when the image resolution is high. To address these issues, we present several techniques, which are illustrated by using Swin Transformer as a case study: 1) a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models; 2) a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts. In addition, we share our crucial implementation details that lead to significant savings of GPU memory consumption and thus make it feasible to train large vision models with regular GPUs. Using these techniques and self-supervised pre-training, we successfully train a strong 3B Swin Transformer model and effectively transfer it to various vision tasks involving high-resolution images or windows, achieving the state-of-the-art accuracy on a variety of benchmarks.
Video Swin Transformer
Jun 24, 2021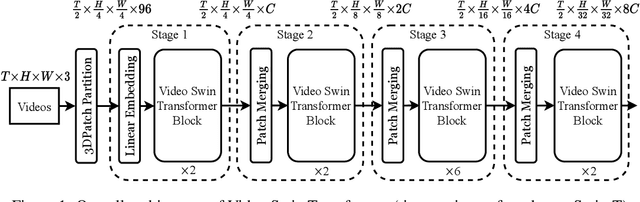

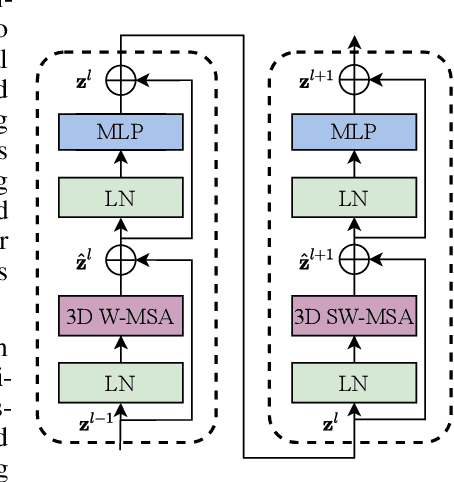
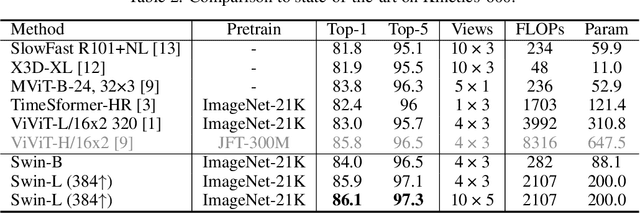
The vision community is witnessing a modeling shift from CNNs to Transformers, where pure Transformer architectures have attained top accuracy on the major video recognition benchmarks. These video models are all built on Transformer layers that globally connect patches across the spatial and temporal dimensions. In this paper, we instead advocate an inductive bias of locality in video Transformers, which leads to a better speed-accuracy trade-off compared to previous approaches which compute self-attention globally even with spatial-temporal factorization. The locality of the proposed video architecture is realized by adapting the Swin Transformer designed for the image domain, while continuing to leverage the power of pre-trained image models. Our approach achieves state-of-the-art accuracy on a broad range of video recognition benchmarks, including on action recognition (84.9 top-1 accuracy on Kinetics-400 and 86.1 top-1 accuracy on Kinetics-600 with ~20x less pre-training data and ~3x smaller model size) and temporal modeling (69.6 top-1 accuracy on Something-Something v2). The code and models will be made publicly available at https://github.com/SwinTransformer/Video-Swin-Transformer.