 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiCAR: Bridging Image Classification and Image-text Alignment for Visual Recognition
Apr 22, 2022

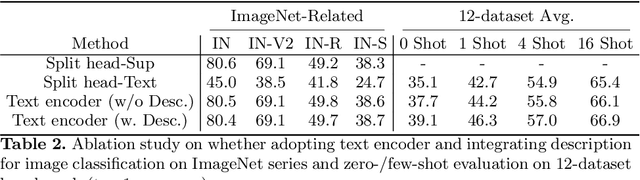

Image classification, which classifies images by pre-defined categories, has been the dominant approach to visual representation learning over the last decade. Visual learning through image-text alignment, however, has emerged to show promising performance, especially for zero-shot recognition. We believe that these two learning tasks are complementary, and suggest combining them for better visual learning. We propose a deep fusion method with three adaptations that effectively bridge two learning tasks, rather than shallow fusion through naive multi-task learning. First, we modify the previous common practice in image classification, a linear classifier, with a cosine classifier which shows comparable performance. Second, we convert the image classification problem from learning parametric category classifier weights to learning a text encoder as a meta network to generate category classifier weights. The learnt text encoder is shared between image classification and image-text alignment. Third, we enrich each class name with a description to avoid confusion between classes and make the classification method closer to the image-text alignment. We prove that this deep fusion approach performs better on a variety of visual recognition tasks and setups than the individual learning or shallow fusion approach, from zero-shot/few-shot image classification, such as the Kornblith 12-dataset benchmark, to downstream tasks of action recognition, semantic segmentation, and object detection in fine-tuning and open-vocabulary settings. The code will be available at https://github.com/weiyx16/iCAR.
SimMIM: A Simple Framework for Masked Image Modeling
Nov 18, 2021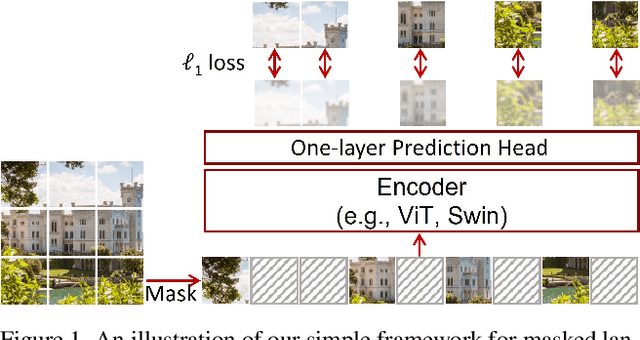
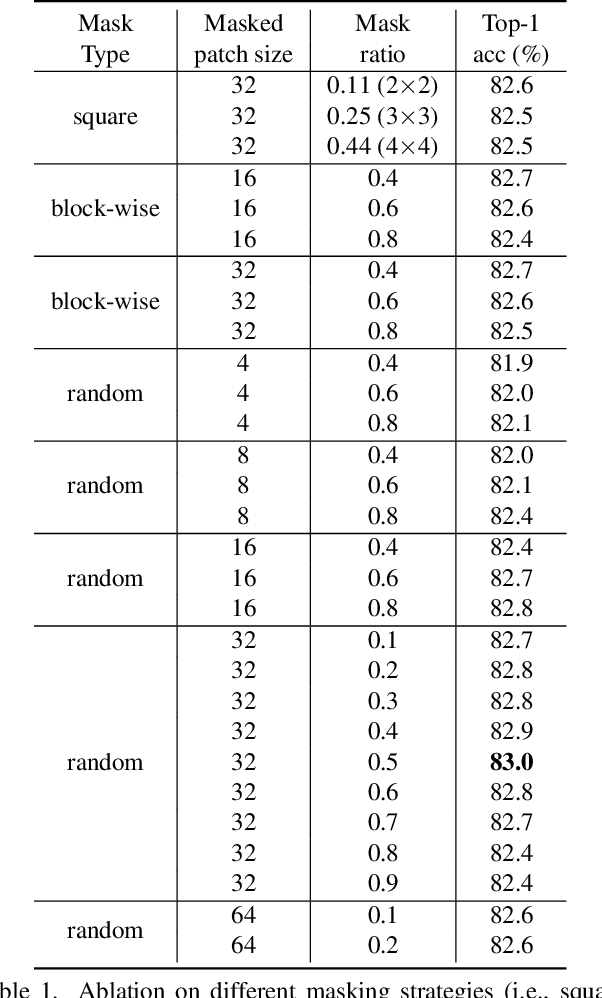

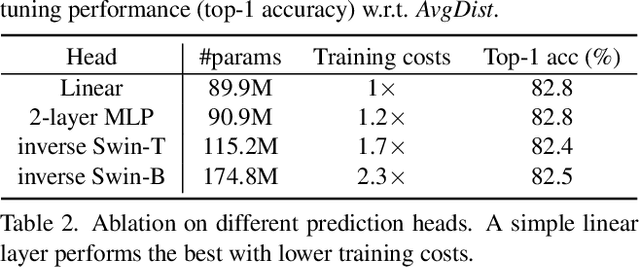
This paper presents SimMIM, a simple framework for masked image modeling. We simplify recently proposed related approaches without special designs such as block-wise masking and tokenization via discrete VAE or clustering. To study what let the masked image modeling task learn good representations, we systematically study the major components in our framework, and find that simple designs of each component have revealed very strong representation learning performance: 1) random masking of the input image with a moderately large masked patch size (e.g., 32) makes a strong pre-text task; 2) predicting raw pixels of RGB values by direct regression performs no worse than the patch classification approaches with complex designs; 3) the prediction head can be as light as a linear layer, with no worse performance than heavier ones. Using ViT-B, our approach achieves 83.8% top-1 fine-tuning accuracy on ImageNet-1K by pre-training also on this dataset, surpassing previous best approach by +0.6%. When applied on a larger model of about 650 million parameters, SwinV2-H, it achieves 87.1% top-1 accuracy on ImageNet-1K using only ImageNet-1K data. We also leverage this approach to facilitate the training of a 3B model (SwinV2-G), that by $40\times$ less data than that in previous practice, we achieve the state-of-the-art on four representative vision benchmarks. The code and models will be publicly available at https://github.com/microsoft/SimMIM.
Swin Transformer V2: Scaling Up Capacity and Resolution
Nov 18, 2021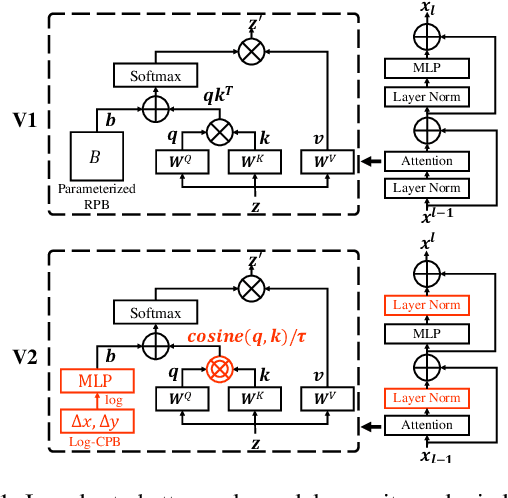
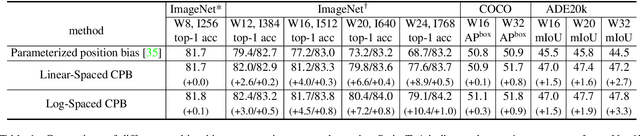
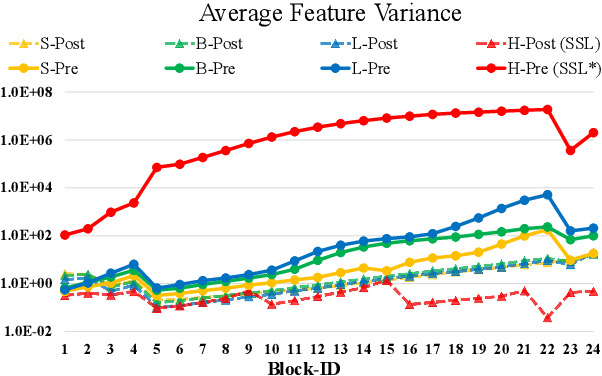
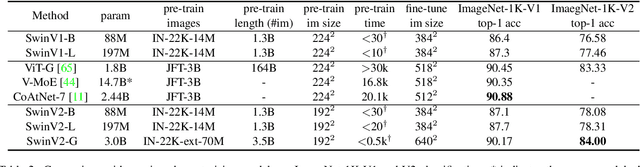
We present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536$\times$1,536 resolution. By scaling up capacity and resolution, Swin Transformer sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1/54.4 box/mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification. Our techniques are generally applicable for scaling up vision models, which has not been widely explored as that of NLP language models, partly due to the following difficulties in training and applications: 1) vision models often face instability issues at scale and 2) many downstream vision tasks require high resolution images or windows and it is not clear how to effectively transfer models pre-trained at low resolutions to higher resolution ones. The GPU memory consumption is also a problem when the image resolution is high. To address these issues, we present several techniques, which are illustrated by using Swin Transformer as a case study: 1) a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models; 2) a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts. In addition, we share our crucial implementation details that lead to significant savings of GPU memory consumption and thus make it feasible to train large vision models with regular GPUs. Using these techniques and self-supervised pre-training, we successfully train a strong 3B Swin Transformer model and effectively transfer it to various vision tasks involving high-resolution images or windows, achieving the state-of-the-art accuracy on a variety of benchmarks.
Self-Supervised Learning with Swin Transformers
May 11, 2021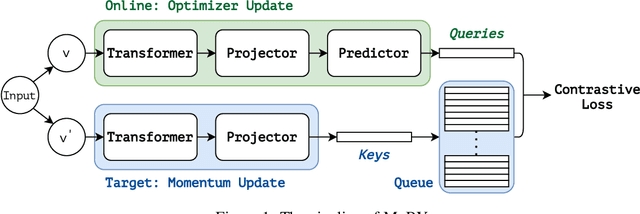



We are witnessing a modeling shift from CNN to Transformers in computer vision. In this work, we present a self-supervised learning approach called MoBY, with Vision Transformers as its backbone architecture. The approach basically has no new inventions, which is combined from MoCo v2 and BYOL and tuned to achieve reasonably high accuracy on ImageNet-1K linear evaluation: 72.8% and 75.0% top-1 accuracy using DeiT-S and Swin-T, respectively, by 300-epoch training. The performance is slightly better than recent works of MoCo v3 and DINO which adopt DeiT as the backbone, but with much lighter tricks. More importantly, the general-purpose Swin Transformer backbone enables us to also evaluate the learnt representations on downstream tasks such as object detection and semantic segmentation, in contrast to a few recent approaches built on ViT/DeiT which only report linear evaluation results on ImageNet-1K due to ViT/DeiT not tamed for these dense prediction tasks. We hope our results can facilitate more comprehensive evaluation of self-supervised learning methods designed for Transformer architectures. Our code and models are available at https://github.com/SwinTransformer/Transformer-SSL, which will be continually enriched.
Disentangled Non-Local Neural Networks
Jun 11, 2020
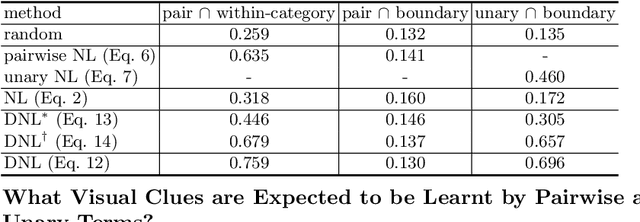

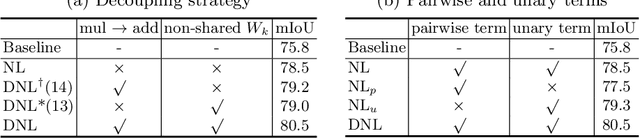
The non-local block is a popular module for strengthening the context modeling ability of a regular convolutional neural network. This paper first studies the non-local block in depth, where we find that its attention computation can be split into two terms, a whitened pairwise term accounting for the relationship between two pixels and a unary term representing the saliency of every pixel. We also observe that the two terms trained alone tend to model different visual clues, e.g. the whitened pairwise term learns within-region relationships while the unary term learns salient boundaries. However, the two terms are tightly coupled in the non-local block, which hinders the learning of each. Based on these findings, we present the disentangled non-local block, where the two terms are decoupled to facilitate learning for both terms. We demonstrate the effectiveness of the decoupled design on various tasks, such as semantic segmentation on Cityscapes, ADE20K and PASCAL Context, object detection on COCO, and action recognition on Kinetics.
Cross-Iteration Batch Normalization
Feb 14, 2020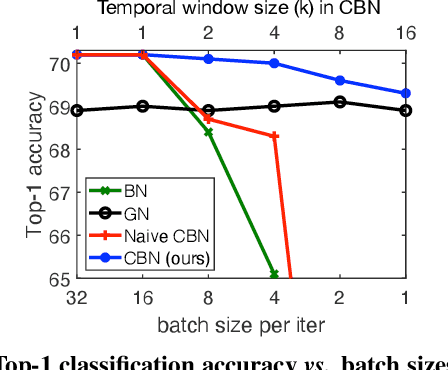



A well-known issue of Batch Normalization is its significantly reduced effectiveness in the case of small mini-batch sizes. When a mini-batch contains few examples, the statistics upon which the normalization is defined cannot be reliably estimated from it during a training iteration. To address this problem, we present Cross-Iteration Batch Normalization (CBN), in which examples from multiple recent iterations are jointly utilized to enhance estimation quality. A challenge of computing statistics over multiple iterations is that the network activations from different iterations are not comparable to each other due to changes in network weights. We thus compensate for the network weight changes via a proposed technique based on Taylor polynomials, so that the statistics can be accurately estimated and batch normalization can be effectively applied. On object detection and image classification with small mini-batch sizes, CBN is found to outperform the original batch normalization and a direct calculation of statistics over previous iterations without the proposed compensation technique.
Balanced Sparsity for Efficient DNN Inference on GPU
Nov 02, 2018



In trained deep neural networks, unstructured pruning can reduce redundant weights to lower storage cost. However, it requires the customization of hardwares to speed up practical inference. Another trend accelerates sparse model inference on general-purpose hardwares by adopting coarse-grained sparsity to prune or regularize consecutive weights for efficient computation. But this method often sacrifices model accuracy. In this paper, we propose a novel fine-grained sparsity approach, balanced sparsity, to achieve high model accuracy with commercial hardwares efficiently. Our approach adapts to high parallelism property of GPU, showing incredible potential for sparsity in the widely deployment of deep learning services. Experiment results show that balanced sparsity achieves up to 3.1x practical speedup for model inference on GPU, while retains the same high model accuracy as fine-grained sparsity.