 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Jan 09, 2026We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Mar 31, 2025



We introduce Open-Reasoner-Zero, the first open source implementation of large-scale reasoning-oriented RL training focusing on scalability, simplicity and accessibility. Through extensive experiments, we demonstrate that a minimalist approach, vanilla PPO with GAE ($\lambda=1$, $\gamma=1$) and straightforward rule-based rewards, without any KL regularization, is sufficient to scale up both response length and benchmark performance, similar to the phenomenon observed in DeepSeek-R1-Zero. Using the same base model as DeepSeek-R1-Zero-Qwen-32B, our implementation achieves superior performance on AIME2024, MATH500, and the GPQA Diamond benchmark while demonstrating remarkable efficiency -- requiring only a tenth of the training steps, compared to DeepSeek-R1-Zero pipeline. In the spirit of open source, we release our source code, parameter settings, training data, and model weights across various sizes.
Predictable Scale: Part I -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining
Mar 06, 2025The impressive capabilities of Large Language Models (LLMs) across diverse tasks are now well-established, yet their effective deployment necessitates careful hyperparameter optimization. Through extensive empirical studies involving grid searches across diverse configurations, we discover universal scaling laws governing these hyperparameters: optimal learning rate follows a power-law relationship with both model parameters and data sizes, while optimal batch size scales primarily with data sizes. Our analysis reveals a convex optimization landscape for hyperparameters under fixed models and data size conditions. This convexity implies an optimal hyperparameter plateau. We contribute a universal, plug-and-play optimal hyperparameter tool for the community. Its estimated values on the test set are merely 0.07\% away from the globally optimal LLM performance found via an exhaustive search. These laws demonstrate remarkable robustness across variations in model sparsity, training data distribution, and model shape. To our best known, this is the first work that unifies different model shapes and structures, such as Mixture-of-Experts models and dense transformers, as well as establishes optimal hyperparameter scaling laws across diverse data distributions. This exhaustive optimization process demands substantial computational resources, utilizing nearly one million NVIDIA H800 GPU hours to train 3,700 LLMs of varying sizes and hyperparameters from scratch and consuming approximately 100 trillion tokens in total. To facilitate reproducibility and further research, we will progressively release all loss measurements and model checkpoints through our designated repository https://step-law.github.io/
Multi-matrix Factorization Attention
Dec 26, 2024



We propose novel attention architectures, Multi-matrix Factorization Attention (MFA) and MFA-Key-Reuse (MFA-KR). Existing variants for standard Multi-Head Attention (MHA), including SOTA methods like MLA, fail to maintain as strong performance under stringent Key-Value cache (KV cache) constraints. MFA enhances model capacity by efficiently scaling up both the number and dimension of attention heads through low-rank matrix factorization in the Query-Key (QK) circuit. Extending MFA, MFA-KR further reduces memory requirements by repurposing the key cache as value through value projection re-parameterization. MFA's design enables strong model capacity when working under tight KV cache budget, while MFA-KR is suitable for even harsher KV cache limits with minor performance trade-off. Notably, in our extensive and large-scale experiments, the proposed architecture outperforms MLA and performs comparably to MHA, while reducing KV cache usage by up to 56% and 93.7%, respectively.
Common 7B Language Models Already Possess Strong Math Capabilities
Mar 07, 2024



Mathematical capabilities were previously believed to emerge in common language models only at a very large scale or require extensive math-related pre-training. This paper shows that the LLaMA-2 7B model with common pre-training already exhibits strong mathematical abilities, as evidenced by its impressive accuracy of 97.7% and 72.0% on the GSM8K and MATH benchmarks, respectively, when selecting the best response from 256 random generations. The primary issue with the current base model is the difficulty in consistently eliciting its inherent mathematical capabilities. Notably, the accuracy for the first answer drops to 49.5% and 7.9% on the GSM8K and MATH benchmarks, respectively. We find that simply scaling up the SFT data can significantly enhance the reliability of generating correct answers. However, the potential for extensive scaling is constrained by the scarcity of publicly available math questions. To overcome this limitation, we employ synthetic data, which proves to be nearly as effective as real data and shows no clear saturation when scaled up to approximately one million samples. This straightforward approach achieves an accuracy of 82.6% on GSM8K and 40.6% on MATH using LLaMA-2 7B models, surpassing previous models by 14.2% and 20.8%, respectively. We also provide insights into scaling behaviors across different reasoning complexities and error types.
FP8-LM: Training FP8 Large Language Models
Oct 27, 2023



In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters. Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner. Experiment results show that, during the training of GPT-175B model on H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%. This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses. Our FP8 low-precision training framework is open-sourced at {https://github.com/Azure/MS-AMP}{aka.ms/MS.AMP}.
Revealing the Dark Secrets of Masked Image Modeling
May 27, 2022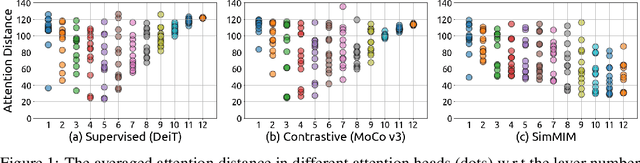

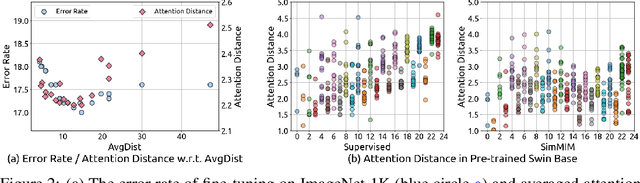
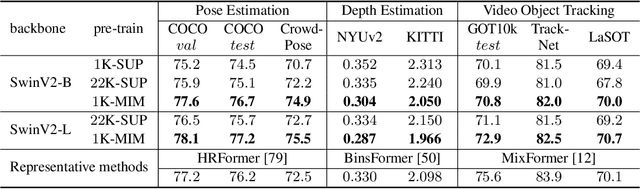
Masked image modeling (MIM) as pre-training is shown to be effective for numerous vision downstream tasks, but how and where MIM works remain unclear. In this paper, we compare MIM with the long-dominant supervised pre-trained models from two perspectives, the visualizations and the experiments, to uncover their key representational differences. From the visualizations, we find that MIM brings locality inductive bias to all layers of the trained models, but supervised models tend to focus locally at lower layers but more globally at higher layers. That may be the reason why MIM helps Vision Transformers that have a very large receptive field to optimize. Using MIM, the model can maintain a large diversity on attention heads in all layers. But for supervised models, the diversity on attention heads almost disappears from the last three layers and less diversity harms the fine-tuning performance. From the experiments, we find that MIM models can perform significantly better on geometric and motion tasks with weak semantics or fine-grained classification tasks, than their supervised counterparts. Without bells and whistles, a standard MIM pre-trained SwinV2-L could achieve state-of-the-art performance on pose estimation (78.9 AP on COCO test-dev and 78.0 AP on CrowdPose), depth estimation (0.287 RMSE on NYUv2 and 1.966 RMSE on KITTI), and video object tracking (70.7 SUC on LaSOT). For the semantic understanding datasets where the categories are sufficiently covered by the supervised pre-training, MIM models can still achieve highly competitive transfer performance. With a deeper understanding of MIM, we hope that our work can inspire new and solid research in this direction.