 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Tabular Research via Continual Experience-Driven Execution
Mar 12, 2026Large language models often struggle with complex long-horizon analytical tasks over unstructured tables, which typically feature hierarchical and bidirectional headers and non-canonical layouts. We formalize this challenge as Deep Tabular Research (DTR), requiring multi-step reasoning over interdependent table regions. To address DTR, we propose a novel agentic framework that treats tabular reasoning as a closed-loop decision-making process. We carefully design a coupled query and table comprehension for path decision making and operational execution. Specifically, (i) DTR first constructs a hierarchical meta graph to capture bidirectional semantics, mapping natural language queries into an operation-level search space; (ii) To navigate this space, we introduce an expectation-aware selection policy that prioritizes high-utility execution paths; (iii) Crucially, historical execution outcomes are synthesized into a siamese structured memory, i.e., parameterized updates and abstracted texts, enabling continual refinement. Extensive experiments on challenging unstructured tabular benchmarks verify the effectiveness and highlight the necessity of separating strategic planning from low-level execution for long-horizon tabular reasoning.
TempoFit: Plug-and-Play Layer-Wise Temporal KV Memory for Long-Horizon Vision-Language-Action Manipulation
Mar 08, 2026Pretrained Vision-Language-Action (VLA) policies have achieved strong single-step manipulation, but their inference remains largely memoryless, which is brittle in non-Markovian long-horizon settings with occlusion, state aliasing, and subtle post-action changes. Prior approaches inject history either by stacking frames, which scales visual tokens and latency while adding near-duplicate pixels, or by learning additional temporal interfaces that require (re-)training and may break the original single-frame inference graph. We present TempoFit, a training-free temporal retrofit that upgrades frozen VLAs through state-level memory. Our key insight is that prefix attention K/V already form a model-native, content-addressable runtime state; reusing them across timesteps introduces history without new tokens or trainable modules. TempoFit stores layer-wise FIFO prefix K/V at selected intermediate layers, performs parameter-free K-to-K retrieval with Frame-Gap Temporal Bias (FGTB), a fixed recency bias inspired by positional biases in NLP, to keep decisions present-dominant, and injects the retrieved context via pre-attention residual loading with norm-preserving rescaling to avoid distribution shift under frozen weights. On LIBERO-LONG, TempoFit improves strong pretrained backbones by up to +4.0% average success rate while maintaining near-real-time latency, and it transfers consistently to CALVIN and real-robot long-horizon tasks.
Force-Aware Residual DAgger via Trajectory Editing for Precision Insertion with Impedance Control
Mar 04, 2026Imitation learning (IL) has shown strong potential for contact-rich precision insertion tasks. However, its practical deployment is often hindered by covariate shift and the need for continuous expert monitoring to recover from failures during execution. In this paper, we propose Trajectory Editing Residual Dataset Aggregation (TER-DAgger), a scalable and force-aware human-in-the-loop imitation learning framework that mitigates covariate shift by learning residual policies through optimization-based trajectory editing. This approach smoothly fuses policy rollouts with human corrective trajectories, providing consistent and stable supervision. Second, we introduce a force-aware failure anticipation mechanism that triggers human intervention only when discrepancies arise between predicted and measured end-effector forces, significantly reducing the requirement for continuous expert monitoring. Third, all learned policies are executed within a Cartesian impedance control framework, ensuring compliant and safe behavior during contact-rich interactions. Extensive experiments in both simulation and real-world precision insertion tasks show that TER-DAgger improves the average success rate by over 37\% compared to behavior cloning, human-guided correction, retraining, and fine-tuning baselines, demonstrating its effectiveness in mitigating covariate shift and enabling scalable deployment in contact-rich manipulation.
RU4D-SLAM: Reweighting Uncertainty in Gaussian Splatting SLAM for 4D Scene Reconstruction
Feb 24, 2026Combining 3D Gaussian splatting with Simultaneous Localization and Mapping (SLAM) has gained popularity as it enables continuous 3D environment reconstruction during motion. However, existing methods struggle in dynamic environments, particularly moving objects complicate 3D reconstruction and, in turn, hinder reliable tracking. The emergence of 4D reconstruction, especially 4D Gaussian splatting, offers a promising direction for addressing these challenges, yet its potential for 4D-aware SLAM remains largely underexplored. Along this direction, we propose a robust and efficient framework, namely Reweighting Uncertainty in Gaussian Splatting SLAM (RU4D-SLAM) for 4D scene reconstruction, that introduces temporal factors into spatial 3D representation while incorporating uncertainty-aware perception of scene changes, blurred image synthesis, and dynamic scene reconstruction. We enhance dynamic scene representation by integrating motion blur rendering, and improve uncertainty-aware tracking by extending per-pixel uncertainty modeling, which is originally designed for static scenarios, to handle blurred images. Furthermore, we propose a semantic-guided reweighting mechanism for per-pixel uncertainty estimation in dynamic scenes, and introduce a learnable opacity weight to support adaptive 4D mapping. Extensive experiments on standard benchmarks demonstrate that our method substantially outperforms state-of-the-art approaches in both trajectory accuracy and 4D scene reconstruction, particularly in dynamic environments with moving objects and low-quality inputs. Code available: https://ru4d-slam.github.io
Pareto-Guided Optimization for Uncertainty-Aware Medical Image Segmentation
Jan 27, 2026Uncertainty in medical image segmentation is inherently non-uniform, with boundary regions exhibiting substantially higher ambiguity than interior areas. Conventional training treats all pixels equally, leading to unstable optimization during early epochs when predictions are unreliable. We argue that this instability hinders convergence toward Pareto-optimal solutions and propose a region-wise curriculum strategy that prioritizes learning from certain regions and gradually incorporates uncertain ones, reducing gradient variance. Methodologically, we introduce a Pareto-consistent loss that balances trade-offs between regional uncertainties by adaptively reshaping the loss landscape and constraining convergence dynamics between interior and boundary regions; this guides the model toward Pareto-approximate solutions. To address boundary ambiguity, we further develop a fuzzy labeling mechanism that maintains binary confidence in non-boundary areas while enabling smooth transitions near boundaries, stabilizing gradients, and expanding flat regions in the loss surface. Experiments on brain metastasis and non-metastatic tumor segmentation show consistent improvements across multiple configurations, with our method outperforming traditional crisp-set approaches in all tumor subregions.
Numina-Lean-Agent: An Open and General Agentic Reasoning System for Formal Mathematics
Jan 20, 2026Agentic systems have recently become the dominant paradigm for formal theorem proving, achieving strong performance by coordinating multiple models and tools. However, existing approaches often rely on task-specific pipelines and trained formal provers, limiting their flexibility and reproducibility. In this paper, we propose the paradigm that directly uses a general coding agent as a formal math reasoner. This paradigm is motivated by (1) A general coding agent provides a natural interface for diverse reasoning tasks beyond proving, (2) Performance can be improved by simply replacing the underlying base model, without training, and (3) MCP enables flexible extension and autonomous calling of specialized tools, avoiding complex design. Based on this paradigm, we introduce Numina-Lean-Agent, which combines Claude Code with Numina-Lean-MCP to enable autonomous interaction with Lean, retrieval of relevant theorems, informal proving and auxiliary reasoning tools. Using Claude Opus 4.5 as the base model, Numina-Lean-Agent solves all problems in Putnam 2025 (12 / 12), matching the best closed-source system. Beyond benchmark evaluation, we further demonstrate its generality by interacting with mathematicians to successfully formalize the Brascamp-Lieb theorem. We release Numina-Lean-Agent and all solutions at https://github.com/project-numina/numina-lean-agent.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
LLM-Driven Completeness and Consistency Evaluation for Cultural Heritage Data Augmentation in Cross-Modal Retrieval
Nov 09, 2025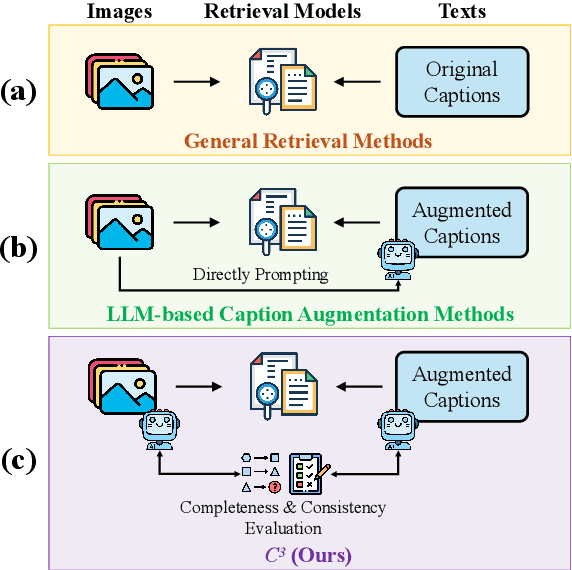
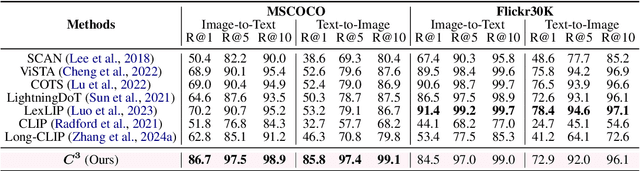
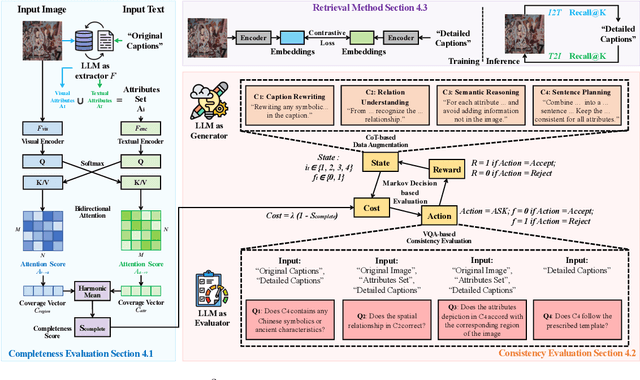
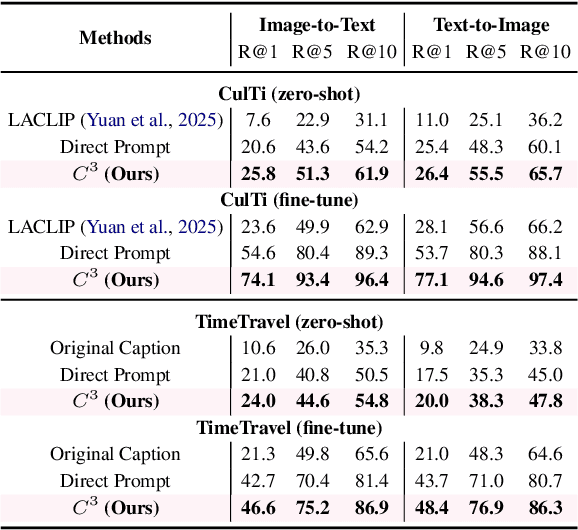
Cross-modal retrieval is essential for interpreting cultural heritage data, but its effectiveness is often limited by incomplete or inconsistent textual descriptions, caused by historical data loss and the high cost of expert annotation. While large language models (LLMs) offer a promising solution by enriching textual descriptions, their outputs frequently suffer from hallucinations or miss visually grounded details. To address these challenges, we propose $C^3$, a data augmentation framework that enhances cross-modal retrieval performance by improving the completeness and consistency of LLM-generated descriptions. $C^3$ introduces a completeness evaluation module to assess semantic coverage using both visual cues and language-model outputs. Furthermore, to mitigate factual inconsistencies, we formulate a Markov Decision Process to supervise Chain-of-Thought reasoning, guiding consistency evaluation through adaptive query control. Experiments on the cultural heritage datasets CulTi and TimeTravel, as well as on general benchmarks MSCOCO and Flickr30K, demonstrate that $C^3$ achieves state-of-the-art performance in both fine-tuned and zero-shot settings.
Can MLLMs Absorb Math Reasoning Abilities from LLMs as Free Lunch?
Oct 16, 2025Math reasoning has been one crucial ability of large language models (LLMs), where significant advancements have been achieved in recent years. However, most efforts focus on LLMs by curating high-quality annotation data and intricate training (or inference) paradigms, while the math reasoning performance of multi-modal LLMs (MLLMs) remains lagging behind. Since the MLLM typically consists of an LLM and a vision block, we wonder: Can MLLMs directly absorb math reasoning abilities from off-the-shelf math LLMs without tuning? Recent model-merging approaches may offer insights into this question. However, they overlook the alignment between the MLLM and LLM, where we find that there is a large gap between their parameter spaces, resulting in lower performance. Our empirical evidence reveals two key factors behind this issue: the identification of crucial reasoning-associated layers in the model and the mitigation of the gaps in parameter space. Based on the empirical insights, we propose IP-Merging that first identifies the reasoning-associated parameters in both MLLM and Math LLM, then projects them into the subspace of MLLM, aiming to maintain the alignment, and finally merges parameters in this subspace. IP-Merging is a tuning-free approach since parameters are directly adjusted. Extensive experiments demonstrate that our IP-Merging method can enhance the math reasoning ability of MLLMs directly from Math LLMs without compromising their other capabilities.
Towards Understanding Feature Learning in Parameter Transfer
Sep 26, 2025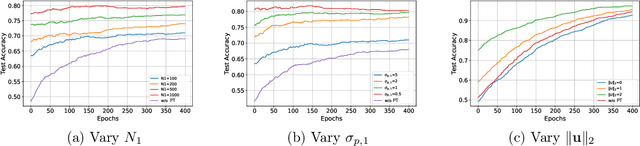
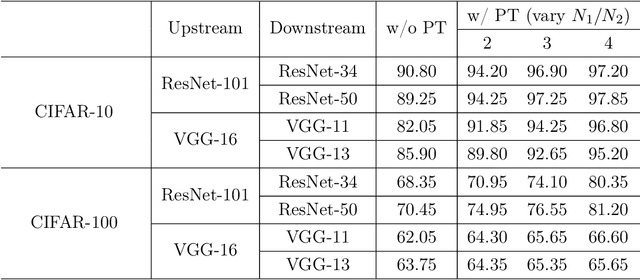
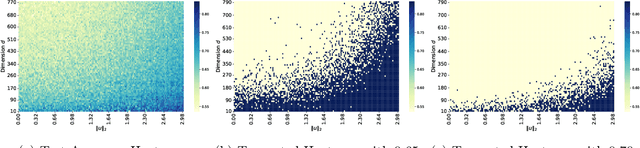
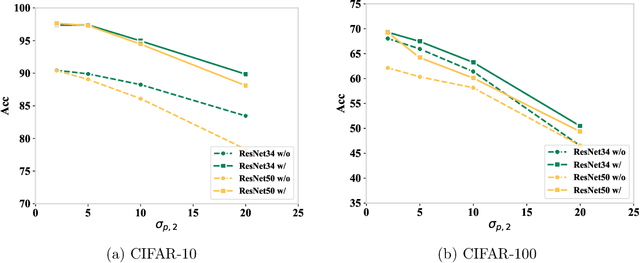
Parameter transfer is a central paradigm in transfer learning, enabling knowledge reuse across tasks and domains by sharing model parameters between upstream and downstream models. However, when only a subset of parameters from the upstream model is transferred to the downstream model, there remains a lack of theoretical understanding of the conditions under which such partial parameter reuse is beneficial and of the factors that govern its effectiveness. To address this gap, we analyze a setting in which both the upstream and downstream models are ReLU convolutional neural networks (CNNs). Within this theoretical framework, we characterize how the inherited parameters act as carriers of universal knowledge and identify key factors that amplify their beneficial impact on the target task. Furthermore, our analysis provides insight into why, in certain cases, transferring parameters can lead to lower test accuracy on the target task than training a new model from scratch. Numerical experiments and real-world data experiments are conducted to empirically validate our theoretical findings.