 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENE-FL: Gene-Driven Parameter-Efficient Dynamic Federated Learning
Apr 20, 2025Real-world \underline{F}ederated \underline{L}earning systems often encounter \underline{D}ynamic clients with \underline{A}gnostic and highly heterogeneous data distributions (DAFL), which pose challenges for efficient communication and model initialization. To address these challenges, we draw inspiration from the recently proposed Learngene paradigm, which compresses the large-scale model into lightweight, cross-task meta-information fragments. Learngene effectively encapsulates and communicates core knowledge, making it particularly well-suited for DAFL, where dynamic client participation requires communication efficiency and rapid adaptation to new data distributions. Based on this insight, we propose a Gene-driven parameter-efficient dynamic Federated Learning (GENE-FL) framework. First, local models perform quadratic constraints based on parameters with high Fisher values in the global model, as these parameters are considered to encapsulate generalizable knowledge. Second, we apply the strategy of parameter sensitivity analysis in local model parameters to condense the \textit{learnGene} for interaction. Finally, the server aggregates these small-scale trained \textit{learnGene}s into a robust \textit{learnGene} with cross-task generalization capability, facilitating the rapid initialization of dynamic agnostic client models. Extensive experimental results demonstrate that GENE-FL reduces \textbf{4 $\times$} communication costs compared to FEDAVG and effectively initializes agnostic client models with only about \textbf{9.04} MB.
STHFL: Spatio-Temporal Heterogeneous Federated Learning
Jan 10, 2025Federated learning is a new framework that protects data privacy and allows multiple devices to cooperate in training machine learning models. Previous studies have proposed multiple approaches to eliminate the challenges posed by non-iid data and inter-domain heterogeneity issues. However, they ignore the \textbf{spatio-temporal} heterogeneity formed by different data distributions of increasing task data in the intra-domain. Moreover, the global data is generally a long-tailed distribution rather than assuming the global data is balanced in practical applications. To tackle the \textbf{spatio-temporal} dilemma, we propose a novel setting named \textbf{Spatio-Temporal Heterogeneity} Federated Learning (STHFL). Specially, the Global-Local Dynamic Prototype (GLDP) framework is designed for STHFL. In GLDP, the model in each client contains personalized layers which can dynamically adapt to different data distributions. For long-tailed data distribution, global prototypes are served as complementary knowledge for the training on classes with few samples in clients without leaking privacy. As tasks increase in clients, the knowledge of local prototypes generated in previous tasks guides for training in the current task to solve catastrophic forgetting. Meanwhile, the global-local prototypes are updated through the moving average method after training local prototypes in clients. Finally, we evaluate the effectiveness of GLDP, which achieves remarkable results compared to state-of-the-art methods in STHFL scenarios.
Addressing Skewed Heterogeneity via Federated Prototype Rectification with Personalization
Aug 15, 2024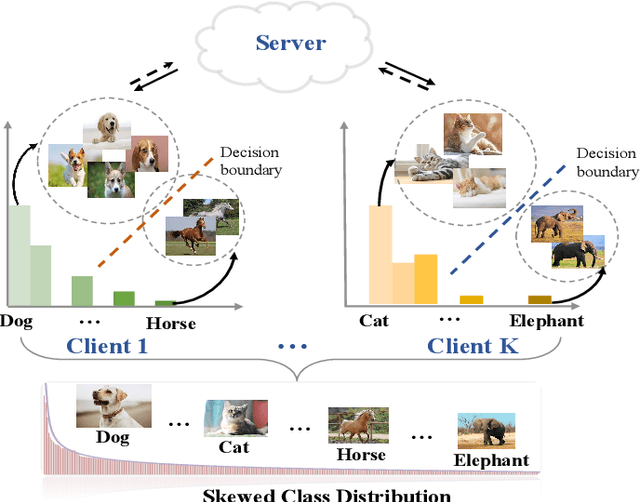
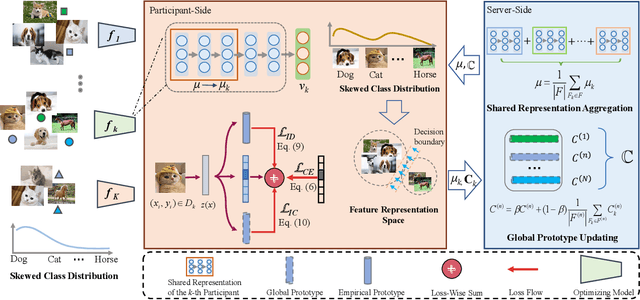

Federated learning is an efficient framework designed to facilitate collaborative model training across multiple distributed devices while preserving user data privacy. A significant challenge of federated learning is data-level heterogeneity, i.e., skewed or long-tailed distribution of private data. Although various methods have been proposed to address this challenge, most of them assume that the underlying global data is uniformly distributed across all clients. This paper investigates data-level heterogeneity federated learning with a brief review and redefines a more practical and challenging setting called Skewed Heterogeneous Federated Learning (SHFL). Accordingly, we propose a novel Federated Prototype Rectification with Personalization which consists of two parts: Federated Personalization and Federated Prototype Rectification. The former aims to construct balanced decision boundaries between dominant and minority classes based on private data, while the latter exploits both inter-class discrimination and intra-class consistency to rectify empirical prototypes. Experiments on three popular benchmarks show that the proposed approach outperforms current state-of-the-art methods and achieves balanced performance in both personalization and generalization.
Dynamic Heterogeneous Federated Learning with Multi-Level Prototypes
Dec 15, 2023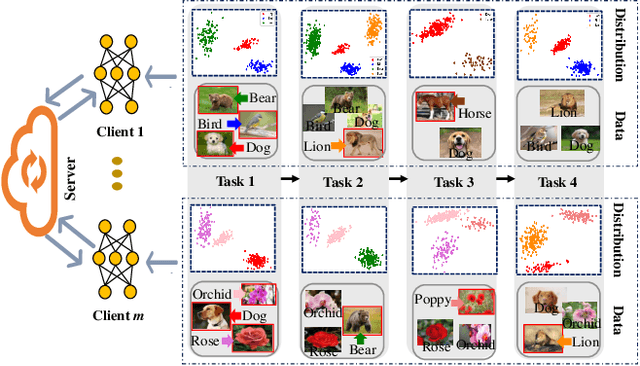
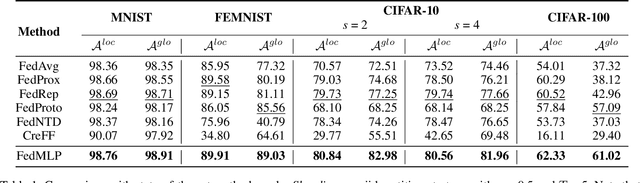
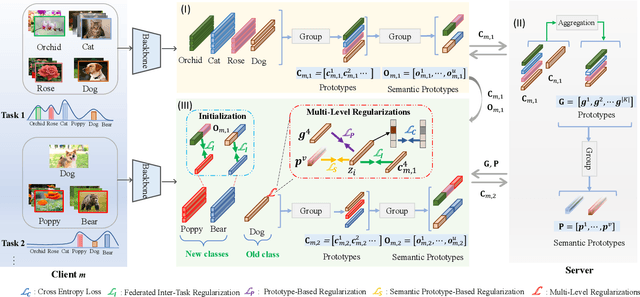
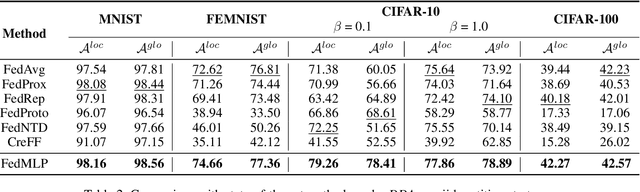
Federated learning shows promise as a privacy-preserving collaborative learning technique. Existing heterogeneous federated learning mainly focuses on skewing the label distribution across clients. However, most approaches suffer from catastrophic forgetting and concept drift, mainly when the global distribution of all classes is extremely unbalanced and the data distribution of the client dynamically evolves over time. In this paper, we study the new task, i.e., Dynamic Heterogeneous Federated Learning (DHFL), which addresses the practical scenario where heterogeneous data distributions exist among different clients and dynamic tasks within the client. Accordingly, we propose a novel federated learning framework named Federated Multi-Level Prototypes (FedMLP) and design federated multi-level regularizations. To mitigate concept drift, we construct prototypes and semantic prototypes to provide fruitful generalization knowledge and ensure the continuity of prototype spaces. To maintain the model stability and consistency of convergence, three regularizations are introduced as training losses, i.e., prototype-based regularization, semantic prototype-based regularization, and federated inter-task regularization. Extensive experiments show that the proposed method achieves state-of-the-art performance in various settings.