 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeGene: Reusable Adapters for Transferable Safety Alignment
Jun 02, 2026Open-weight LLMs are increasingly fine-tuned into customized assistants, but downstream fine-tuning can weaken safety alignment and make models more vulnerable to malicious prompts, even when the training data is not intentionally harmful. This creates a recurring safety recovery problem as target models are repeatedly updated with new task data or user interactions. We propose SafeGene, a reusable safety-adapter module designed for cross-task reuse within each architecture-compatible model family. Rather than treating safety recovery as a model-specific repair step, SafeGene treats safety capability as an independent, reusable adapter representation decoupled from task-specific updates. This representation is obtained from aligned--degraded model discrepancies, refined into task-transferable safety vectors through data-aware layer selection, and expressed in each downstream task-adapted model via few-shot layer-wise coefficient recalibration. Experiments across multiple model families, downstream tasks, and safety judges show that SafeGene-enhanced models reduce harmful response rates while maintaining downstream performance, outperforming representative safe adaptation methods in safety--utility trade-off.
Trustworthy Federated Label Distribution Learning under Annotation Quality Disparity
May 06, 2026Label Distribution Learning (LDL) models supervision as an instance-wise probability distribution, enabling fine-grained learning under inherent ambiguity, but its success relies on high-fidelity label distributions that are costly to obtain and thus often noisy. Motivated by privacy-sensitive applications, we study Federated Label Distribution Learning (Fed-LDL), where data isolation further induces heterogeneous annotation quality across clients, making local updates unevenly reliable and breaking sample-size-based aggregation (e.g., FedAvg). To address this trust dilemma, we propose FedQual, a quality-aware Fed-LDL framework with two coupled mechanisms: (i) quality-adaptive client training guided by a global semantic anchor that calibrates low-quality clients while preserving high-quality autonomy, and (ii) reliability-aware server aggregation that reweights client contributions by effective reliable information rather than raw sample size. To enable rigorous evaluation, we construct four new Fed-LDL benchmarks (FER-LDL, FI-LDL, PIPAL-LDL, and KADID-LDL) with controlled annotation quality disparity. We further provide a theoretical guarantee showing that under heterogeneous supervision quality, client-specific calibration is strictly better than any uniform calibration. Extensive experiments on the proposed benchmarks demonstrate the effectiveness of FedQual.
Are Multimodal Large Language Models Good Annotators for Image Tagging?
Feb 24, 2026Image tagging, a fundamental vision task, traditionally relies on human-annotated datasets to train multi-label classifiers, which incurs significant labor and costs. While Multimodal Large Language Models (MLLMs) offer promising potential to automate annotation, their capability to replace human annotators remains underexplored. This paper aims to analyze the gap between MLLM-generated and human annotations and to propose an effective solution that enables MLLM-based annotation to replace manual labeling. Our analysis of MLLM annotations reveals that, under a conservative estimate, MLLMs can reduce annotation cost to as low as one-thousandth of the human cost, mainly accounting for GPU usage, which is nearly negligible compared to manual efforts. Their annotation quality reaches about 50\% to 80\% of human performance, while achieving over 90\% performance on downstream training tasks.Motivated by these findings, we propose TagLLM, a novel framework for image tagging, which aims to narrow the gap between MLLM-generated and human annotations. TagLLM comprises two components: Candidates generation, which employs structured group-wise prompting to efficiently produce a compact candidate set that covers as many true labels as possible while reducing subsequent annotation workload; and label disambiguation, which interactively calibrates the semantic concept of categories in the prompts and effectively refines the candidate labels. Extensive experiments show that TagLLM substantially narrows the gap between MLLM-generated and human annotations, especially in downstream training performance, where it closes about 60\% to 80\% of the difference.
LoGoSeg: Integrating Local and Global Features for Open-Vocabulary Semantic Segmentation
Feb 05, 2026Open-vocabulary semantic segmentation (OVSS) extends traditional closed-set segmentation by enabling pixel-wise annotation for both seen and unseen categories using arbitrary textual descriptions. While existing methods leverage vision-language models (VLMs) like CLIP, their reliance on image-level pretraining often results in imprecise spatial alignment, leading to mismatched segmentations in ambiguous or cluttered scenes. However, most existing approaches lack strong object priors and region-level constraints, which can lead to object hallucination or missed detections, further degrading performance. To address these challenges, we propose LoGoSeg, an efficient single-stage framework that integrates three key innovations: (i) an object existence prior that dynamically weights relevant categories through global image-text similarity, effectively reducing hallucinations; (ii) a region-aware alignment module that establishes precise region-level visual-textual correspondences; and (iii) a dual-stream fusion mechanism that optimally combines local structural information with global semantic context. Unlike prior works, LoGoSeg eliminates the need for external mask proposals, additional backbones, or extra datasets, ensuring efficiency. Extensive experiments on six benchmarks (A-847, PC-459, A-150, PC-59, PAS-20, and PAS-20b) demonstrate its competitive performance and strong generalization in open-vocabulary settings.
Positive-Unlabeled Reinforcement Learning Distillation for On-Premise Small Models
Jan 28, 2026Due to constraints on privacy, cost, and latency, on-premise deployment of small models is increasingly common. However, most practical pipelines stop at supervised fine-tuning (SFT) and fail to reach the reinforcement learning (RL) alignment stage. The main reason is that RL alignment typically requires either expensive human preference annotation or heavy reliance on high-quality reward models with large-scale API usage and ongoing engineering maintenance, both of which are ill-suited to on-premise settings. To bridge this gap, we propose a positive-unlabeled (PU) RL distillation method for on-premise small-model deployment. Without human-labeled preferences or a reward model, our method distills the teacher's preference-optimization capability from black-box generations into a locally trainable student. For each prompt, we query the teacher once to obtain an anchor response, locally sample multiple student candidates, and perform anchor-conditioned self-ranking to induce pairwise or listwise preferences, enabling a fully local training loop via direct preference optimization or group relative policy optimization. Theoretical analysis justifies that the induced preference signal by our method is order-consistent and concentrates on near-optimal candidates, supporting its stability for preference optimization. Experiments demonstrate that our method achieves consistently strong performance under a low-cost setting.
Toward Efficient Agents: Memory, Tool learning, and Planning
Jan 20, 2026Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
Object-level Correlation for Few-Shot Segmentation
Sep 09, 2025Few-shot semantic segmentation (FSS) aims to segment objects of novel categories in the query images given only a few annotated support samples. Existing methods primarily build the image-level correlation between the support target object and the entire query image. However, this correlation contains the hard pixel noise, \textit{i.e.}, irrelevant background objects, that is intractable to trace and suppress, leading to the overfitting of the background. To address the limitation of this correlation, we imitate the biological vision process to identify novel objects in the object-level information. Target identification in the general objects is more valid than in the entire image, especially in the low-data regime. Inspired by this, we design an Object-level Correlation Network (OCNet) by establishing the object-level correlation between the support target object and query general objects, which is mainly composed of the General Object Mining Module (GOMM) and Correlation Construction Module (CCM). Specifically, GOMM constructs the query general object feature by learning saliency and high-level similarity cues, where the general objects include the irrelevant background objects and the target foreground object. Then, CCM establishes the object-level correlation by allocating the target prototypes to match the general object feature. The generated object-level correlation can mine the query target feature and suppress the hard pixel noise for the final prediction. Extensive experiments on PASCAL-${5}^{i}$ and COCO-${20}^{i}$ show that our model achieves the state-of-the-art performance.
Label Distribution Learning with Biased Annotations by Learning Multi-Label Representation
Feb 03, 2025Multi-label learning (MLL) has gained attention for its ability to represent real-world data. Label Distribution Learning (LDL), an extension of MLL to learning from label distributions, faces challenges in collecting accurate label distributions. To address the issue of biased annotations, based on the low-rank assumption, existing works recover true distributions from biased observations by exploring the label correlations. However, recent evidence shows that the label distribution tends to be full-rank, and naive apply of low-rank approximation on biased observation leads to inaccurate recovery and performance degradation. In this paper, we address the LDL with biased annotations problem from a novel perspective, where we first degenerate the soft label distribution into a hard multi-hot label and then recover the true label information for each instance. This idea stems from an insight that assigning hard multi-hot labels is often easier than assigning a soft label distribution, and it shows stronger immunity to noise disturbances, leading to smaller label bias. Moreover, assuming that the multi-label space for predicting label distributions is low-rank offers a more reasonable approach to capturing label correlations. Theoretical analysis and experiments confirm the effectiveness and robustness of our method on real-world datasets.
Towards Better Performance in Incomplete LDL: Addressing Data Imbalance
Oct 17, 2024



Label Distribution Learning (LDL) is a novel machine learning paradigm that addresses the problem of label ambiguity and has found widespread applications. Obtaining complete label distributions in real-world scenarios is challenging, which has led to the emergence of Incomplete Label Distribution Learning (InLDL). However, the existing InLDL methods overlook a crucial aspect of LDL data: the inherent imbalance in label distributions. To address this limitation, we propose \textbf{Incomplete and Imbalance Label Distribution Learning (I\(^2\)LDL)}, a framework that simultaneously handles incomplete labels and imbalanced label distributions. Our method decomposes the label distribution matrix into a low-rank component for frequent labels and a sparse component for rare labels, effectively capturing the structure of both head and tail labels. We optimize the model using the Alternating Direction Method of Multipliers (ADMM) and derive generalization error bounds via Rademacher complexity, providing strong theoretical guarantees. Extensive experiments on 15 real-world datasets demonstrate the effectiveness and robustness of our proposed framework compared to existing InLDL methods.
Addressing Skewed Heterogeneity via Federated Prototype Rectification with Personalization
Aug 15, 2024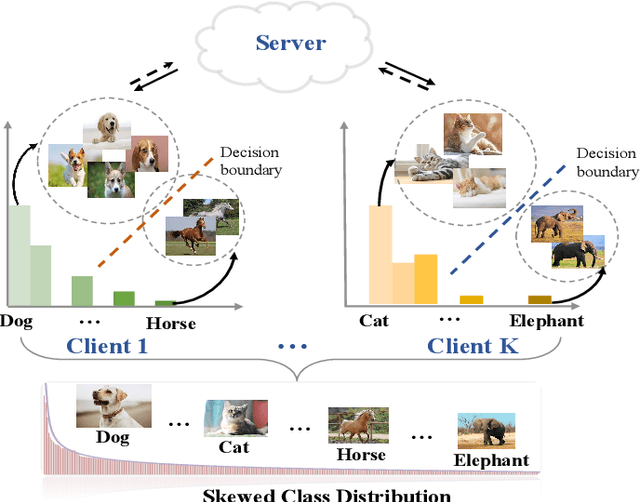
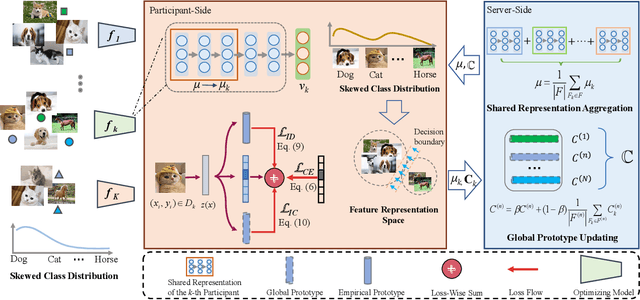

Federated learning is an efficient framework designed to facilitate collaborative model training across multiple distributed devices while preserving user data privacy. A significant challenge of federated learning is data-level heterogeneity, i.e., skewed or long-tailed distribution of private data. Although various methods have been proposed to address this challenge, most of them assume that the underlying global data is uniformly distributed across all clients. This paper investigates data-level heterogeneity federated learning with a brief review and redefines a more practical and challenging setting called Skewed Heterogeneous Federated Learning (SHFL). Accordingly, we propose a novel Federated Prototype Rectification with Personalization which consists of two parts: Federated Personalization and Federated Prototype Rectification. The former aims to construct balanced decision boundaries between dominant and minority classes based on private data, while the latter exploits both inter-class discrimination and intra-class consistency to rectify empirical prototypes. Experiments on three popular benchmarks show that the proposed approach outperforms current state-of-the-art methods and achieves balanced performance in both personalization and generalization.