 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Distribution Learning with Biased Annotations by Learning Multi-Label Representation
Feb 03, 2025Multi-label learning (MLL) has gained attention for its ability to represent real-world data. Label Distribution Learning (LDL), an extension of MLL to learning from label distributions, faces challenges in collecting accurate label distributions. To address the issue of biased annotations, based on the low-rank assumption, existing works recover true distributions from biased observations by exploring the label correlations. However, recent evidence shows that the label distribution tends to be full-rank, and naive apply of low-rank approximation on biased observation leads to inaccurate recovery and performance degradation. In this paper, we address the LDL with biased annotations problem from a novel perspective, where we first degenerate the soft label distribution into a hard multi-hot label and then recover the true label information for each instance. This idea stems from an insight that assigning hard multi-hot labels is often easier than assigning a soft label distribution, and it shows stronger immunity to noise disturbances, leading to smaller label bias. Moreover, assuming that the multi-label space for predicting label distributions is low-rank offers a more reasonable approach to capturing label correlations. Theoretical analysis and experiments confirm the effectiveness and robustness of our method on real-world datasets.
Unlocking the Power of Open Set : A New Perspective for Open-set Noisy Label Learning
May 07, 2023
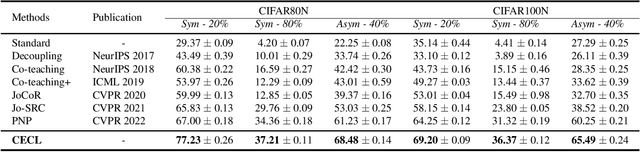
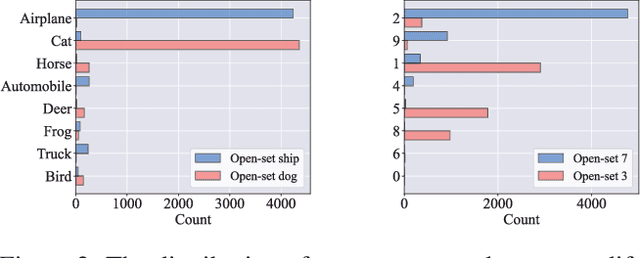
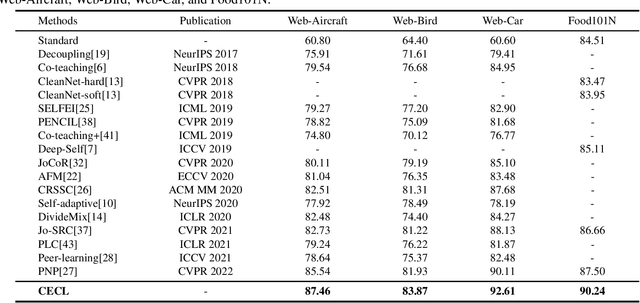
Learning from noisy data has attracted much attention, where most methods focus on closed-set label noise. However, a more common scenario in the real world is the presence of both open-set and closed-set noise. Existing methods typically identify and handle these two types of label noise separately by designing a specific strategy for each type. However, in many real-world scenarios, it would be challenging to identify open-set examples, especially when the dataset has been severely corrupted. Unlike the previous works, we explore how models behave when faced open-set examples, and find that a part of open-set examples gradually get integrated into certain known classes, which is beneficial for the seperation among known classes. Motivated by the phenomenon, in this paper, we propose a novel two-step contrastive learning method called CECL, which aims to deal with both types of label noise by exploiting the useful information of open-set examples. Specifically, we incorporate some open-set examples into closed-set classes to enhance performance while treating others as delimiters to improve representative ability. Extensive experiments on synthetic and real-world datasets with diverse label noise demonstrate that CECL can outperform state-of-the-art methods.