 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilter, Obstruct and Dilute: Defending Against Backdoor Attacks on Semi-Supervised Learning
Feb 09, 2025Recent studies have verified that semi-supervised learning (SSL) is vulnerable to data poisoning backdoor attacks. Even a tiny fraction of contaminated training data is sufficient for adversaries to manipulate up to 90\% of the test outputs in existing SSL methods. Given the emerging threat of backdoor attacks designed for SSL, this work aims to protect SSL against such risks, marking it as one of the few known efforts in this area. Specifically, we begin by identifying that the spurious correlations between the backdoor triggers and the target class implanted by adversaries are the primary cause of manipulated model predictions during the test phase. To disrupt these correlations, we utilize three key techniques: Gaussian Filter, complementary learning and trigger mix-up, which collectively filter, obstruct and dilute the influence of backdoor attacks in both data pre-processing and feature learning. Experimental results demonstrate that our proposed method, Backdoor Invalidator (BI), significantly reduces the average attack success rate from 84.7\% to 1.8\% across different state-of-the-art backdoor attacks. It is also worth mentioning that BI does not sacrifice accuracy on clean data and is supported by a theoretical guarantee of its generalization capability.
Forgetting, Ignorance or Myopia: Revisiting Key Challenges in Online Continual Learning
Sep 28, 2024Online continual learning requires the models to learn from constant, endless streams of data. While significant efforts have been made in this field, most were focused on mitigating the catastrophic forgetting issue to achieve better classification ability, at the cost of a much heavier training workload. They overlooked that in real-world scenarios, e.g., in high-speed data stream environments, data do not pause to accommodate slow models. In this paper, we emphasize that model throughput -- defined as the maximum number of training samples that a model can process within a unit of time -- is equally important. It directly limits how much data a model can utilize and presents a challenging dilemma for current methods. With this understanding, we revisit key challenges in OCL from both empirical and theoretical perspectives, highlighting two critical issues beyond the well-documented catastrophic forgetting: Model's ignorance: the single-pass nature of OCL challenges models to learn effective features within constrained training time and storage capacity, leading to a trade-off between effective learning and model throughput; Model's myopia: the local learning nature of OCL on the current task leads the model to adopt overly simplified, task-specific features and excessively sparse classifier, resulting in the gap between the optimal solution for the current task and the global objective. To tackle these issues, we propose the Non-sparse Classifier Evolution framework (NsCE) to facilitate effective global discriminative feature learning with minimal time cost. NsCE integrates non-sparse maximum separation regularization and targeted experience replay techniques with the help of pre-trained models, enabling rapid acquisition of new globally discriminative features.
Beyond Myopia: Learning from Positive and Unlabeled Data through Holistic Predictive Trends
Oct 06, 2023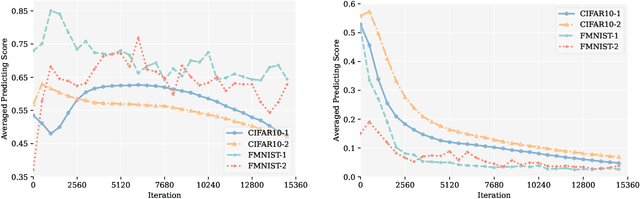


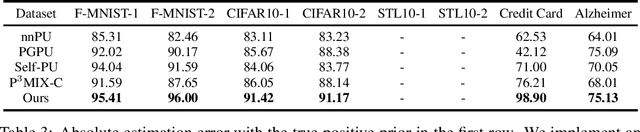
Learning binary classifiers from positive and unlabeled data (PUL) is vital in many real-world applications, especially when verifying negative examples is difficult. Despite the impressive empirical performance of recent PUL methods, challenges like accumulated errors and increased estimation bias persist due to the absence of negative labels. In this paper, we unveil an intriguing yet long-overlooked observation in PUL: \textit{resampling the positive data in each training iteration to ensure a balanced distribution between positive and unlabeled examples results in strong early-stage performance. Furthermore, predictive trends for positive and negative classes display distinctly different patterns.} Specifically, the scores (output probability) of unlabeled negative examples consistently decrease, while those of unlabeled positive examples show largely chaotic trends. Instead of focusing on classification within individual time frames, we innovatively adopt a holistic approach, interpreting the scores of each example as a temporal point process (TPP). This reformulates the core problem of PUL as recognizing trends in these scores. We then propose a novel TPP-inspired measure for trend detection and prove its asymptotic unbiasedness in predicting changes. Notably, our method accomplishes PUL without requiring additional parameter tuning or prior assumptions, offering an alternative perspective for tackling this problem. Extensive experiments verify the superiority of our method, particularly in a highly imbalanced real-world setting, where it achieves improvements of up to $11.3\%$ in key metrics. The code is available at \href{https://github.com/wxr99/HolisticPU}{https://github.com/wxr99/HolisticPU}.
* 25 pages
Unlocking the Power of Open Set : A New Perspective for Open-set Noisy Label Learning
May 07, 2023
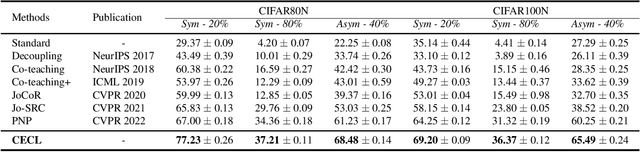
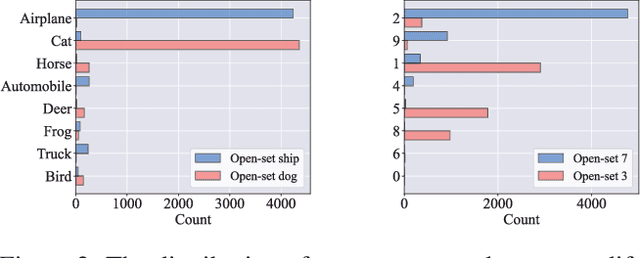
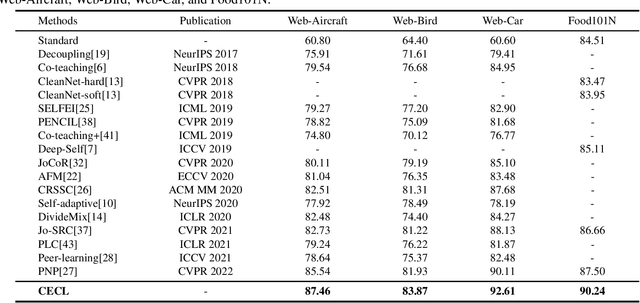
Learning from noisy data has attracted much attention, where most methods focus on closed-set label noise. However, a more common scenario in the real world is the presence of both open-set and closed-set noise. Existing methods typically identify and handle these two types of label noise separately by designing a specific strategy for each type. However, in many real-world scenarios, it would be challenging to identify open-set examples, especially when the dataset has been severely corrupted. Unlike the previous works, we explore how models behave when faced open-set examples, and find that a part of open-set examples gradually get integrated into certain known classes, which is beneficial for the seperation among known classes. Motivated by the phenomenon, in this paper, we propose a novel two-step contrastive learning method called CECL, which aims to deal with both types of label noise by exploiting the useful information of open-set examples. Specifically, we incorporate some open-set examples into closed-set classes to enhance performance while treating others as delimiters to improve representative ability. Extensive experiments on synthetic and real-world datasets with diverse label noise demonstrate that CECL can outperform state-of-the-art methods.