 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training
Feb 12, 2026Supervised fine-tuning (SFT) is computationally efficient but often yields inferior generalization compared to reinforcement learning (RL). This gap is primarily driven by RL's use of on-policy data. We propose a framework to bridge this chasm by enabling On-Policy SFT. We first present \textbf{\textit{Distribution Discriminant Theory (DDT)}}, which explains and quantifies the alignment between data and the model-induced distribution. Leveraging DDT, we introduce two complementary techniques: (i) \textbf{\textit{In-Distribution Finetuning (IDFT)}}, a loss-level method to enhance generalization ability of SFT, and (ii) \textbf{\textit{Hinted Decoding}}, a data-level technique that can re-align the training corpus to the model's distribution. Extensive experiments demonstrate that our framework achieves generalization performance on par with prominent offline RL algorithms, including DPO and SimPO, while maintaining the efficiency of an SFT pipeline. The proposed framework thus offers a practical alternative in domains where RL is infeasible. We open-source the code here: https://github.com/zhangmiaosen2000/Towards-On-Policy-SFT
STHFL: Spatio-Temporal Heterogeneous Federated Learning
Jan 10, 2025Federated learning is a new framework that protects data privacy and allows multiple devices to cooperate in training machine learning models. Previous studies have proposed multiple approaches to eliminate the challenges posed by non-iid data and inter-domain heterogeneity issues. However, they ignore the \textbf{spatio-temporal} heterogeneity formed by different data distributions of increasing task data in the intra-domain. Moreover, the global data is generally a long-tailed distribution rather than assuming the global data is balanced in practical applications. To tackle the \textbf{spatio-temporal} dilemma, we propose a novel setting named \textbf{Spatio-Temporal Heterogeneity} Federated Learning (STHFL). Specially, the Global-Local Dynamic Prototype (GLDP) framework is designed for STHFL. In GLDP, the model in each client contains personalized layers which can dynamically adapt to different data distributions. For long-tailed data distribution, global prototypes are served as complementary knowledge for the training on classes with few samples in clients without leaking privacy. As tasks increase in clients, the knowledge of local prototypes generated in previous tasks guides for training in the current task to solve catastrophic forgetting. Meanwhile, the global-local prototypes are updated through the moving average method after training local prototypes in clients. Finally, we evaluate the effectiveness of GLDP, which achieves remarkable results compared to state-of-the-art methods in STHFL scenarios.
Addressing Skewed Heterogeneity via Federated Prototype Rectification with Personalization
Aug 15, 2024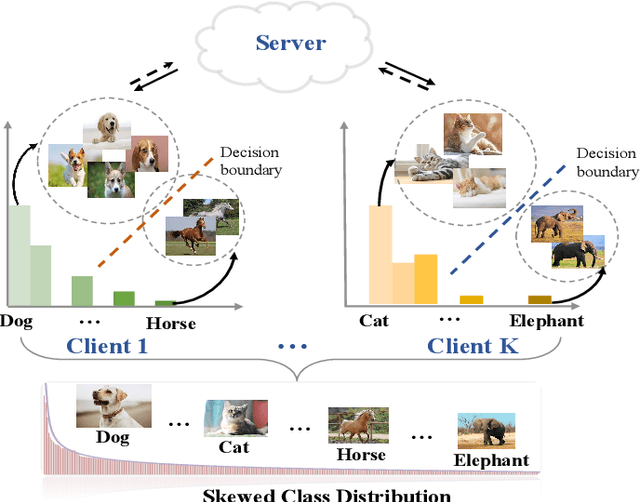
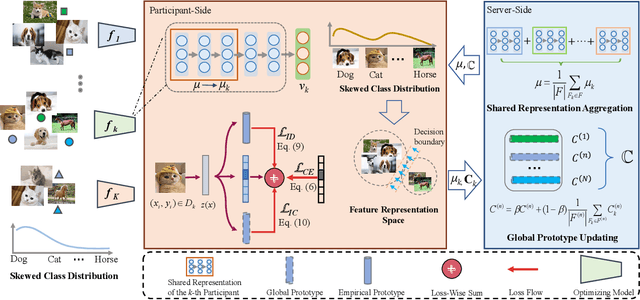

Federated learning is an efficient framework designed to facilitate collaborative model training across multiple distributed devices while preserving user data privacy. A significant challenge of federated learning is data-level heterogeneity, i.e., skewed or long-tailed distribution of private data. Although various methods have been proposed to address this challenge, most of them assume that the underlying global data is uniformly distributed across all clients. This paper investigates data-level heterogeneity federated learning with a brief review and redefines a more practical and challenging setting called Skewed Heterogeneous Federated Learning (SHFL). Accordingly, we propose a novel Federated Prototype Rectification with Personalization which consists of two parts: Federated Personalization and Federated Prototype Rectification. The former aims to construct balanced decision boundaries between dominant and minority classes based on private data, while the latter exploits both inter-class discrimination and intra-class consistency to rectify empirical prototypes. Experiments on three popular benchmarks show that the proposed approach outperforms current state-of-the-art methods and achieves balanced performance in both personalization and generalization.
Learngene: Inheriting Condensed Knowledge from the Ancestry Model to Descendant Models
May 03, 2023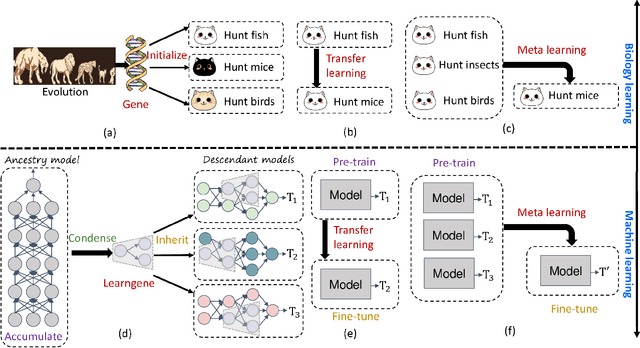

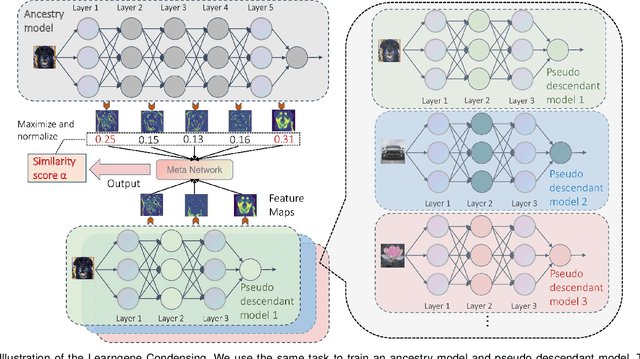
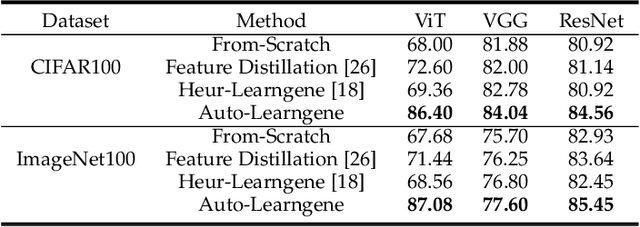
During the continuous evolution of one organism's ancestry, its genes accumulate extensive experiences and knowledge, enabling newborn descendants to rapidly adapt to their specific environments. Motivated by this observation, we propose a novel machine learning paradigm \textit{Learngene} to enable learning models to incorporate three key characteristics of genes. (i) Accumulating: the knowledge is accumulated during the continuous learning of an \textbf{ancestry model}. (ii) Condensing: the exhaustive accumulated knowledge is condensed into a much more compact information piece, \ie \textbf{learngene}. (iii): Inheriting: the condensed \textbf{learngene} is inherited to make it easier for \textbf{descendant models} to adapt to new environments. Since accumulating has been studied in some well-developed paradigms like large-scale pre-training and lifelong learning, we focus on condensing and inheriting, which induces three key issues and we provide the preliminary solutions to these issues in this paper: (i) \textit{Learngene} Form: the \textbf{learngene} is set to a few integral layers that can preserve the most commonality. (ii) \textit{Learngene} Condensing: we identify which layers among the ancestry model have the most similarity as one pseudo descendant model. (iii) \textit{Learngene} Inheriting: to construct distinct descendant models for specific downstream tasks, we stack some randomly initialized layers to the \textbf{learngene} layers. Extensive experiments of various settings, including using different network architectures like Vision Transformer (ViT) and Convolutional Neural Networks (CNNs) on different datasets, are carried out to confirm five advantages and two characteristics of \textit{Learngene}.
Learngene: From Open-World to Your Learning Task
Jun 12, 2021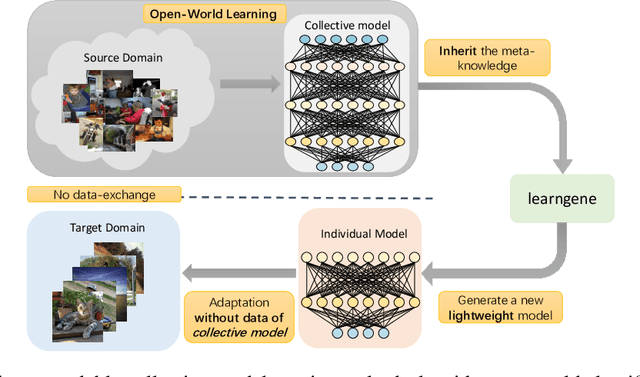

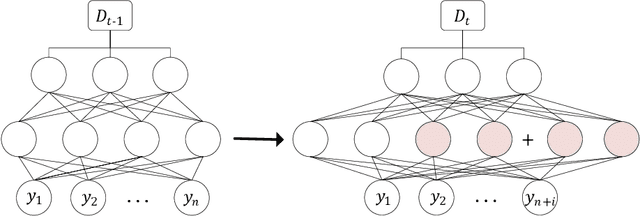
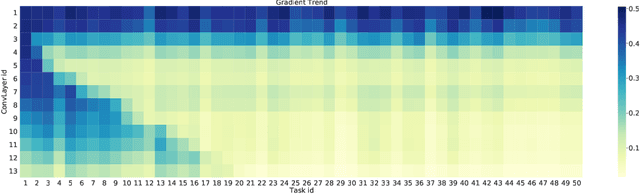
Although deep learning has made significant progress on fixed large-scale datasets, it typically encounters challenges regarding improperly detecting new/unseen classes in the open-world classification, over-parametrized, and overfitting small samples. In contrast, biological systems can overcome the above difficulties very well. Individuals inherit an innate gene from collective creatures that have evolved over hundreds of millions of years, and can learn new skills through a few examples. Inspired by this, we propose a practical collective-individual paradigm where open-world tasks are trained in sequence using an evolution (expandable) network. To be specific, we innovatively introduce learngene that inherits the meta-knowledge from the collective model and reconstructs a new lightweight individual model for the target task, to realize the collective-individual paradigm. Particularly, we present a novel criterion that can discover the learngene in the collective model, according to the gradient information. Finally, the individual model is trained only with a few samples in the absence of the source data. We demonstrate the effectiveness of our approach in an extensive empirical study and theoretical analysis.