 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Skewed Heterogeneity via Federated Prototype Rectification with Personalization
Paper and Code
Aug 15, 2024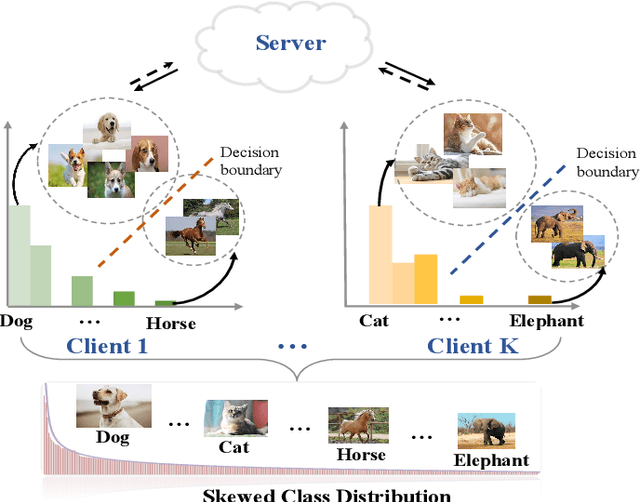
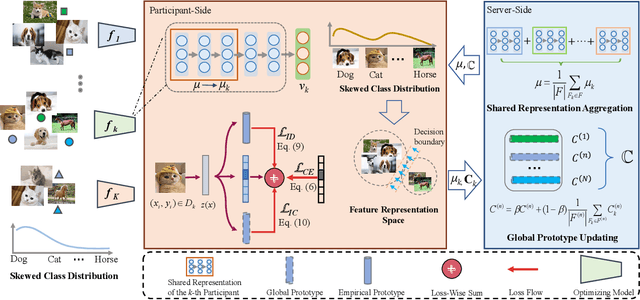

Federated learning is an efficient framework designed to facilitate collaborative model training across multiple distributed devices while preserving user data privacy. A significant challenge of federated learning is data-level heterogeneity, i.e., skewed or long-tailed distribution of private data. Although various methods have been proposed to address this challenge, most of them assume that the underlying global data is uniformly distributed across all clients. This paper investigates data-level heterogeneity federated learning with a brief review and redefines a more practical and challenging setting called Skewed Heterogeneous Federated Learning (SHFL). Accordingly, we propose a novel Federated Prototype Rectification with Personalization which consists of two parts: Federated Personalization and Federated Prototype Rectification. The former aims to construct balanced decision boundaries between dominant and minority classes based on private data, while the latter exploits both inter-class discrimination and intra-class consistency to rectify empirical prototypes. Experiments on three popular benchmarks show that the proposed approach outperforms current state-of-the-art methods and achieves balanced performance in both personalization and generalization.