 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitosis Detection in the Wild: Multi-Tumor and Context-Aware Generalization in the MIDOG 2025 Challenge
Jun 05, 2026Automated mitosis detection is a well-established task in computational pathology. While previous benchmarks focused on scanner-induced domain shift, clinical "real-world" application requires models to be robust across the vast variance to be expected in the histological landscape. The MItosis DOmain Generalization (MIDOG) 2025 challenge was designed to evaluate algorithmic performance across unprecedented biological and contextual diversity. We curated a test dataset of 365 cases, encompassing 12 distinct human, canine and feline tumor types, digitized across multiple scanning platforms. Moving beyond hand-selected hotspots, the challenge required detection also in random tissue areas (representative of the whole slide detection situation) and challenging areas (areas rich in hard negatives). In the second track, we introduced the classification of atypical mitotic figures (AMFs). There were 18 teams submitting to the detection track, with F1 scores ranging up to 0.740. In the AMF detection track, we had 21 submissions with balanced accuracy values up to 0.908. Our analysis reveals that while most models perform reliably in traditional hotspots, significant performance degradation occurs in challenging ROIs, where false positive rates tripled. Furthermore, performance varied significantly across the 12 tumor types, highlighting "blind spots" in current state-of-the-art architectures when encountering rare or highly pleomorphic malignancies. Moreover, we evaluated the effectiveness of ensembling and found a mean increases of 1.5 and 1.3 percentage points in F1 score and balanced accuracy, respectively. In contrast, TTA showed no relevant improvement. MIDOG 2025 demonstrates that "in the wild" mitosis detection remains a significant hurdle. The transition from hotspot-only evaluation to a multi-contextual framework provides a more realistic proxy for clinical reliability.
A deep learning framework for glomeruli segmentation with boundary attention
Apr 15, 2026Accurate detection and segmentation of glomeruli in kidney tissue are essential for diagnostic applications. Traditional deep learning methods primarily rely on semantic segmentation, which often fails to precisely delineate adjacent glomeruli. To address this challenge, we propose a novel glomerulus detection and segmentation model that emphasises boundary separation. Leveraging pathology foundation models, the proposed U-Net-based architecture incorporates a specialised attention decoder designed to highlight critical regions and improve instancelevel segmentation. Experimental evaluations demonstrate that our approach surpasses state-of-the-art methods in both Dice score and Intersection over Union, indicating superior performance in glomerular delineation.
Graph Negative Feedback Bias Correction Framework for Adaptive Heterophily Modeling
Mar 04, 2026Graph Neural Networks (GNNs) have emerged as a powerful framework for processing graph-structured data. However, conventional GNNs and their variants are inherently limited by the homophily assumption, leading to degradation in performance on heterophilic graphs. Although substantial efforts have been made to mitigate this issue, they remain constrained by the message-passing paradigm, which is inherently rooted in homophily. In this paper, a detailed analysis of how the underlying label autocorrelation of the homophily assumption introduces bias into GNNs is presented. We innovatively leverage a negative feedback mechanism to correct the bias and propose Graph Negative Feedback Bias Correction (GNFBC), a simple yet effective framework that is independent of any specific aggregation strategy. Specifically, we introduce a negative feedback loss that penalizes the sensitivity of predictions to label autocorrelation. Furthermore, we incorporate the output of graph-agnostic models as a feedback term, leveraging independent node feature information to counteract correlation-induced bias guided by Dirichlet energy. GNFBC can be seamlessly integrated into existing GNN architectures, improving overall performance with comparable computational and memory overhead.
Multi-Scale Adaptive Neighborhood Awareness Transformer For Graph Fraud Detection
Mar 03, 2026Graph fraud detection (GFD) is crucial for identifying fraudulent behavior within graphs, benefiting various domains such as financial networks and social media. Existing methods based on graph neural networks (GNNs) have succeeded considerably due to their effective expressive capacity for graph-structured data. However, the inherent inductive bias of GNNs, including the homogeneity assumption and the limited global modeling ability, hinder the effectiveness of these models. To address these challenges, we propose Multi-scale Neighborhood Awareness Transformer (MANDATE), which alleviates the inherent inductive bias of GNNs. Specifically, we design a multi-scale positional encoding strategy to encode the positional information of various distances from the central node. By incorporating it with the self-attention mechanism, the global modeling ability can be enhanced significantly. Meanwhile, we design different embedding strategies for homophilic and heterophilic connections. This mitigates the homophily distribution differences between benign and fraudulent nodes. Moreover, an embedding fusion strategy is designed for multi-relation graphs, which alleviates the distribution bias caused by different relationships. Experiments on three fraud detection datasets demonstrate the superiority of MANDATE.
MultiSurv: A Multimodal Deep Survival Framework for Prostrate and Bladder Cancer
Sep 05, 2025Accurate prediction of time-to-event outcomes is a central challenge in oncology, with significant implications for treatment planning and patient management. In this work, we present MultiSurv, a multimodal deep survival model utilising DeepHit with a projection layer and inter-modality cross-attention, which integrates heterogeneous patient data, including clinical, MRI, RNA-seq and whole-slide pathology features. The model is designed to capture complementary prognostic signals across modalities and estimate individualised time-to-biochemical recurrence in prostate cancer and time-to-cancer recurrence in bladder cancer. Our approach was evaluated in the context of the CHIMERA Grand Challenge, across two of the three provided tasks. For Task 1 (prostate cancer bio-chemical recurrence prediction), the proposed framework achieved a concordance index (C-index) of 0.843 on 5-folds cross-validation and 0.818 on CHIMERA development set, demonstrating robust discriminatory ability. For Task 3 (bladder cancer recurrence prediction), the model obtained a C-index of 0.662 on 5-folds cross-validation and 0.457 on development set, highlighting its adaptability and potential for clinical translation. These results suggest that leveraging multimodal integration with deep survival learning provides a promising pathway toward personalised risk stratification in prostate and bladder cancer. Beyond the challenge setting, our framework is broadly applicable to survival prediction tasks involving heterogeneous biomedical data.
HPCTransCompile: An AI Compiler Generated Dataset for High-Performance CUDA Transpilation and LLM Preliminary Exploration
Jun 12, 2025The rapid growth of deep learning has driven exponential increases in model parameters and computational demands. NVIDIA GPUs and their CUDA-based software ecosystem provide robust support for parallel computing, significantly alleviating computational bottlenecks. Meanwhile, due to the cultivation of user programming habits and the high performance of GPUs, the CUDA ecosystem has established a dominant position in the field of parallel software. This dominance requires other hardware platforms to support CUDA-based software with performance portability. However, translating CUDA code to other platforms poses significant challenges due to differences in parallel programming paradigms and hardware architectures. Existing approaches rely on language extensions, domain-specific languages (DSLs), or compilers but face limitations in workload coverage and generalizability. Moreover, these methods often incur substantial development costs. Recently, LLMs have demonstrated extraordinary potential in various vertical domains, especially in code-related tasks. However, the performance of existing LLMs in CUDA transpilation, particularly for high-performance code, remains suboptimal. The main reason for this limitation lies in the lack of high-quality training datasets. To address these challenges, we propose a novel framework for generating high-performance CUDA and corresponding platform code pairs, leveraging AI compiler and automatic optimization technology. We further enhance the framework with a graph-based data augmentation method and introduce HPCTransEval, a benchmark for evaluating LLM performance on CUDA transpilation. We conduct experiments using CUDA-to-CPU transpilation as a case study on leading LLMs. The result demonstrates that our framework significantly improves CUDA transpilation, highlighting the potential of LLMs to address compatibility challenges within the CUDA ecosystem.
GENE-FL: Gene-Driven Parameter-Efficient Dynamic Federated Learning
Apr 20, 2025Real-world \underline{F}ederated \underline{L}earning systems often encounter \underline{D}ynamic clients with \underline{A}gnostic and highly heterogeneous data distributions (DAFL), which pose challenges for efficient communication and model initialization. To address these challenges, we draw inspiration from the recently proposed Learngene paradigm, which compresses the large-scale model into lightweight, cross-task meta-information fragments. Learngene effectively encapsulates and communicates core knowledge, making it particularly well-suited for DAFL, where dynamic client participation requires communication efficiency and rapid adaptation to new data distributions. Based on this insight, we propose a Gene-driven parameter-efficient dynamic Federated Learning (GENE-FL) framework. First, local models perform quadratic constraints based on parameters with high Fisher values in the global model, as these parameters are considered to encapsulate generalizable knowledge. Second, we apply the strategy of parameter sensitivity analysis in local model parameters to condense the \textit{learnGene} for interaction. Finally, the server aggregates these small-scale trained \textit{learnGene}s into a robust \textit{learnGene} with cross-task generalization capability, facilitating the rapid initialization of dynamic agnostic client models. Extensive experimental results demonstrate that GENE-FL reduces \textbf{4 $\times$} communication costs compared to FEDAVG and effectively initializes agnostic client models with only about \textbf{9.04} MB.
FedEPA: Enhancing Personalization and Modality Alignment in Multimodal Federated Learning
Apr 16, 2025Federated Learning (FL) enables decentralized model training across multiple parties while preserving privacy. However, most FL systems assume clients hold only unimodal data, limiting their real-world applicability, as institutions often possess multimodal data. Moreover, the lack of labeled data further constrains the performance of most FL methods. In this work, we propose FedEPA, a novel FL framework for multimodal learning. FedEPA employs a personalized local model aggregation strategy that leverages labeled data on clients to learn personalized aggregation weights, thereby alleviating the impact of data heterogeneity. We also propose an unsupervised modality alignment strategy that works effectively with limited labeled data. Specifically, we decompose multimodal features into aligned features and context features. We then employ contrastive learning to align the aligned features across modalities, ensure the independence between aligned features and context features within each modality, and promote the diversity of context features. A multimodal feature fusion strategy is introduced to obtain a joint embedding. The experimental results show that FedEPA significantly outperforms existing FL methods in multimodal classification tasks under limited labeled data conditions.
Deep Learning Based Segmentation of Blood Vessels from H&E Stained Oesophageal Adenocarcinoma Whole-Slide Images
Jan 21, 2025Blood vessels (BVs) play a critical role in the Tumor Micro-Environment (TME), potentially influencing cancer progression and treatment response. However, manually quantifying BVs in Hematoxylin and Eosin (H&E) stained images is challenging and labor-intensive due to their heterogeneous appearances. We propose a novel approach of constructing guiding maps to improve the performance of state-of-the-art segmentation models for BV segmentation, the guiding maps encourage the models to learn representative features of BVs. This is particularly beneficial for computational pathology, where labeled training data is often limited and large models are prone to overfitting. We have quantitative and qualitative results to demonstrate the efficacy of our approach in improving segmentation accuracy. In future, we plan to validate this method to segment BVs across various tissue types and investigate the role of cellular structures in relation to BVs in the TME.
Towards Effective Visual Representations for Partial-Label Learning
May 10, 2023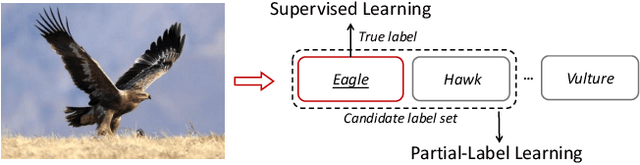
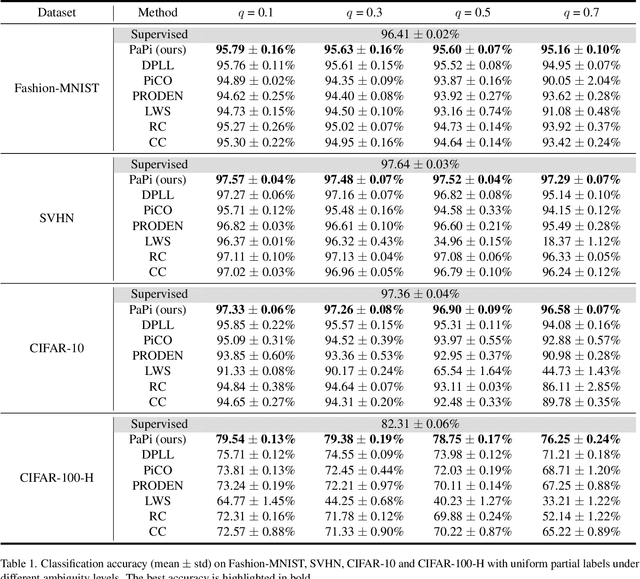
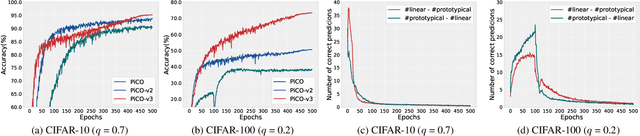
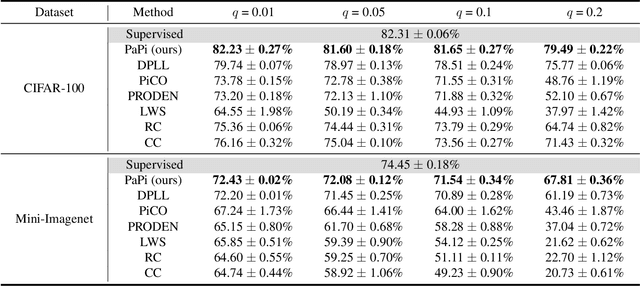
Under partial-label learning (PLL) where, for each training instance, only a set of ambiguous candidate labels containing the unknown true label is accessible, contrastive learning has recently boosted the performance of PLL on vision tasks, attributed to representations learned by contrasting the same/different classes of entities. Without access to true labels, positive points are predicted using pseudo-labels that are inherently noisy, and negative points often require large batches or momentum encoders, resulting in unreliable similarity information and a high computational overhead. In this paper, we rethink a state-of-the-art contrastive PLL method PiCO[24], inspiring the design of a simple framework termed PaPi (Partial-label learning with a guided Prototypical classifier), which demonstrates significant scope for improvement in representation learning, thus contributing to label disambiguation. PaPi guides the optimization of a prototypical classifier by a linear classifier with which they share the same feature encoder, thus explicitly encouraging the representation to reflect visual similarity between categories. It is also technically appealing, as PaPi requires only a few components in PiCO with the opposite direction of guidance, and directly eliminates the contrastive learning module that would introduce noise and consume computational resources. We empirically demonstrate that PaPi significantly outperforms other PLL methods on various image classification tasks.