 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Native Multimodal Modeling: A Roadmap
May 25, 2026Multimodal modeling represents a vital step from modality-agnostic reasoning toward world modeling. While early approaches predominantly rely on late-fusion that assembles encoders and frozen language backbones with output heads, recent efforts have shifted the paradigm toward native multimodal modeling (NMM) with the intrinsic integration of modalities for superior multimodal performance. Despite its potential, the design space of native architectures remains insufficiently defined. In this paper, we present the community with a formalized roadmap for this transition. Specifically, we formally define the architectural nativity, distinguishing mid-fusion and early-fusion from non-native paradigms. We further organize the existing native models through the lens of input-output duality into three categories: (i) Multi-to-Text for cross-modal comprehension with text-only output; (ii) Multi-to-Target for scenario-oriented generation, e.g., image, audio and video generation, and (iii) Multi-to-Multi for unified modeling with symmetric input-output. We deliver a comprehensive and industrial-grade investigation into the transition toward the definitive NMM framework, where understanding and generation seamlessly coexist within a unified transformer paradigm. We systematically unpack the end-to-end pipeline from industrial perspectives from architectural coordination, massive data curation, to full-stack training recipes, inference & deployment, and the comprehensive evaluation for truly native modeling.
Trustworthy Federated Label Distribution Learning under Annotation Quality Disparity
May 06, 2026Label Distribution Learning (LDL) models supervision as an instance-wise probability distribution, enabling fine-grained learning under inherent ambiguity, but its success relies on high-fidelity label distributions that are costly to obtain and thus often noisy. Motivated by privacy-sensitive applications, we study Federated Label Distribution Learning (Fed-LDL), where data isolation further induces heterogeneous annotation quality across clients, making local updates unevenly reliable and breaking sample-size-based aggregation (e.g., FedAvg). To address this trust dilemma, we propose FedQual, a quality-aware Fed-LDL framework with two coupled mechanisms: (i) quality-adaptive client training guided by a global semantic anchor that calibrates low-quality clients while preserving high-quality autonomy, and (ii) reliability-aware server aggregation that reweights client contributions by effective reliable information rather than raw sample size. To enable rigorous evaluation, we construct four new Fed-LDL benchmarks (FER-LDL, FI-LDL, PIPAL-LDL, and KADID-LDL) with controlled annotation quality disparity. We further provide a theoretical guarantee showing that under heterogeneous supervision quality, client-specific calibration is strictly better than any uniform calibration. Extensive experiments on the proposed benchmarks demonstrate the effectiveness of FedQual.
Meta-Aligner: Bidirectional Preference-Policy Optimization for Multi-Objective LLMs Alignment
Apr 27, 2026Multi-Objective Alignment aims to align Large Language Models (LLMs) with diverse and often conflicting human values by optimizing multiple objectives simultaneously. Existing methods predominantly rely on static preference weight construction strategies. However, rigidly aligning to fixed targets discards valuable intermediate information, as training responses inherently embody valid preference trade-offs even when deviating from the target. To address this limitation, we propose Meal, i.e., MEta ALigner, a bi-level meta-learning framework enabling bidirectional optimization between preferences and policy responses, generating instructive dynamic preferences for steadier training. Specifically, we introduce a preference-weight-net as a meta-learner to generate adaptive preference weights based on input prompts and update the preference weights as learnable parameters, while the LLM policy acts as a base-learner optimizing response generation conditioned on these preferences with rejection sampling strategy. Extensive empirical results demonstrate that our method achieves superior performance on several multi-objective benchmarks, validating the effectiveness of the dynamic bidirectional preference-policy optimization framework.
Seed2Scale: A Self-Evolving Data Engine for Embodied AI via Small to Large Model Synergy and Multimodal Evaluation
Mar 09, 2026Existing data generation methods suffer from exploration limits, embodiment gaps, and low signal-to-noise ratios, leading to performance degradation during self-iteration. To address these challenges, we propose Seed2Scale, a self-evolving data engine that overcomes the data bottleneck through a heterogeneous synergy of "small-model collection, large-model evaluation, and target-model learning". Starting with as few as four seed demonstrations, the engine employs the lightweight Vision-Language-Action model, SuperTiny, as a dedicated collector, leveraging its strong inductive bias for robust exploration in parallel environments. Concurrently, a pre-trained Vision-Language Model is integrated as a Verifer to autonomously perform success/failure judgment and quality scoring for the massive generated trajectories. Seed2Scale effectively mitigates model collapse, ensuring the stability of the self-evolution process. Experimental results demonstrate that Seed2Scale exhibits signifcant scaling potential: as iterations progress, the success rate of the target model shows a robust upward trend, achieving a performance improvement of 131.2%. Furthermore, Seed2Scale signifcantly outperforms existing data augmentation methods, providing a scalable and cost-effective pathway for the large-scale development of Generalist Embodied AI. Project page: https://terminators2025.github.io/Seed2Scale.github.io
VRM: Teaching Reward Models to Understand Authentic Human Preferences
Mar 05, 2026Large Language Models (LLMs) have achieved remarkable success across diverse natural language tasks, yet the reward models employed for aligning LLMs often encounter challenges of reward hacking, where the approaches predominantly rely on directly mapping prompt-response pairs to scalar scores, which may inadvertently capture spurious correlations rather than authentic human preferences. In contrast, human evaluation employs a sophisticated process that initially weighs the relative importance of multiple high-dimensional objectives according to the prompt context, subsequently evaluating response quality through low-dimensional semantic features such as logical coherence and contextual appropriateness. Motivated by this consideration, we propose VRM, i.e., Variational Reward Modeling, a novel framework that explicitly models the evaluation process of human preference judgments by incorporating both high-dimensional objective weights and low-dimensional semantic features as latent variables, which are inferred through variational inference techniques. Additionally, we provide a theoretical analysis showing that VRM can achieve a tighter generalization error bound compared to the traditional reward model. Extensive experiments on benchmark datasets demonstrate that VRM significantly outperforms existing methods in capturing authentic human preferences.
Positive-Unlabeled Reinforcement Learning Distillation for On-Premise Small Models
Jan 28, 2026Due to constraints on privacy, cost, and latency, on-premise deployment of small models is increasingly common. However, most practical pipelines stop at supervised fine-tuning (SFT) and fail to reach the reinforcement learning (RL) alignment stage. The main reason is that RL alignment typically requires either expensive human preference annotation or heavy reliance on high-quality reward models with large-scale API usage and ongoing engineering maintenance, both of which are ill-suited to on-premise settings. To bridge this gap, we propose a positive-unlabeled (PU) RL distillation method for on-premise small-model deployment. Without human-labeled preferences or a reward model, our method distills the teacher's preference-optimization capability from black-box generations into a locally trainable student. For each prompt, we query the teacher once to obtain an anchor response, locally sample multiple student candidates, and perform anchor-conditioned self-ranking to induce pairwise or listwise preferences, enabling a fully local training loop via direct preference optimization or group relative policy optimization. Theoretical analysis justifies that the induced preference signal by our method is order-consistent and concentrates on near-optimal candidates, supporting its stability for preference optimization. Experiments demonstrate that our method achieves consistently strong performance under a low-cost setting.
SpatialLock: Precise Spatial Control in Text-to-Image Synthesis
Nov 06, 2025
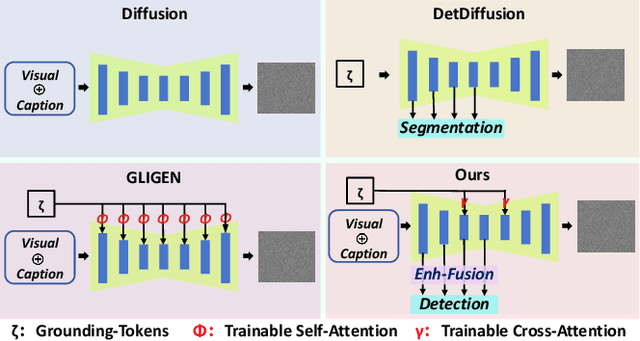


Text-to-Image (T2I) synthesis has made significant advancements in recent years, driving applications such as generating datasets automatically. However, precise control over object localization in generated images remains a challenge. Existing methods fail to fully utilize positional information, leading to an inadequate understanding of object spatial layouts. To address this issue, we propose SpatialLock, a novel framework that leverages perception signals and grounding information to jointly control the generation of spatial locations. SpatialLock incorporates two components: Position-Engaged Injection (PoI) and Position-Guided Learning (PoG). PoI directly integrates spatial information through an attention layer, encouraging the model to learn the grounding information effectively. PoG employs perception-based supervision to further refine object localization. Together, these components enable the model to generate objects with precise spatial arrangements and improve the visual quality of the generated images. Experiments show that SpatialLock sets a new state-of-the-art for precise object positioning, achieving IOU scores above 0.9 across multiple datasets.
PLPP: Prompt Learning with Perplexity Is Self-Distillation for Vision-Language Models
Dec 18, 2024Pre-trained Vision-Language (VL) models such as CLIP have demonstrated their excellent performance across numerous downstream tasks. A recent method, Context Optimization (CoOp), further improves the performance of VL models on downstream tasks by introducing prompt learning. CoOp optimizes a set of learnable vectors, aka prompt, and freezes the whole CLIP model. However, relying solely on CLIP loss to fine-tune prompts can lead to models that are prone to overfitting on downstream task. To address this issue, we propose a plug-in prompt-regularization method called PLPP (Prompt Learning with PerPlexity), which use perplexity loss to regularize prompt learning. PLPP designs a two-step operation to compute the perplexity for prompts: (a) calculating cosine similarity between the weight of the embedding layer and prompts to get labels, (b) introducing a language model (LM) head that requires no training behind text encoder to output word probability distribution. Meanwhile, we unveil that the essence of PLPP is inherently a form of self-distillation. To further prevent overfitting as well as to reduce the additional computation introduced by PLPP, we turn the hard label to soft label and choose top-$k$ values for calculating the perplexity loss. For accelerating model convergence, we introduce mutual self-distillation learning, that is perplexity and inverted perplexity loss. The experiments conducted on four classification tasks indicate that PLPP exhibits superior performance compared to existing methods.
Negative-Prompt-driven Alignment for Generative Language Model
Oct 16, 2024Large language models have achieved remarkable capabilities, but aligning their outputs with human values and preferences remains a significant challenge. Existing alignment methods primarily focus on positive examples while overlooking the importance of negative responses in guiding models away from undesirable behaviors. For instance, the widely-used alignment datasets reveals a scarcity of explicit negative examples that contradict human values, hindering its ability to discourage harmful or biased outputs during training. To address this limitation, we propose NEAT, i.e., NEgative-prompt-driven AlignmenT, to introduce negative prompts to generate undesirable responses alongside positive examples during the optimization process. NEAT explicitly penalizes the model for producing harmful outputs, guiding it not only toward desirable behaviors but also steering it away from generating undesirable, biased responses. This dual feedback mechanism enables better alignment with human preferences, crucial in contexts where avoiding harm is paramount. Starting from a pre-trained language model, NEAT performs online alignment by incorporating a ranking loss derived from an expanded preference dataset containing both positive and negative examples. Extensive experiments validate NEAT's effectiveness in significantly enhancing language models' alignment with human values and preferences.
Progressively Selective Label Enhancement for Language Model Alignment
Aug 05, 2024Large Language Models have demonstrated impressive capabilities in various language tasks but may produce content that misaligns with human expectations, raising ethical and legal concerns. Therefore, it is important to explore the limitations and implement restrictions on the models to ensure safety and compliance, with Reinforcement Learning from Human Feedback (RLHF) being the primary method. Due to challenges in stability and scalability with the RLHF stages, researchers are exploring alternative methods to achieve effects comparable to those of RLHF. However, these methods often depend on large high-quality datasets and inefficiently utilize generated data. To deal with this problem, we propose PSLE, i.e., Progressively Selective Label Enhancement for Language Model Alignment, a framework that fully utilizes all generated data by guiding the model with principles to align outputs with human expectations. Using a dynamically updated threshold, our approach ensures efficient data utilization by incorporating all generated responses and weighting them based on their corresponding reward scores. Experimental results on multiple datasets demonstrate the effectiveness of PSLE compared to existing language model alignment methods.