 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduction-based Pseudo-label Generation for Instance-dependent Partial Label Learning
Oct 28, 2024



Instance-dependent Partial Label Learning (ID-PLL) aims to learn a multi-class predictive model given training instances annotated with candidate labels related to features, among which correct labels are hidden fixed but unknown. The previous works involve leveraging the identification capability of the training model itself to iteratively refine supervision information. However, these methods overlook a critical aspect of ID-PLL: the training model is prone to overfitting on incorrect candidate labels, thereby providing poor supervision information and creating a bottleneck in training. In this paper, we propose to leverage reduction-based pseudo-labels to alleviate the influence of incorrect candidate labels and train our predictive model to overcome this bottleneck. Specifically, reduction-based pseudo-labels are generated by performing weighted aggregation on the outputs of a multi-branch auxiliary model, with each branch trained in a label subspace that excludes certain labels. This approach ensures that each branch explicitly avoids the disturbance of the excluded labels, allowing the pseudo-labels provided for instances troubled by these excluded labels to benefit from the unaffected branches. Theoretically, we demonstrate that reduction-based pseudo-labels exhibit greater consistency with the Bayes optimal classifier compared to pseudo-labels directly generated from the predictive model.
Variational Label-Correlation Enhancement for Congestion Prediction
Aug 01, 2023The physical design process of large-scale designs is a time-consuming task, often requiring hours to days to complete, with routing being the most critical and complex step. As the the complexity of Integrated Circuits (ICs) increases, there is an increased demand for accurate routing quality prediction. Accurate congestion prediction aids in identifying design flaws early on, thereby accelerating circuit design and conserving resources. Despite the advancements in current congestion prediction methodologies, an essential aspect that has been largely overlooked is the spatial label-correlation between different grids in congestion prediction. The spatial label-correlation is a fundamental characteristic of circuit design, where the congestion status of a grid is not isolated but inherently influenced by the conditions of its neighboring grids. In order to fully exploit the inherent spatial label-correlation between neighboring grids, we propose a novel approach, {\ours}, i.e., VAriational Label-Correlation Enhancement for Congestion Prediction, which considers the local label-correlation in the congestion map, associating the estimated congestion value of each grid with a local label-correlation weight influenced by its surrounding grids. {\ours} leverages variational inference techniques to estimate this weight, thereby enhancing the regression model's performance by incorporating spatial dependencies. Experiment results validate the superior effectiveness of {\ours} on the public available \texttt{ISPD2011} and \texttt{DAC2012} benchmarks using the superblue circuit line.
Progressive Purification for Instance-Dependent Partial Label Learning
Jun 02, 2022
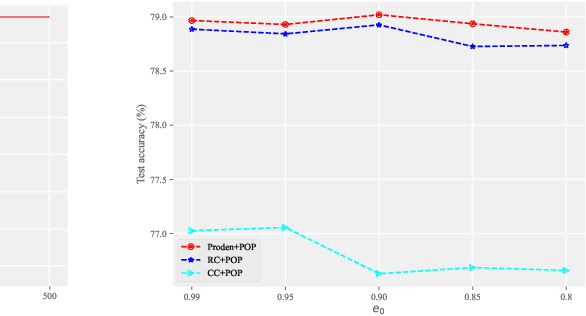
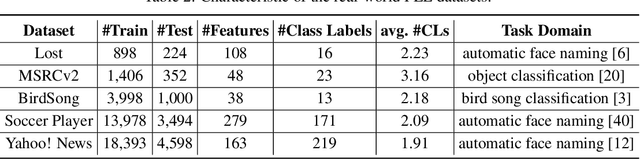
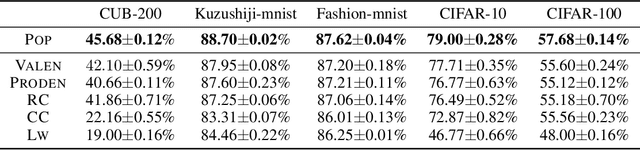
Partial label learning (PLL) aims to train multi-class classifiers from instances with partial labels (PLs)-a PL for an instance is a set of candidate labels where a fixed but unknown candidate is the true label. In the last few years, the instance-independent generation process of PLs has been extensively studied, on the basis of which many practical and theoretical advances have been made in PLL, whereas relatively less attention has been paid to the practical setting of instance-dependent PLs, namely, the PL depends not only on the true label but the instance itself. In this paper, we propose a theoretically grounded and practically effective approach called PrOgressive Purification (POP) for instance-dependent PLL: in each epoch, POP updates the learning model while purifying each PL for the next epoch of the model training by progressively moving out false candidate labels. Theoretically, we prove that POP enlarges the region appropriately fast where the model is reliable, and eventually approximates the Bayes optimal classifier with mild assumptions; technically, POP is flexible with arbitrary losses and compatible with deep networks, so that the previous advanced PLL losses can be embedded in it and the performance is often significantly improved.
One Positive Label is Sufficient: Single-Positive Multi-Label Learning with Label Enhancement
Jun 01, 2022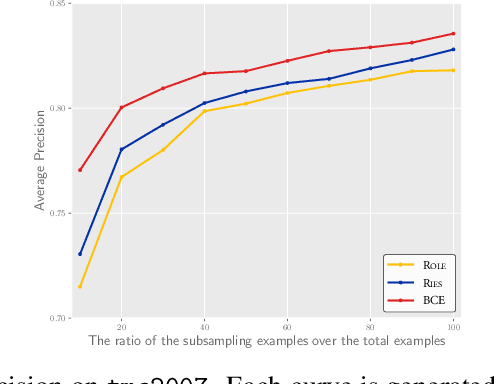
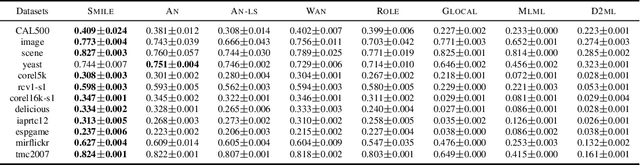
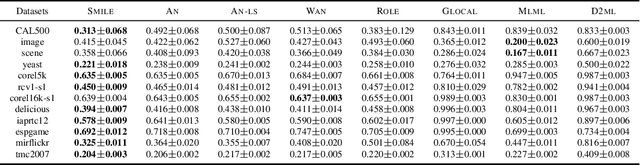

Multi-label learning (MLL) learns from the examples each associated with multiple labels simultaneously, where the high cost of annotating all relevant labels for each training example is challenging for real-world applications. To cope with the challenge, we investigate single-positive multi-label learning (SPMLL) where each example is annotated with only one relevant label and show that one can successfully learn a theoretically grounded multi-label classifier for the problem. In this paper, a novel SPMLL method named {\proposed}, i.e., Single-positive MultI-label learning with Label Enhancement, is proposed. Specifically, an unbiased risk estimator is derived, which could be guaranteed to approximately converge to the optimal risk minimizer of fully supervised learning and shows that one positive label of each instance is sufficient to train the predictive model. Then, the corresponding empirical risk estimator is established via recovering the latent soft label as a label enhancement process, where the posterior density of the latent soft labels is approximate to the variational Beta density parameterized by an inference model. Experiments on benchmark datasets validate the effectiveness of the proposed method.
Decomposition-based Generation Process for Instance-Dependent Partial Label Learning
Apr 08, 2022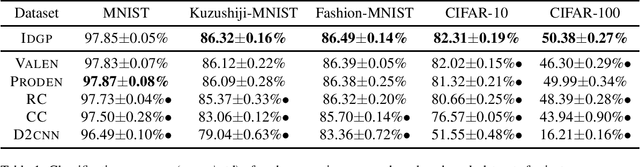

Partial label learning (PLL) is a typical weakly supervised learning problem, where each training example is associated with a set of candidate labels among which only one is true. Most existing PLL approaches assume that the incorrect labels in each training example are randomly picked as the candidate labels and model the generation process of the candidate labels in a simple way. However, these approaches usually do not perform as well as expected due to the fact that the generation process of the candidate labels is always instance-dependent. Therefore, it deserves to be modeled in a refined way. In this paper, we consider instance-dependent PLL and assume that the generation process of the candidate labels could decompose into two sequential parts, where the correct label emerges first in the mind of the annotator but then the incorrect labels related to the feature are also selected with the correct label as candidate labels due to uncertainty of labeling. Motivated by this consideration, we propose a novel PLL method that performs Maximum A Posterior(MAP) based on an explicitly modeled generation process of candidate labels via decomposed probability distribution models. Experiments on benchmark and real-world datasets validate the effectiveness of the proposed method.
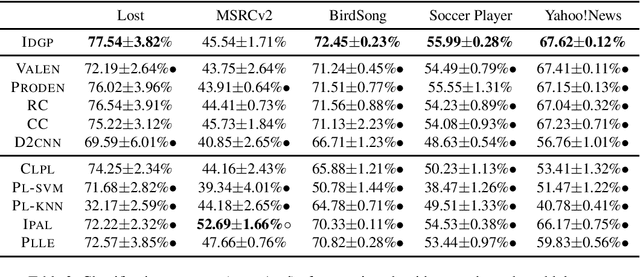
Instance-Dependent Partial Label Learning
Oct 26, 2021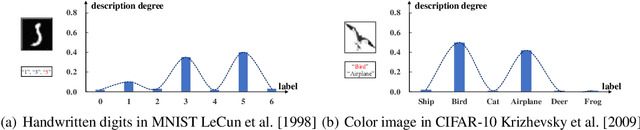
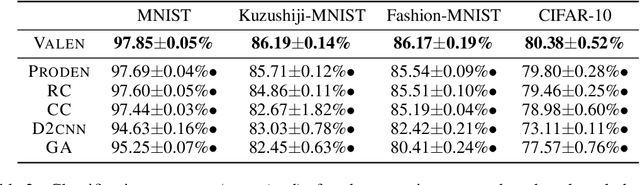
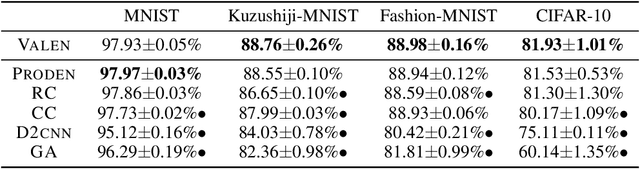
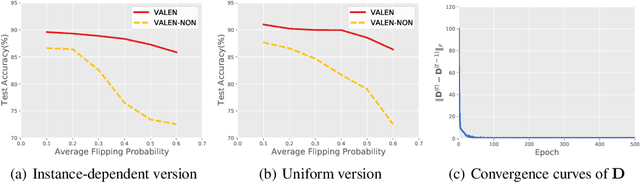
Partial label learning (PLL) is a typical weakly supervised learning problem, where each training example is associated with a set of candidate labels among which only one is true. Most existing PLL approaches assume that the incorrect labels in each training example are randomly picked as the candidate labels. However, this assumption is not realistic since the candidate labels are always instance-dependent. In this paper, we consider instance-dependent PLL and assume that each example is associated with a latent label distribution constituted by the real number of each label, representing the degree to each label describing the feature. The incorrect label with a high degree is more likely to be annotated as the candidate label. Therefore, the latent label distribution is the essential labeling information in partially labeled examples and worth being leveraged for predictive model training. Motivated by this consideration, we propose a novel PLL method that recovers the label distribution as a label enhancement (LE) process and trains the predictive model iteratively in every epoch. Specifically, we assume the true posterior density of the latent label distribution takes on the variational approximate Dirichlet density parameterized by an inference model. Then the evidence lower bound is deduced for optimizing the inference model and the label distributions generated from the variational posterior are utilized for training the predictive model. Experiments on benchmark and real-world datasets validate the effectiveness of the proposed method. Source code is available at https://github.com/palm-ml/valen.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020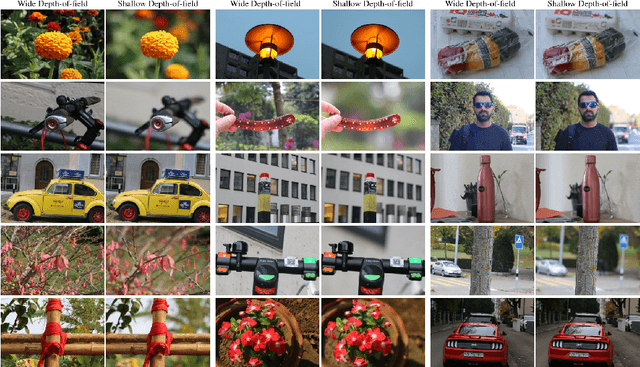


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
BGGAN: Bokeh-Glass Generative Adversarial Network for Rendering Realistic Bokeh
Nov 04, 2020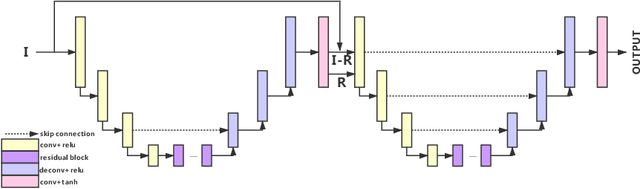
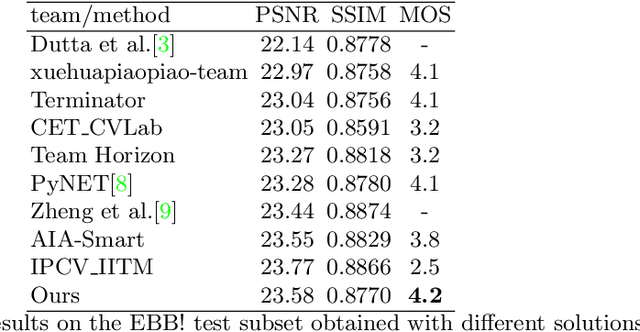
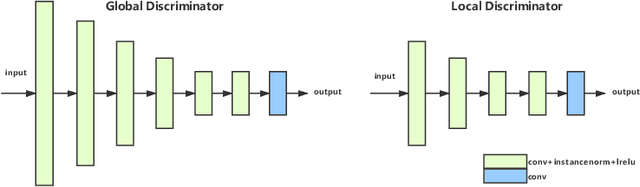
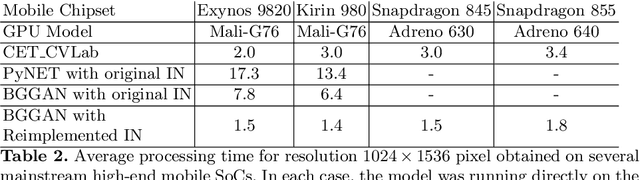
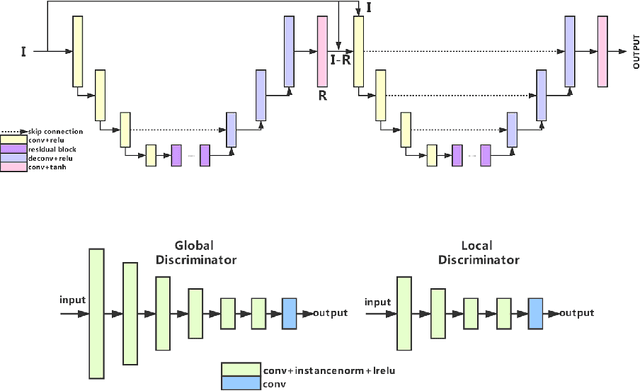
A photo captured with bokeh effect often means objects in focus are sharp while the out-of-focus areas are all blurred. DSLR can easily render this kind of effect naturally. However, due to the limitation of sensors, smartphones cannot capture images with depth-of-field effects directly. In this paper, we propose a novel generator called Glass-Net, which generates bokeh images not relying on complex hardware. Meanwhile, the GAN-based method and perceptual loss are combined for rendering a realistic bokeh effect in the stage of finetuning the model. Moreover, Instance Normalization(IN) is reimplemented in our network, which ensures our tflite model with IN can be accelerated on smartphone GPU. Experiments show that our method is able to render a high-quality bokeh effect and process one $1024 \times 1536$ pixel image in 1.9 seconds on all smartphone chipsets. This approach ranked First in AIM 2020 Rendering Realistic Bokeh Challenge Track 1 \& Track 2.