 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPCTransCompile: An AI Compiler Generated Dataset for High-Performance CUDA Transpilation and LLM Preliminary Exploration
Jun 12, 2025The rapid growth of deep learning has driven exponential increases in model parameters and computational demands. NVIDIA GPUs and their CUDA-based software ecosystem provide robust support for parallel computing, significantly alleviating computational bottlenecks. Meanwhile, due to the cultivation of user programming habits and the high performance of GPUs, the CUDA ecosystem has established a dominant position in the field of parallel software. This dominance requires other hardware platforms to support CUDA-based software with performance portability. However, translating CUDA code to other platforms poses significant challenges due to differences in parallel programming paradigms and hardware architectures. Existing approaches rely on language extensions, domain-specific languages (DSLs), or compilers but face limitations in workload coverage and generalizability. Moreover, these methods often incur substantial development costs. Recently, LLMs have demonstrated extraordinary potential in various vertical domains, especially in code-related tasks. However, the performance of existing LLMs in CUDA transpilation, particularly for high-performance code, remains suboptimal. The main reason for this limitation lies in the lack of high-quality training datasets. To address these challenges, we propose a novel framework for generating high-performance CUDA and corresponding platform code pairs, leveraging AI compiler and automatic optimization technology. We further enhance the framework with a graph-based data augmentation method and introduce HPCTransEval, a benchmark for evaluating LLM performance on CUDA transpilation. We conduct experiments using CUDA-to-CPU transpilation as a case study on leading LLMs. The result demonstrates that our framework significantly improves CUDA transpilation, highlighting the potential of LLMs to address compatibility challenges within the CUDA ecosystem.
Precise Knowledge Transfer via Flow Matching
Feb 03, 2024In this paper, we propose a novel knowledge transfer framework that introduces continuous normalizing flows for progressive knowledge transformation and leverages multi-step sampling strategies to achieve precision knowledge transfer. We name this framework Knowledge Transfer with Flow Matching (FM-KT), which can be integrated with a metric-based distillation method with any form (\textit{e.g.} vanilla KD, DKD, PKD and DIST) and a meta-encoder with any available architecture (\textit{e.g.} CNN, MLP and Transformer). By introducing stochastic interpolants, FM-KD is readily amenable to arbitrary noise schedules (\textit{e.g.}, VP-ODE, VE-ODE, Rectified flow) for normalized flow path estimation. We theoretically demonstrate that the training objective of FM-KT is equivalent to minimizing the upper bound of the teacher feature map or logit negative log-likelihood. Besides, FM-KT can be viewed as a unique implicit ensemble method that leads to performance gains. By slightly modifying the FM-KT framework, FM-KT can also be transformed into an online distillation framework OFM-KT with desirable performance gains. Through extensive experiments on CIFAR-100, ImageNet-1k, and MS-COCO datasets, we empirically validate the scalability and state-of-the-art performance of our proposed methods among relevant comparison approaches.
Catch-Up Distillation: You Only Need to Train Once for Accelerating Sampling
May 21, 2023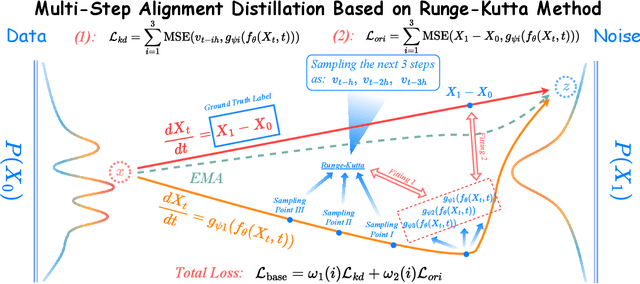


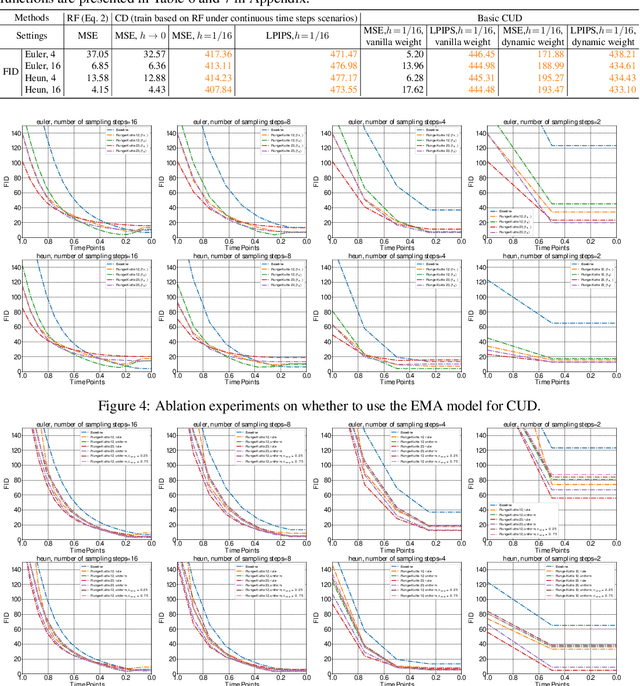
Diffusion Probability Models (DPMs) have made impressive advancements in various machine learning domains. However, achieving high-quality synthetic samples typically involves performing a large number of sampling steps, which impedes the possibility of real-time sample synthesis. Traditional accelerated sampling algorithms via knowledge distillation rely on pre-trained model weights and discrete time step scenarios, necessitating additional training sessions to achieve their goals. To address these issues, we propose the Catch-Up Distillation (CUD), which encourages the current moment output of the velocity estimation model ``catch up'' with its previous moment output. Specifically, CUD adjusts the original Ordinary Differential Equation (ODE) training objective to align the current moment output with both the ground truth label and the previous moment output, utilizing Runge-Kutta-based multi-step alignment distillation for precise ODE estimation while preventing asynchronous updates. Furthermore, we investigate the design space for CUDs under continuous time-step scenarios and analyze how to determine the suitable strategies. To demonstrate CUD's effectiveness, we conduct thorough ablation and comparison experiments on CIFAR-10, MNIST, and ImageNet-64. On CIFAR-10, we obtain a FID of 2.80 by sampling in 15 steps under one-session training and the new state-of-the-art FID of 3.37 by sampling in one step with additional training. This latter result necessitated only 62w iterations with a batch size of 128, in contrast to Consistency Distillation, which demanded 210w iterations with a larger batch size of 256. Our code is released at https://anonymous.4open.science/r/Catch-Up-Distillation-E31F.