 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatch-Up Distillation: You Only Need to Train Once for Accelerating Sampling
Paper and Code
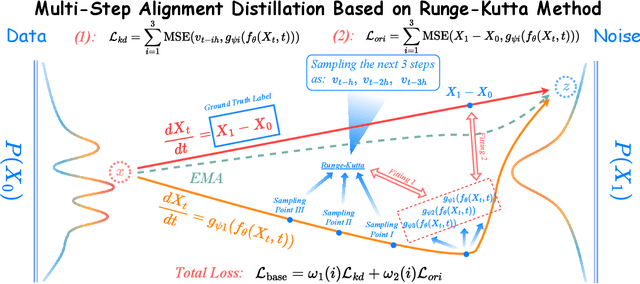


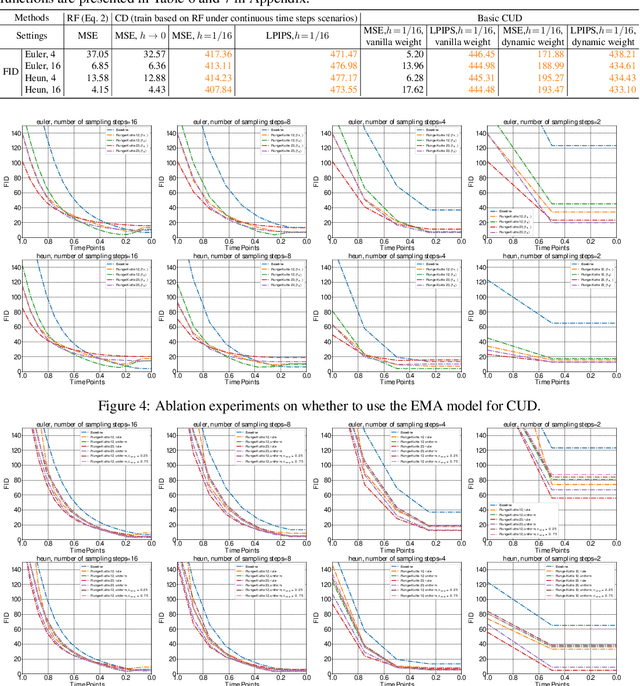
Diffusion Probability Models (DPMs) have made impressive advancements in various machine learning domains. However, achieving high-quality synthetic samples typically involves performing a large number of sampling steps, which impedes the possibility of real-time sample synthesis. Traditional accelerated sampling algorithms via knowledge distillation rely on pre-trained model weights and discrete time step scenarios, necessitating additional training sessions to achieve their goals. To address these issues, we propose the Catch-Up Distillation (CUD), which encourages the current moment output of the velocity estimation model ``catch up'' with its previous moment output. Specifically, CUD adjusts the original Ordinary Differential Equation (ODE) training objective to align the current moment output with both the ground truth label and the previous moment output, utilizing Runge-Kutta-based multi-step alignment distillation for precise ODE estimation while preventing asynchronous updates. Furthermore, we investigate the design space for CUDs under continuous time-step scenarios and analyze how to determine the suitable strategies. To demonstrate CUD's effectiveness, we conduct thorough ablation and comparison experiments on CIFAR-10, MNIST, and ImageNet-64. On CIFAR-10, we obtain a FID of 2.80 by sampling in 15 steps under one-session training and the new state-of-the-art FID of 3.37 by sampling in one step with additional training. This latter result necessitated only 62w iterations with a batch size of 128, in contrast to Consistency Distillation, which demanded 210w iterations with a larger batch size of 256. Our code is released at https://anonymous.4open.science/r/Catch-Up-Distillation-E31F.