 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSDF: Plane Geometry Diagram Synthesis via Signed Distance Field
Jun 16, 2025Plane Geometry Diagram Synthesis has been a crucial task in computer graphics, with applications ranging from educational tools to AI-driven mathematical reasoning. Traditionally, we rely on computer tools (e.g., Matplotlib and GeoGebra) to manually generate precise diagrams, but it usually requires huge, complicated calculations cost. Recently, researchers start to work on learning-based methods (e.g., Stable Diffusion and GPT4) to automatically generate diagrams, saving operational cost but usually suffering from limited realism and insufficient accuracy. In this paper, we propose a novel framework GeoSDF to automatically generate diagrams efficiently and accurately with Signed Distance Field (SDF). Specifically, we first represent geometric elements in the SDF, then construct a series of constraint functions to represent geometric relationships, next we optimize such constraint functions to get an optimized field of both elements and constraints, finally by rendering the optimized field, we can obtain the synthesized diagram. In our GeoSDF, we define a symbolic language to easily represent geometric elements and those constraints, and our synthesized geometry diagrams can be self-verified in the SDF, ensuring both mathematical accuracy and visual plausibility. In experiments, our GeoSDF synthesized both normal high-school level and IMO-level geometry diagrams. Through both qualitative and quantitative analysis, we can see that synthesized diagrams are realistic and accurate, and our synthesizing process is simple and efficient. Furthermore, we obtain a very high accuracy of solving geometry problems (over 95\% while the current SOTA accuracy is around 75%) by leveraging our self-verification property. All of these demonstrate the advantage of GeoSDF, paving the way for more sophisticated, accurate, and flexible generation of geometric diagrams for a wide array of applications.
DvD: Unleashing a Generative Paradigm for Document Dewarping via Coordinates-based Diffusion Model
May 28, 2025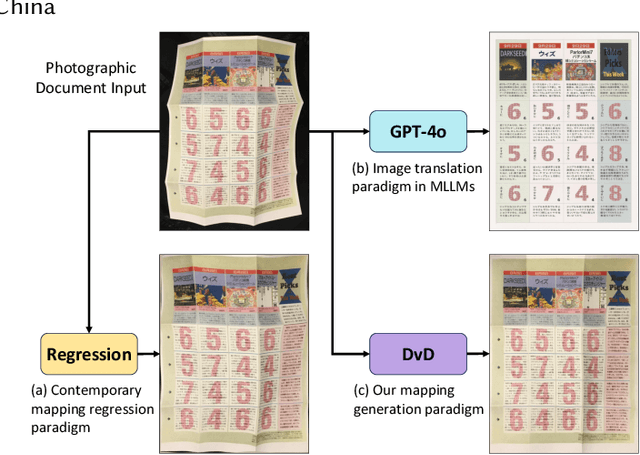
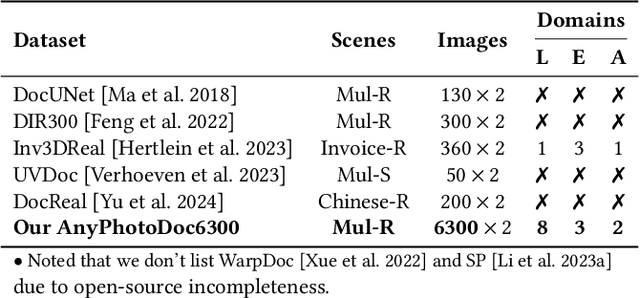
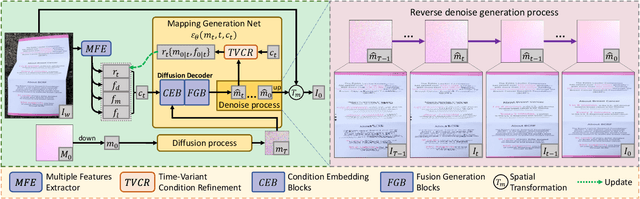
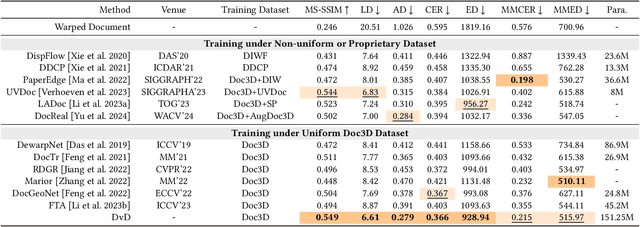
Document dewarping aims to rectify deformations in photographic document images, thus improving text readability, which has attracted much attention and made great progress, but it is still challenging to preserve document structures. Given recent advances in diffusion models, it is natural for us to consider their potential applicability to document dewarping. However, it is far from straightforward to adopt diffusion models in document dewarping due to their unfaithful control on highly complex document images (e.g., 2000$\times$3000 resolution). In this paper, we propose DvD, the first generative model to tackle document \textbf{D}ewarping \textbf{v}ia a \textbf{D}iffusion framework. To be specific, DvD introduces a coordinate-level denoising instead of typical pixel-level denoising, generating a mapping for deformation rectification. In addition, we further propose a time-variant condition refinement mechanism to enhance the preservation of document structures. In experiments, we find that current document dewarping benchmarks can not evaluate dewarping models comprehensively. To this end, we present AnyPhotoDoc6300, a rigorously designed large-scale document dewarping benchmark comprising 6,300 real image pairs across three distinct domains, enabling fine-grained evaluation of dewarping models. Comprehensive experiments demonstrate that our proposed DvD can achieve state-of-the-art performance with acceptable computational efficiency on multiple metrics across various benchmarks including DocUNet, DIR300, and AnyPhotoDoc6300. The new benchmark and code will be publicly available.
Is Your Model Really A Good Math Reasoner? Evaluating Mathematical Reasoning with Checklist
Jul 11, 2024



Exceptional mathematical reasoning ability is one of the key features that demonstrate the power of large language models (LLMs). How to comprehensively define and evaluate the mathematical abilities of LLMs, and even reflect the user experience in real-world scenarios, has emerged as a critical issue. Current benchmarks predominantly concentrate on problem-solving capabilities, which presents a substantial risk of model overfitting and fails to accurately represent genuine mathematical reasoning abilities. In this paper, we argue that if a model really understands a problem, it should be robustly and readily applied across a diverse array of tasks. Motivated by this, we introduce MATHCHECK, a well-designed checklist for testing task generalization and reasoning robustness, as well as an automatic tool to generate checklists efficiently. MATHCHECK includes multiple mathematical reasoning tasks and robustness test types to facilitate a comprehensive evaluation of both mathematical reasoning ability and behavior testing. Utilizing MATHCHECK, we develop MATHCHECK-GSM and MATHCHECK-GEO to assess mathematical textual reasoning and multi-modal reasoning capabilities, respectively, serving as upgraded versions of benchmarks including GSM8k, GeoQA, UniGeo, and Geometry3K. We adopt MATHCHECK-GSM and MATHCHECK-GEO to evaluate over 20 LLMs and 11 MLLMs, assessing their comprehensive mathematical reasoning abilities. Our results demonstrate that while frontier LLMs like GPT-4o continue to excel in various abilities on the checklist, many other model families exhibit a significant decline. Further experiments indicate that, compared to traditional math benchmarks, MATHCHECK better reflects true mathematical abilities and represents mathematical intelligence more linearly, thereby supporting our design. On our MATHCHECK, we can easily conduct detailed behavior analysis to deeply investigate models.
A Symbolic Character-Aware Model for Solving Geometry Problems
Aug 05, 2023



AI has made significant progress in solving math problems, but geometry problems remain challenging due to their reliance on both text and diagrams. In the text description, symbolic characters such as "$\triangle$ABC" often serve as a bridge to connect the corresponding diagram. However, by simply tokenizing symbolic characters into individual letters (e.g., 'A', 'B' and 'C'), existing works fail to study them explicitly and thus lose the semantic relationship with the diagram. In this paper, we develop a symbolic character-aware model to fully explore the role of these characters in both text and diagram understanding and optimize the model under a multi-modal reasoning framework. In the text encoder, we propose merging individual symbolic characters to form one semantic unit along with geometric information from the corresponding diagram. For the diagram encoder, we pre-train it under a multi-label classification framework with the symbolic characters as labels. In addition, we enhance the geometry diagram understanding ability via a self-supervised learning method under the masked image modeling auxiliary task. By integrating the proposed model into a general encoder-decoder pipeline for solving geometry problems, we demonstrate its superiority on two benchmark datasets, including GeoQA and Geometry3K, with extensive experiments. Specifically, on GeoQA, the question-solving accuracy is increased from 60.0\% to 64.1\%, achieving a new state-of-the-art accuracy; on Geometry3K, we reduce the question average solving steps from 6.9 down to 6.0 with marginally higher solving accuracy.
Learning by Analogy: Diverse Questions Generation in Math Word Problem
Jun 15, 2023



Solving math word problem (MWP) with AI techniques has recently made great progress with the success of deep neural networks (DNN), but it is far from being solved. We argue that the ability of learning by analogy is essential for an MWP solver to better understand same problems which may typically be formulated in diverse ways. However most existing works exploit the shortcut learning to train MWP solvers simply based on samples with a single question. In lack of diverse questions, these methods merely learn shallow heuristics. In this paper, we make a first attempt to solve MWPs by generating diverse yet consistent questions/equations. Given a typical MWP including the scenario description, question, and equation (i.e., answer), we first generate multiple consistent equations via a group of heuristic rules. We then feed them to a question generator together with the scenario to obtain the corresponding diverse questions, forming a new MWP with a variety of questions and equations. Finally we engage a data filter to remove those unreasonable MWPs, keeping the high-quality augmented ones. To evaluate the ability of learning by analogy for an MWP solver, we generate a new MWP dataset (called DiverseMath23K) with diverse questions by extending the current benchmark Math23K. Extensive experimental results demonstrate that our proposed method can generate high-quality diverse questions with corresponding equations, further leading to performance improvement on Diverse-Math23K. The code and dataset is available at: https://github.com/zhouzihao501/DiverseMWP