 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariance-based Space Regularization for Few-shot Class Incremental Learning
Nov 02, 2024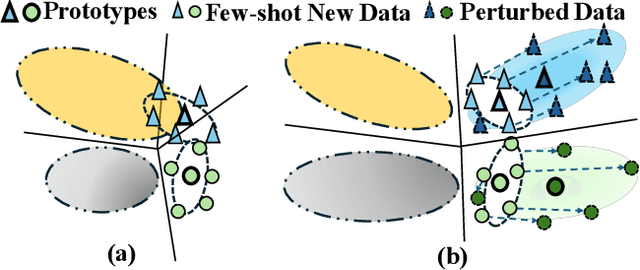
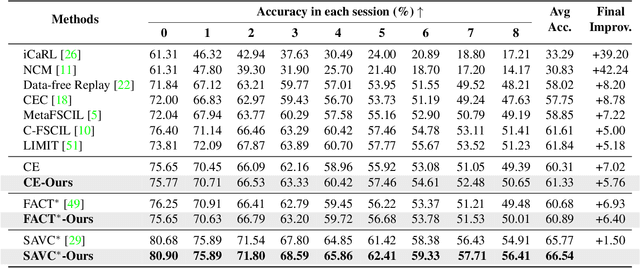
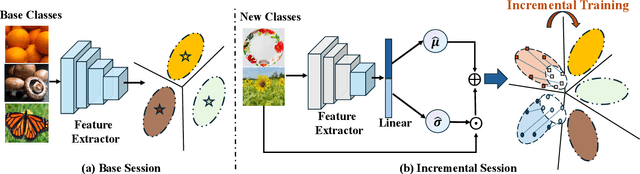
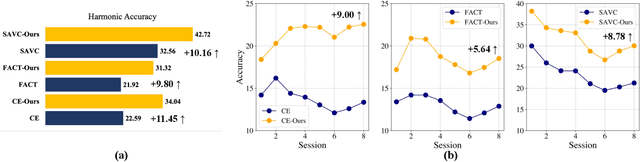
Few-shot Class Incremental Learning (FSCIL) presents a challenging yet realistic scenario, which requires the model to continually learn new classes with limited labeled data (i.e., incremental sessions) while retaining knowledge of previously learned base classes (i.e., base sessions). Due to the limited data in incremental sessions, models are prone to overfitting new classes and suffering catastrophic forgetting of base classes. To tackle these issues, recent advancements resort to prototype-based approaches to constrain the base class distribution and learn discriminative representations of new classes. Despite the progress, the limited data issue still induces ill-divided feature space, leading the model to confuse the new class with old classes or fail to facilitate good separation among new classes. In this paper, we aim to mitigate these issues by directly constraining the span of each class distribution from a covariance perspective. In detail, we propose a simple yet effective covariance constraint loss to force the model to learn each class distribution with the same covariance matrix. In addition, we propose a perturbation approach to perturb the few-shot training samples in the feature space, which encourages the samples to be away from the weighted distribution of other classes. Regarding perturbed samples as new class data, the classifier is forced to establish explicit boundaries between each new class and the existing ones. Our approach is easy to integrate into existing FSCIL approaches to boost performance. Experiments on three benchmarks validate the effectiveness of our approach, achieving a new state-of-the-art performance of FSCIL.
Diff-Oracle: Diffusion Model for Oracle Character Generation with Controllable Styles and Contents
Dec 21, 2023



Deciphering the oracle bone script plays a significant role in Chinese archaeology and philology. However, it is significantly challenging due to the scarcity of oracle character images. To overcome this issue, we propose Diff-Oracle, based on diffusion models (DMs), to generate sufficient controllable oracle characters. In contrast to most DMs that rely on text prompts, we incorporate a style encoder to control style information during the generation process. This encoder extracts style prompts from existing oracle character images, where style details are converted from a CLIP model into a text embedding format. Inspired by ControlNet, we introduce a content encoder to capture desired content information from content images, ensuring the fidelity of character glyphs. To train Diff-Oracle effectively, we propose to obtain pixel-level paired oracle character images (i.e., style and content images) by a pre-trained image-to-image translation model. Extensive qualitative and quantitative experiments conducted on two benchmark datasets, Oracle-241 and OBC306, demonstrate that our Diff-Oracle outperforms existing generative methods in terms of image generation, further enhancing recognition accuracy. Source codes will be available.
A Symbolic Character-Aware Model for Solving Geometry Problems
Aug 05, 2023



AI has made significant progress in solving math problems, but geometry problems remain challenging due to their reliance on both text and diagrams. In the text description, symbolic characters such as "$\triangle$ABC" often serve as a bridge to connect the corresponding diagram. However, by simply tokenizing symbolic characters into individual letters (e.g., 'A', 'B' and 'C'), existing works fail to study them explicitly and thus lose the semantic relationship with the diagram. In this paper, we develop a symbolic character-aware model to fully explore the role of these characters in both text and diagram understanding and optimize the model under a multi-modal reasoning framework. In the text encoder, we propose merging individual symbolic characters to form one semantic unit along with geometric information from the corresponding diagram. For the diagram encoder, we pre-train it under a multi-label classification framework with the symbolic characters as labels. In addition, we enhance the geometry diagram understanding ability via a self-supervised learning method under the masked image modeling auxiliary task. By integrating the proposed model into a general encoder-decoder pipeline for solving geometry problems, we demonstrate its superiority on two benchmark datasets, including GeoQA and Geometry3K, with extensive experiments. Specifically, on GeoQA, the question-solving accuracy is increased from 60.0\% to 64.1\%, achieving a new state-of-the-art accuracy; on Geometry3K, we reduce the question average solving steps from 6.9 down to 6.0 with marginally higher solving accuracy.
SaliencyCut: Augmenting Plausible Anomalies for Open-set Fine-Grained Anomaly Detection
Jun 14, 2023Open-set fine-grained anomaly detection is a challenging task that requires learning discriminative fine-grained features to detect anomalies that were even unseen during training. As a cheap yet effective approach, data augmentation has been widely used to create pseudo anomalies for better training of such models. Recent wisdom of augmentation methods focuses on generating random pseudo instances that may lead to a mixture of augmented instances with seen anomalies, or out of the typical range of anomalies. To address this issue, we propose a novel saliency-guided data augmentation method, SaliencyCut, to produce pseudo but more common anomalies which tend to stay in the plausible range of anomalies. Furthermore, we deploy a two-head learning strategy consisting of normal and anomaly learning heads, to learn the anomaly score of each sample. Theoretical analyses show that this mechanism offers a more tractable and tighter lower bound of the data log-likelihood. We then design a novel patch-wise residual module in the anomaly learning head to extract and assess the fine-grained anomaly features from each sample, facilitating the learning of discriminative representations of anomaly instances. Extensive experiments conducted on six real-world anomaly detection datasets demonstrate the superiority of our method to the baseline and other state-of-the-art methods under various settings.
A Survey of Robust Adversarial Training in Pattern Recognition: Fundamental, Theory, and Methodologies
Mar 26, 2022



In the last a few decades, deep neural networks have achieved remarkable success in machine learning, computer vision, and pattern recognition. Recent studies however show that neural networks (both shallow and deep) may be easily fooled by certain imperceptibly perturbed input samples called adversarial examples. Such security vulnerability has resulted in a large body of research in recent years because real-world threats could be introduced due to vast applications of neural networks. To address the robustness issue to adversarial examples particularly in pattern recognition, robust adversarial training has become one mainstream. Various ideas, methods, and applications have boomed in the field. Yet, a deep understanding of adversarial training including characteristics, interpretations, theories, and connections among different models has still remained elusive. In this paper, we present a comprehensive survey trying to offer a systematic and structured investigation on robust adversarial training in pattern recognition. We start with fundamentals including definition, notations, and properties of adversarial examples. We then introduce a unified theoretical framework for defending against adversarial samples - robust adversarial training with visualizations and interpretations on why adversarial training can lead to model robustness. Connections will be also established between adversarial training and other traditional learning theories. After that, we summarize, review, and discuss various methodologies with adversarial attack and defense/training algorithms in a structured way. Finally, we present analysis, outlook, and remarks of adversarial training.