 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Robust Adversarial Training in Pattern Recognition: Fundamental, Theory, and Methodologies
Mar 26, 2022



In the last a few decades, deep neural networks have achieved remarkable success in machine learning, computer vision, and pattern recognition. Recent studies however show that neural networks (both shallow and deep) may be easily fooled by certain imperceptibly perturbed input samples called adversarial examples. Such security vulnerability has resulted in a large body of research in recent years because real-world threats could be introduced due to vast applications of neural networks. To address the robustness issue to adversarial examples particularly in pattern recognition, robust adversarial training has become one mainstream. Various ideas, methods, and applications have boomed in the field. Yet, a deep understanding of adversarial training including characteristics, interpretations, theories, and connections among different models has still remained elusive. In this paper, we present a comprehensive survey trying to offer a systematic and structured investigation on robust adversarial training in pattern recognition. We start with fundamentals including definition, notations, and properties of adversarial examples. We then introduce a unified theoretical framework for defending against adversarial samples - robust adversarial training with visualizations and interpretations on why adversarial training can lead to model robustness. Connections will be also established between adversarial training and other traditional learning theories. After that, we summarize, review, and discuss various methodologies with adversarial attack and defense/training algorithms in a structured way. Finally, we present analysis, outlook, and remarks of adversarial training.
Improving Model Robustness with Latent Distribution Locally and Globally
Jul 08, 2021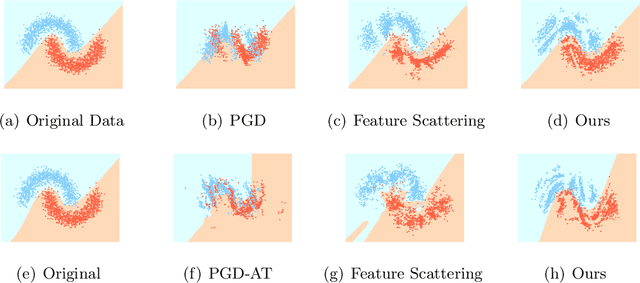
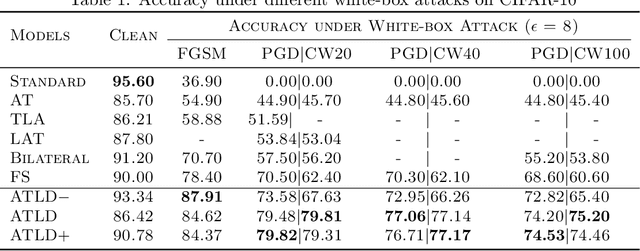
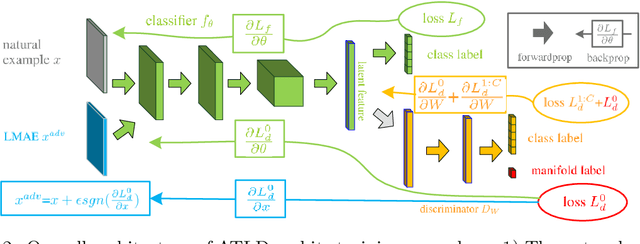
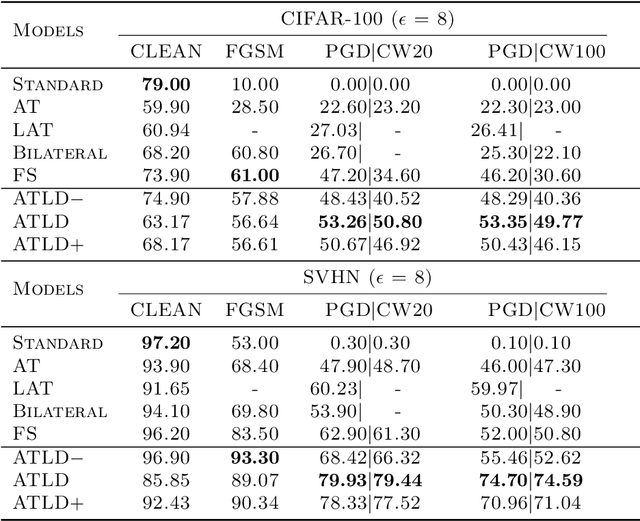
In this work, we consider model robustness of deep neural networks against adversarial attacks from a global manifold perspective. Leveraging both the local and global latent information, we propose a novel adversarial training method through robust optimization, and a tractable way to generate Latent Manifold Adversarial Examples (LMAEs) via an adversarial game between a discriminator and a classifier. The proposed adversarial training with latent distribution (ATLD) method defends against adversarial attacks by crafting LMAEs with the latent manifold in an unsupervised manner. ATLD preserves the local and global information of latent manifold and promises improved robustness against adversarial attacks. To verify the effectiveness of our proposed method, we conduct extensive experiments over different datasets (e.g., CIFAR-10, CIFAR-100, SVHN) with different adversarial attacks (e.g., PGD, CW), and show that our method substantially outperforms the state-of-the-art (e.g., Feature Scattering) in adversarial robustness by a large accuracy margin. The source codes are available at https://github.com/LitterQ/ATLD-pytorch.
Robust Generative Adversarial Network
Apr 28, 2020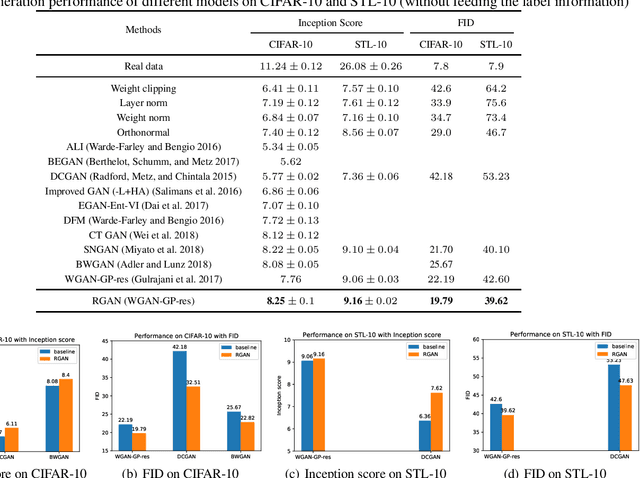
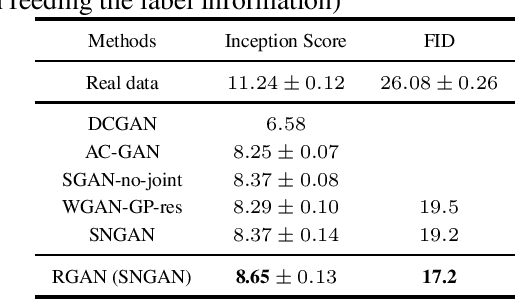
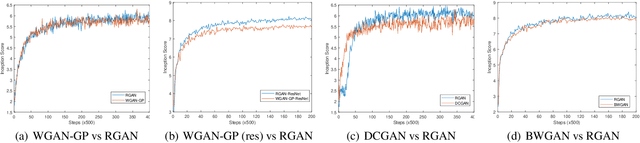
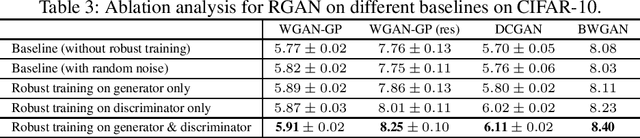
Generative adversarial networks (GANs) are powerful generative models, but usually suffer from instability and generalization problem which may lead to poor generations. Most existing works focus on stabilizing the training of the discriminator while ignoring the generalization properties. In this work, we aim to improve the generalization capability of GANs by promoting the local robustness within the small neighborhood of the training samples. We also prove that the robustness in small neighborhood of training sets can lead to better generalization. Particularly, we design a robust optimization framework where the generator and discriminator compete with each other in a \textit{worst-case} setting within a small Wasserstein ball. The generator tries to map \textit{the worst input distribution} (rather than a Gaussian distribution used in most GANs) to the real data distribution, while the discriminator attempts to distinguish the real and fake distribution \textit{with the worst perturbation}. We have proved that our robust method can obtain a tighter generalization upper bound than traditional GANs under mild assumptions, ensuring a theoretical superiority of RGAN over GANs. A series of experiments on CIFAR-10, STL-10 and CelebA datasets indicate that our proposed robust framework can improve on five baseline GAN models substantially and consistently.
Generative Adversarial Classifier for Handwriting Characters Super-Resolution
Jan 18, 2019

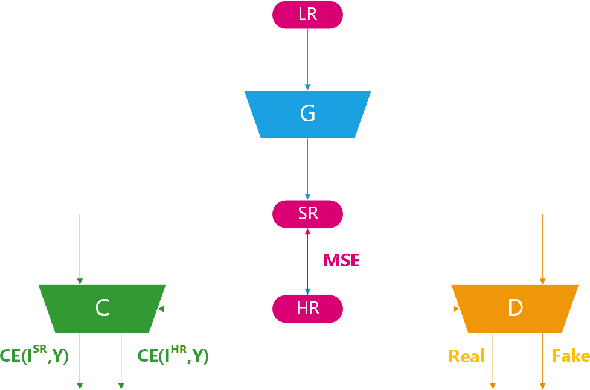

Generative Adversarial Networks (GAN) receive great attentions recently due to its excellent performance in image generation, transformation, and super-resolution. However, GAN has rarely been studied and trained for classification, leading that the generated images may not be appropriate for classification. In this paper, we propose a novel Generative Adversarial Classifier (GAC) particularly for low-resolution Handwriting Character Recognition. Specifically, involving additionally a classifier in the training process of normal GANs, GAC is calibrated for learning suitable structures and restored characters images that benefits the classification. Experimental results show that our proposed method can achieve remarkable performance in handwriting characters 8x super-resolution, approximately 10% and 20% higher than the present state-of-the-art methods respectively on benchmark data CASIA-HWDB1.1 and MNIST.